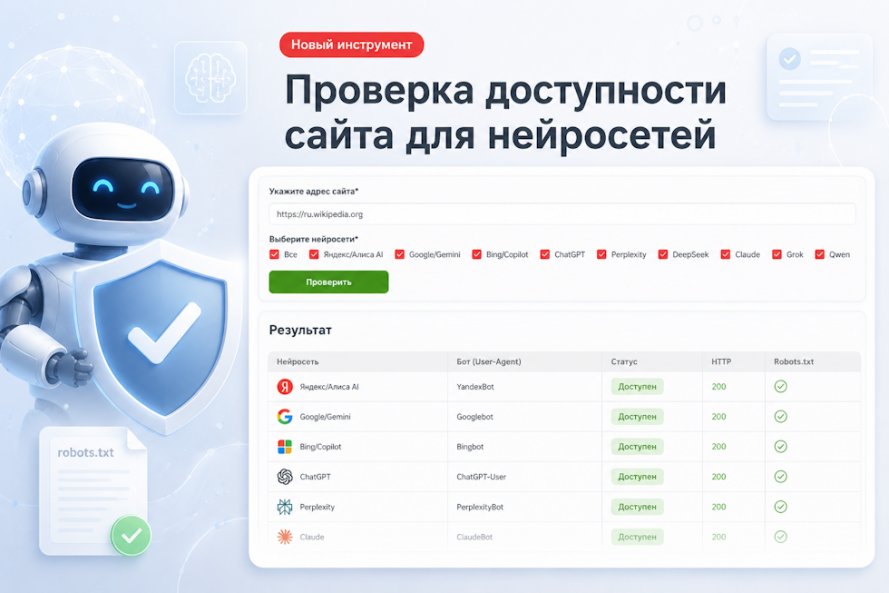
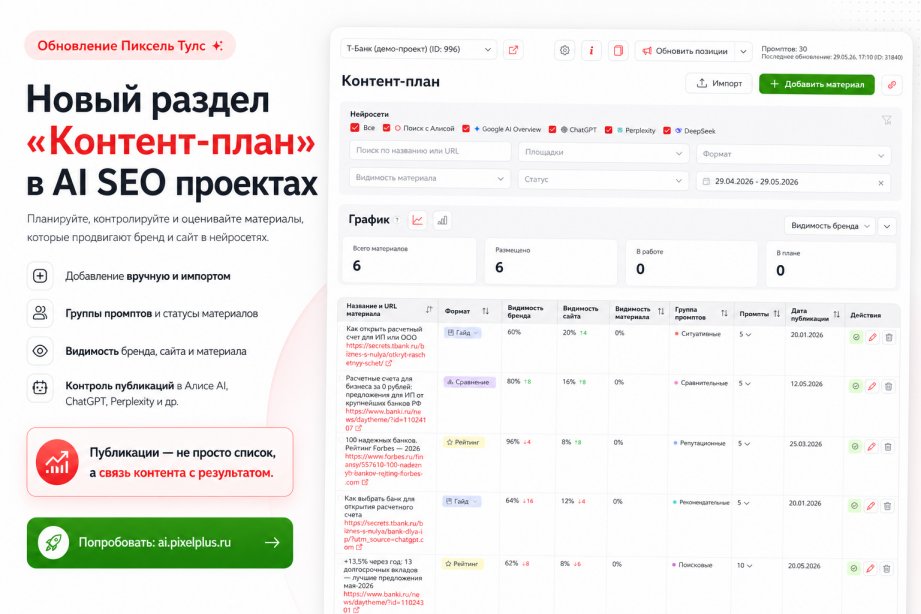
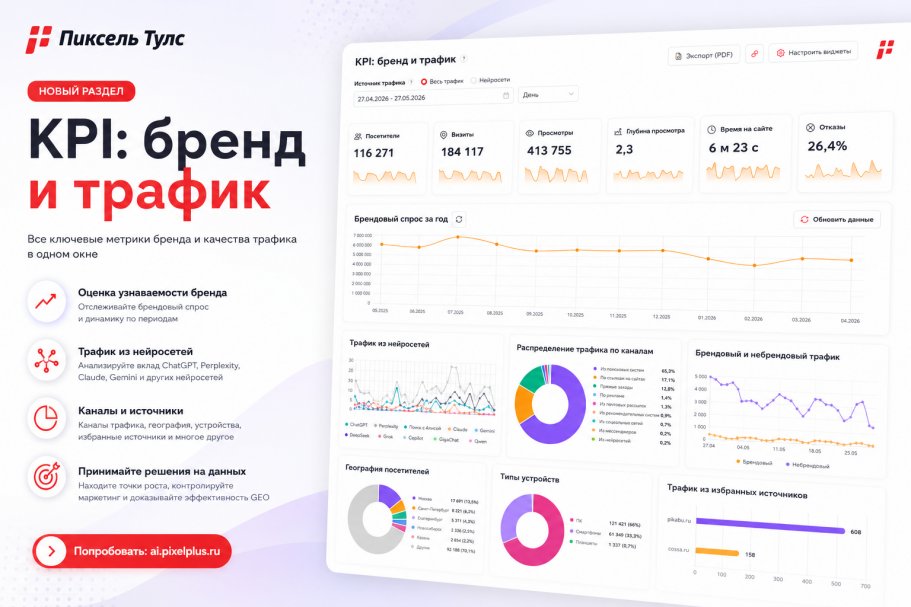
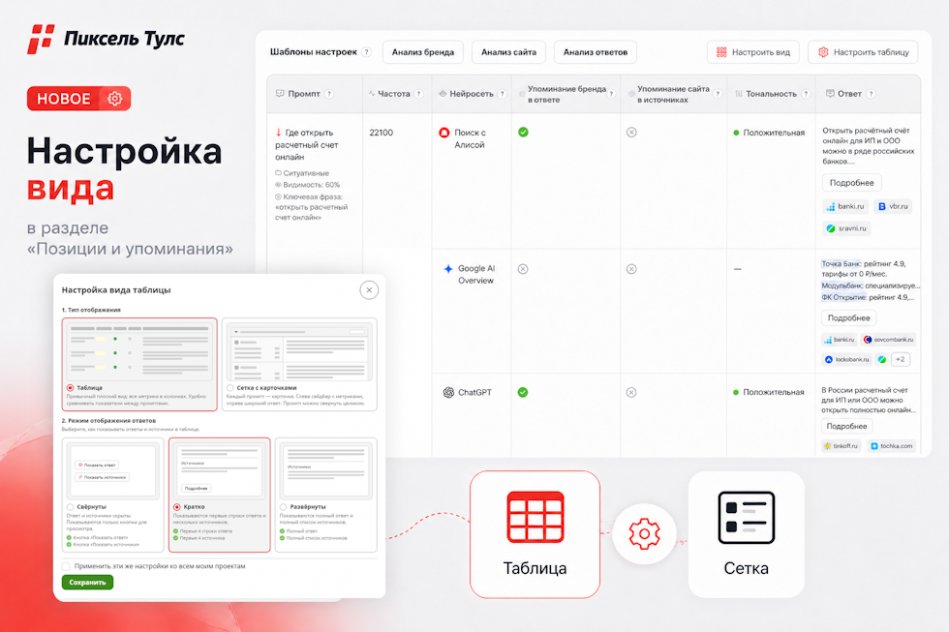
SEO-специалисты стремятся ускорить индексацию целевых страниц сайта, Google идёт на встречу, но также легко добавляет в поиск и нежелательные для нас страницы.
SearchEngineJournal опубликовали актуальные методы деиндексации, их влияние на SEO и почему меньшее количество страниц в поиске может привести к увеличению трафика. Давайте посмотрим!
Что такое «раздутый» индекс?
Index Bloat (раздутый индекс) возникает, когда в поиск попадает большее количество малополезных страниц сайта с небольшим количеством уникального контента или вовсе без него. Такие URL в индексе могут оказывать негативный каскадный эффект на SEO, примеры документов:
-
Страницы результатов фильтрации.
-
Неупорядоченные архивные страницы с неактуальным контентом.
-
Неограниченные страницы тегов.
-
Страницы с GET-параметрами.
-
Неоптимизированные страницы результатов поиска по сайту.
-
Автоматически сгенерированные страницы.
-
Трекинг-URL с метками для отслеживания.
-
http / https или www / non-www страницы без переадресации.
В чём вред? Googlebot обходит бесполезные для привлечения трафика страницы, тратит на них краулинговый бюджет и замедляет сканирование целевых URL. Повышается вероятность дублирование контента, каннибализации по запросам, релевантные страницы теряют позиции и вообще на сайте начинает царить плохо контролируемый беспорядок.
Кроме того, URL ранжируются в контексте репутации всего сайта и Google Webmaster Center недвусмысленно заявляет:
Низкокачественный контент на отдельных страницах веб-сайта может повлиять на рейтинг всего сайта, и, следовательно, удаление некачественных страниц… может помочь ранжированию высококачественного контента.
Как отслеживать количество проиндексированных страниц?
В Google Search Console на вкладке Индекс > Покрытие:
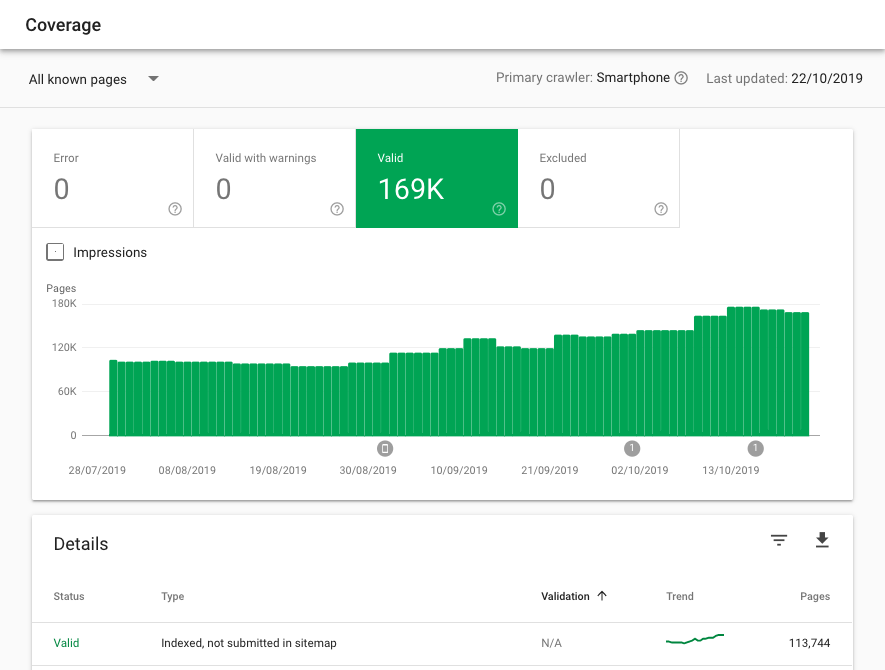
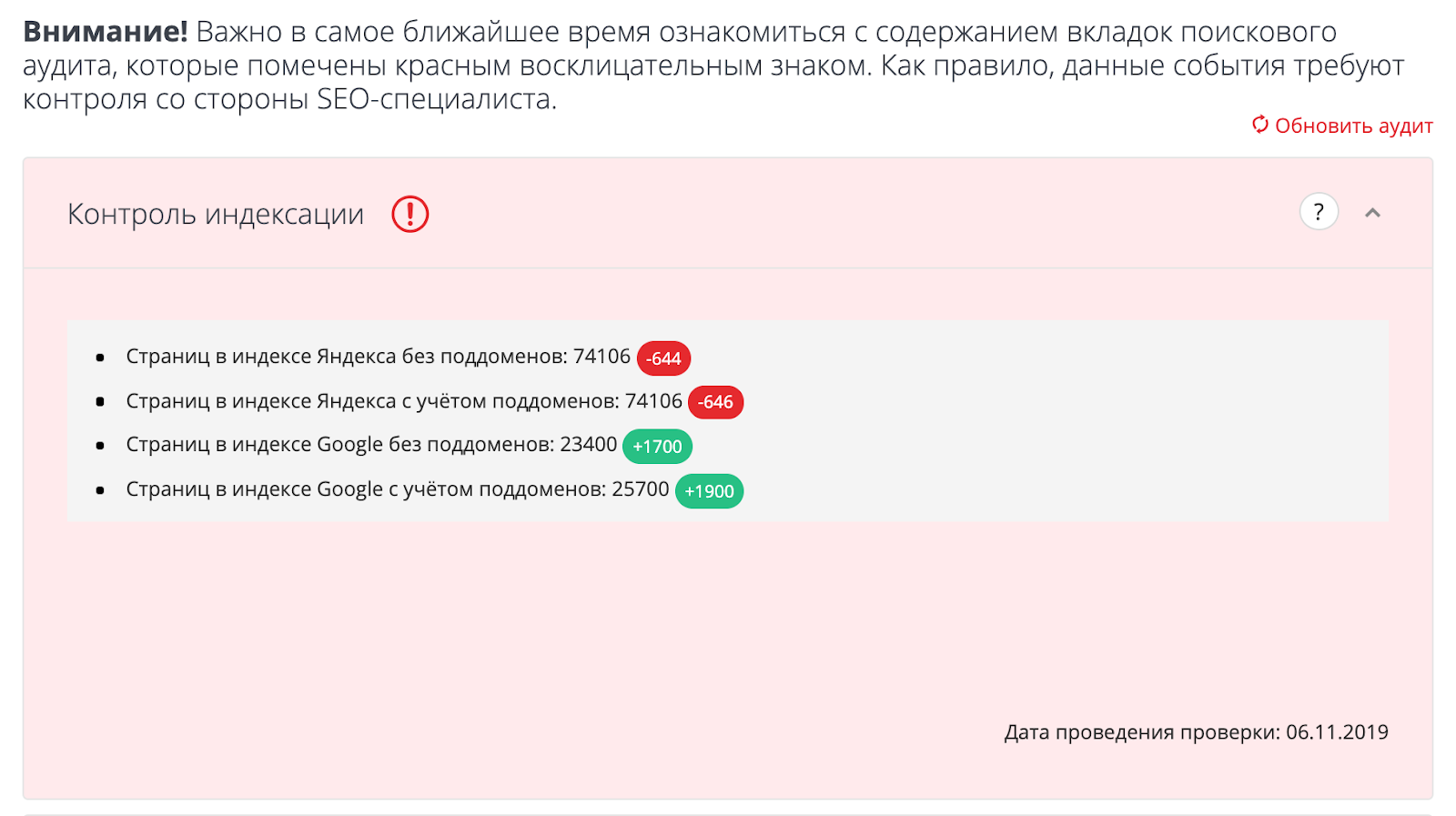
С помощью отдельных инструментов, например в «Модуле ведения проектов» на вкладке «Аудит»
Или, используя оператор site: в поиске Google (не самый надёжный и не очень точный способ):

Если количество страниц в индексе превышает число URL, которое вы хотели отдать на индексацию (скажем, из файла Sitemap.xml), вероятно имеет место проблема «раздутого» индекса и пора освежить правила запрета на сканирование.
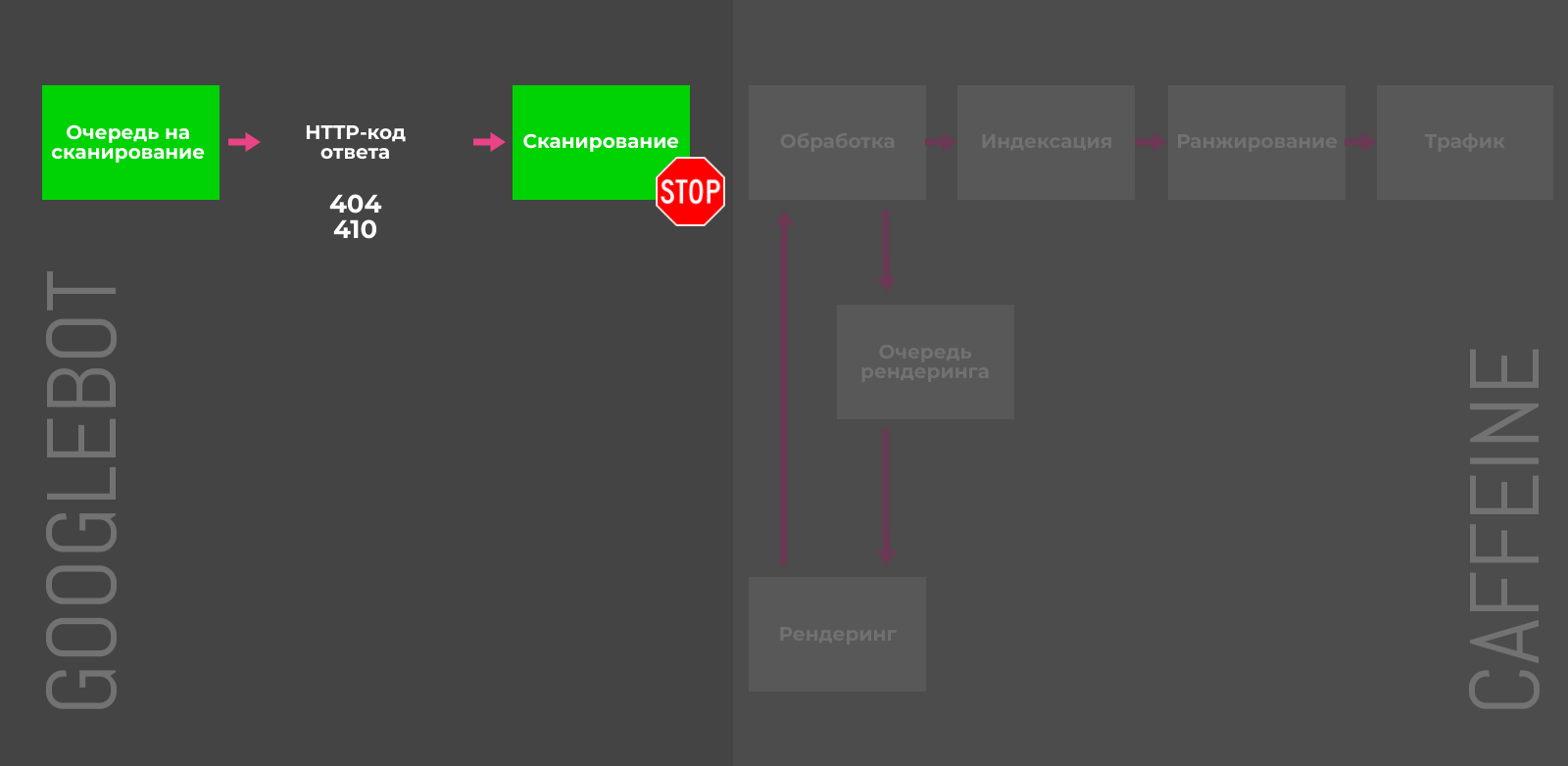
-
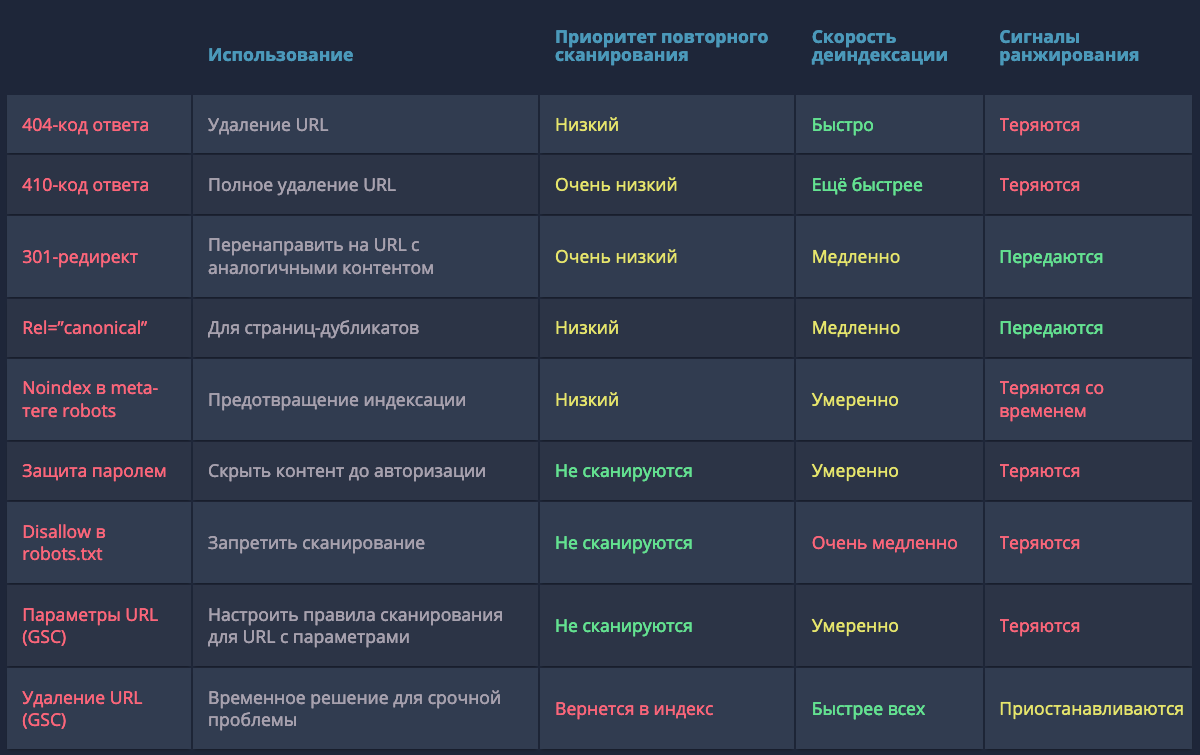
410 Gone — быстрый способ сообщить Google о том, что страница была намеренно удалена, и вы не планируете её заменить.
-
404-код ответа («страница не найдена») указывает на то, что страница может быть восстановлена, поэтому Googlebot может вернуться и проверить страницу на доступность через некоторое время.
При проверках в Search Console Google 410-код ответа помечается как 404-й. Джон Мюллер подтвердил, что это сделано с целью «упрощения», но разница всё-таки есть.
Также специалисты Google успокаивают — количество 4xx-ошибок на сайте не вредит вашему сайту. Проверить код ответа и размер документа для списка URL можно с помощью бесплатного инструмента.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 4/5
301-редирект
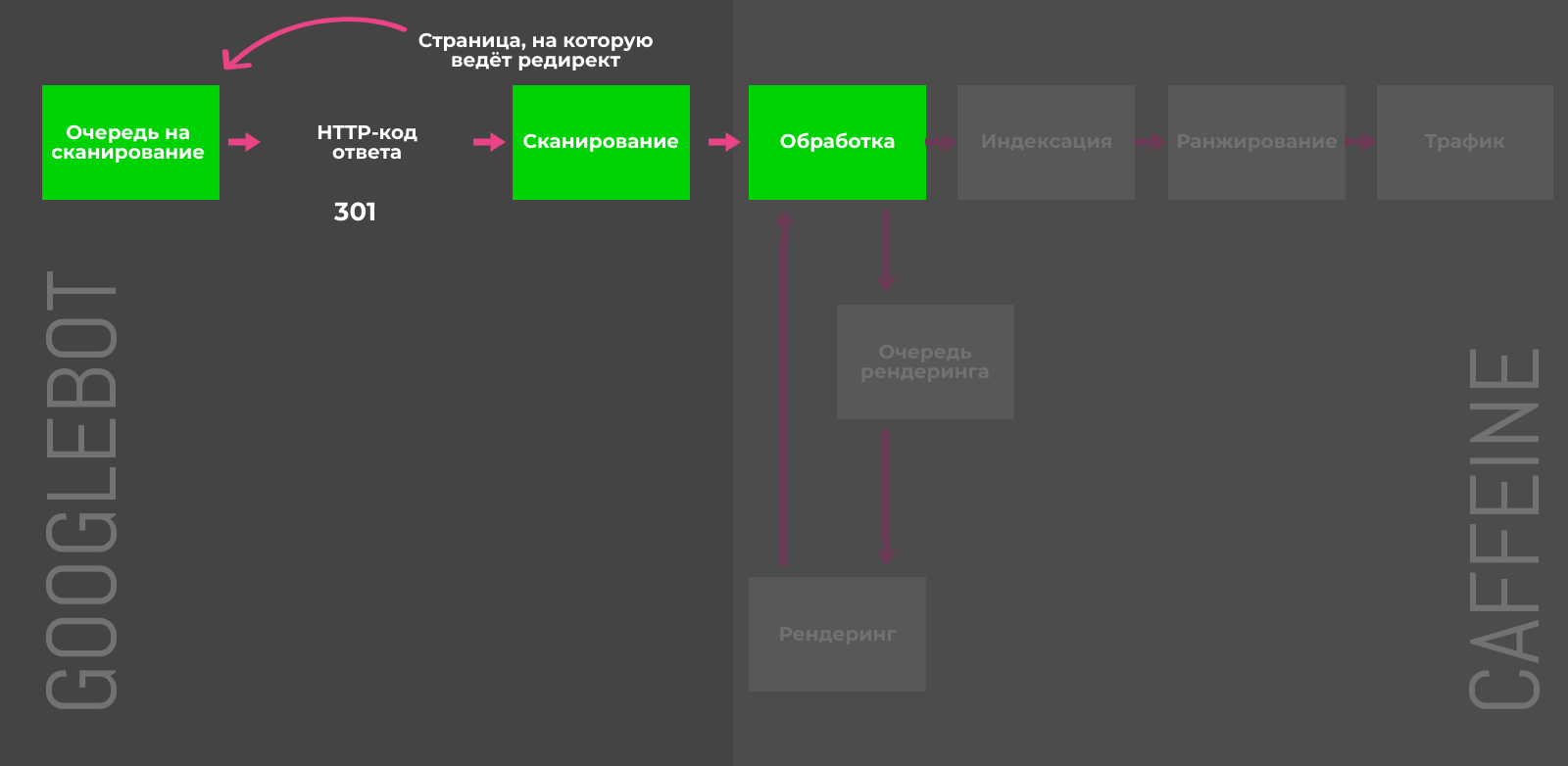
Если множество малополезных страниц можно переадресовать на целевой URL с похожим контентом и таким образом объединить их сигналы ранжирования, то 301-редирект самое верное решение. Например, в случае удалённых товаров или неактуальных новостей, можно перенаправить пользователя на схожие позиции или свежие посты по теме.
Деиндексирование перенаправляемых страниц требует времени: сначала Googlebot должен дойти до исходного URL, добавить целевой адрес в очередь для сканирования и затем обработать контент, чтобы убедиться в его тематической связи с первичным документом. В обратном случае (например, редирект на главную страницу сайта) 301-код ответа будет расцениваться Google как SOFT-404 и никаких сигналов для ранжирования (например, ссылочная масса) передано не будет.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Атрибут rel=”canonical” тега link
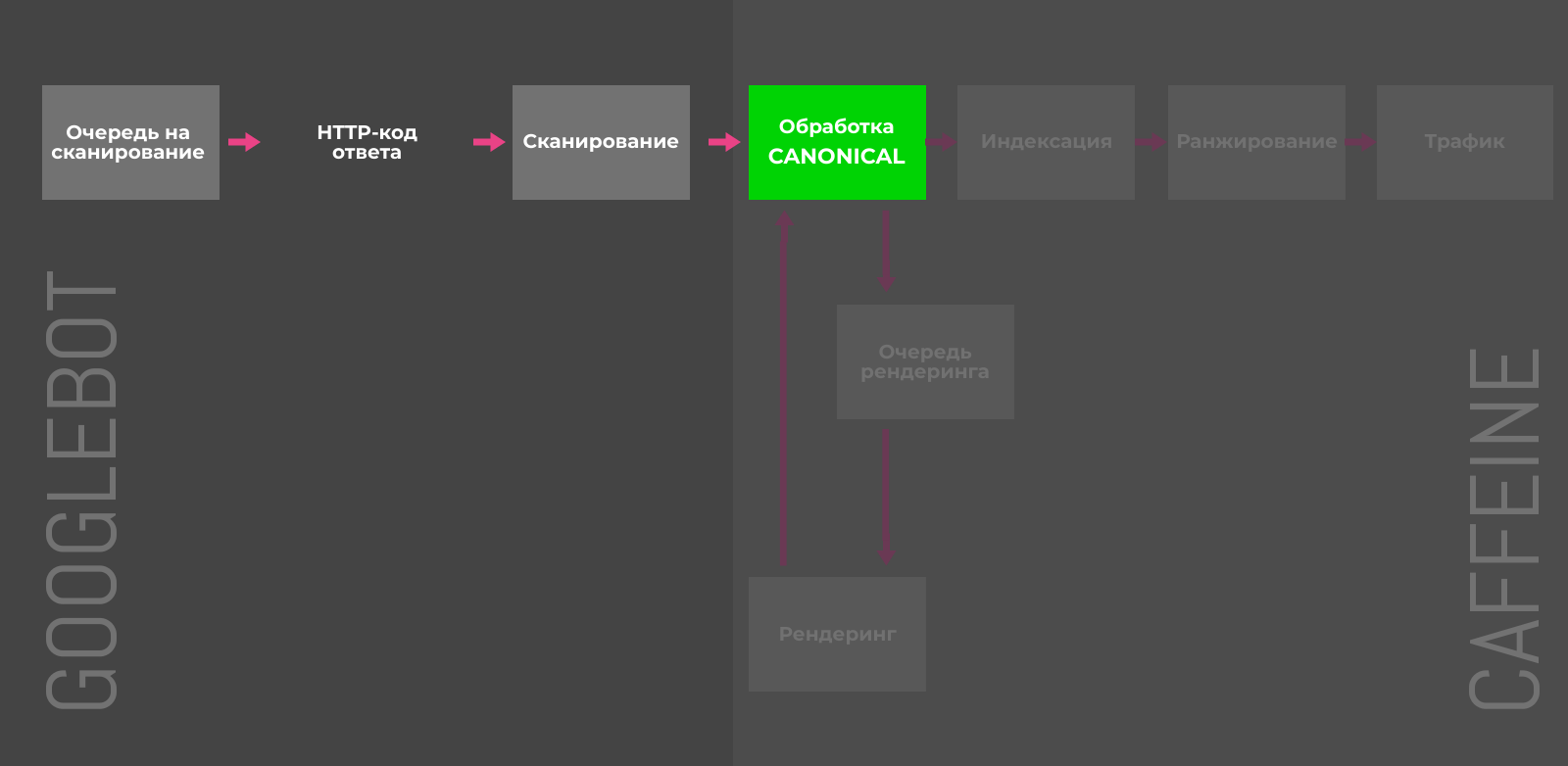
В случае дубликатов, атрибут rel=”canonical” сообщает краулеру какую именно страницу нужно индексировать. Альтернативные версии будут сканироваться, но гораздо реже и постепенно исчезнут из индекса. Чтобы учитывались и передавались сигналы ранжирования, контент на дубликатах и оригинальных страницах должен быть почти идентичным.
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 2/5
GSC-инструмент «Параметры URL»
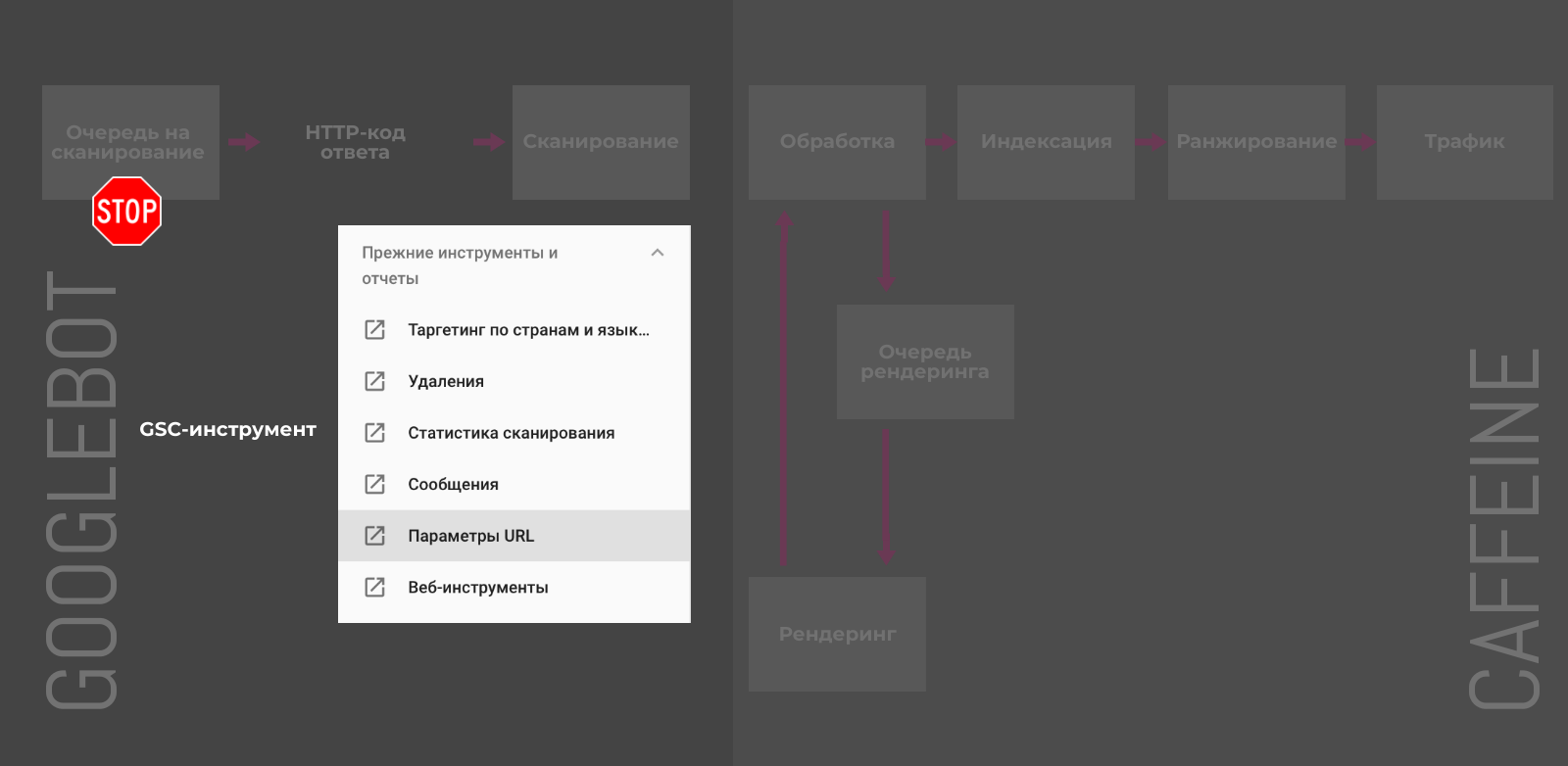
В старой версии Google Search Console можно настроить обработку и задать правила сканирования для URL с различными параметрами.
У этого способа есть несколько недостатков:
-
Работает только для URL с наличием параметров в адресе.
-
Актуально только для Googlebot и не повлияет на сканирование другими поисковыми роботами.
-
Позволяет контролировать только краулинг и не управляет индексацией напрямую.
Хотя Джон Мюллер уверяет, что в конечном счёте, попавшие под исключения, URL также будут удалены из индекса. Не самый быстрый, но также способ деиндексации.
Предотвращение «раздувания» индекса: 3/5
Борьба с последствиями «раздувания»: 1/5
Robots.txt
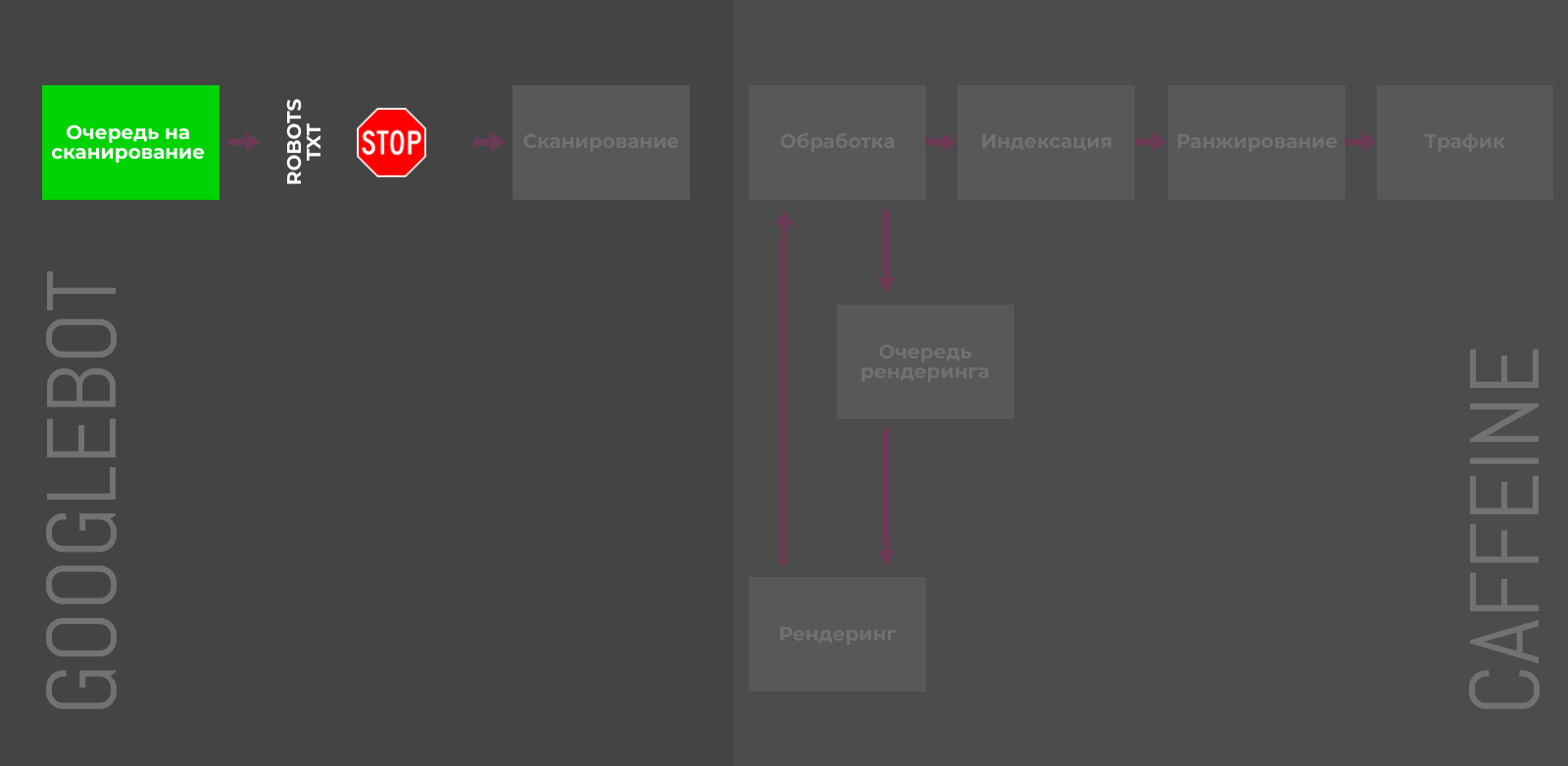
Директива Disallow в файле robots.txt позволяет блокировать отдельные страницы, разделы или полностью весь сайт. Пригодятся для закрытия служебных, временных или динамических страниц.
Тем не менее, директива не управляет индексацией напрямую, и некоторые адреса Google может отправить в индекс, если на них ссылаются сторонние ресурсы. Более того, правило не даёт четких инструкций краулерам, как поступать со страницами, которые уже попали в индексе, что замедляет процесс деиндексации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Noindex в meta-теге robots
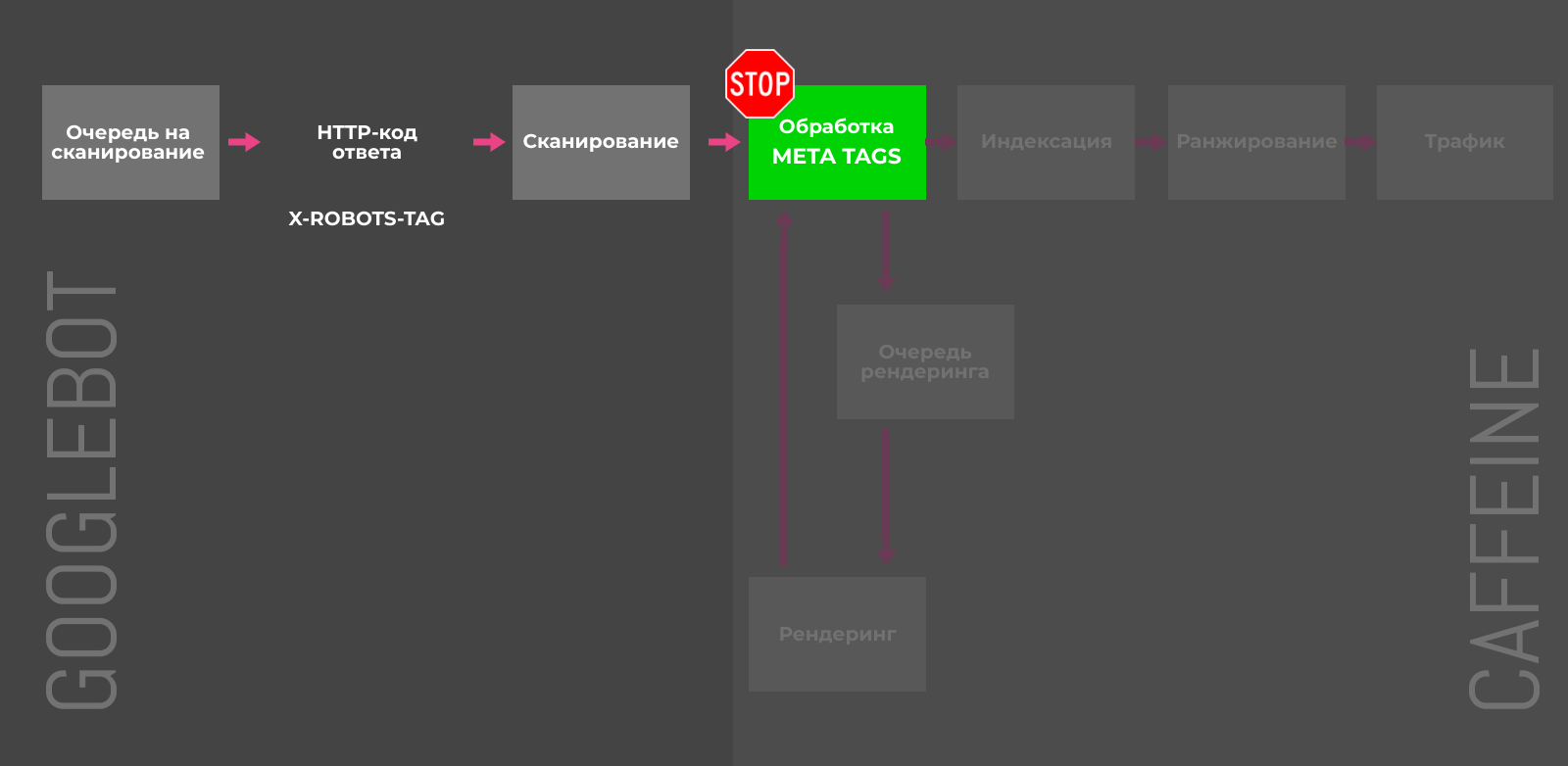
Для полной блокировки индексации отдельных страниц можно использовать мета-тег robots с атрибутом content="noindex" или HTTP-заголовок X-Robots-Tag с директивой noindex. Напомним, что noindex, прописанный в robots.txt, игнорируется поисковыми краулерами.
X-Robots-Tag и мета-тег robots на страницах имеют каскадный эффект и возможны следующие последствия:
-
Предотвращают индексацию или исключают страницу из индекса в случае добавления постфактум.
-
Сканирование таких URL будет происходить реже.
-
Любые факторы ранжирования перестают учитываться для заблокированных страниц.
-
Если параметры используются продолжительное время, ссылки на страницах обретают статус «nofollow».
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 4/5
Защита с помощью пароля / авторизации
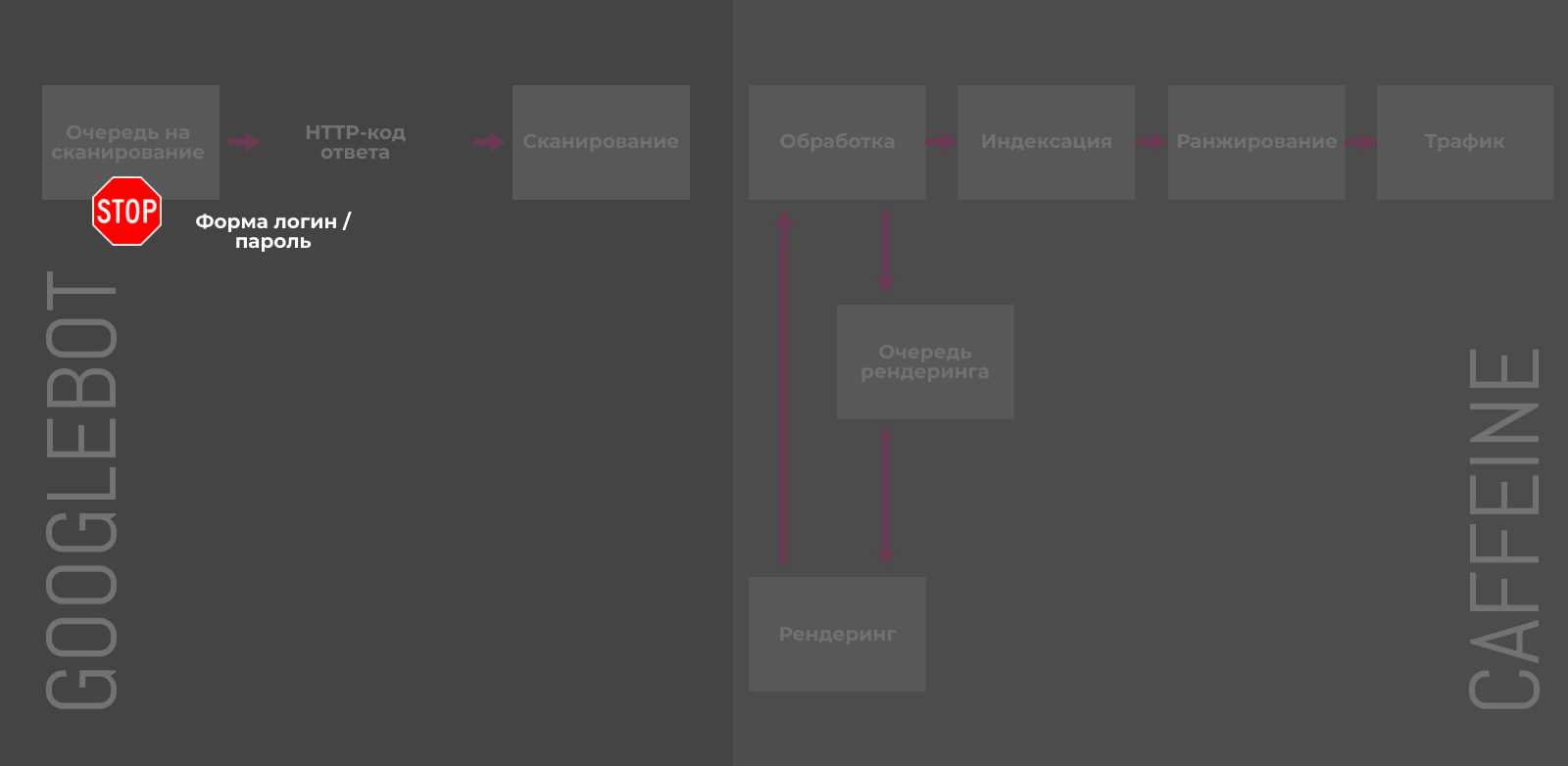
Все файлы на вашем сервере, защищенные паролем и требующие авторизации, будут недоступны для поисковых систем. Такие URL нельзя просканировать и проиндексировать. Очевидно, для пользователей контент на закрытых паролем страницах также будет недоступен до авторизации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Инструмент Google для удаления URL
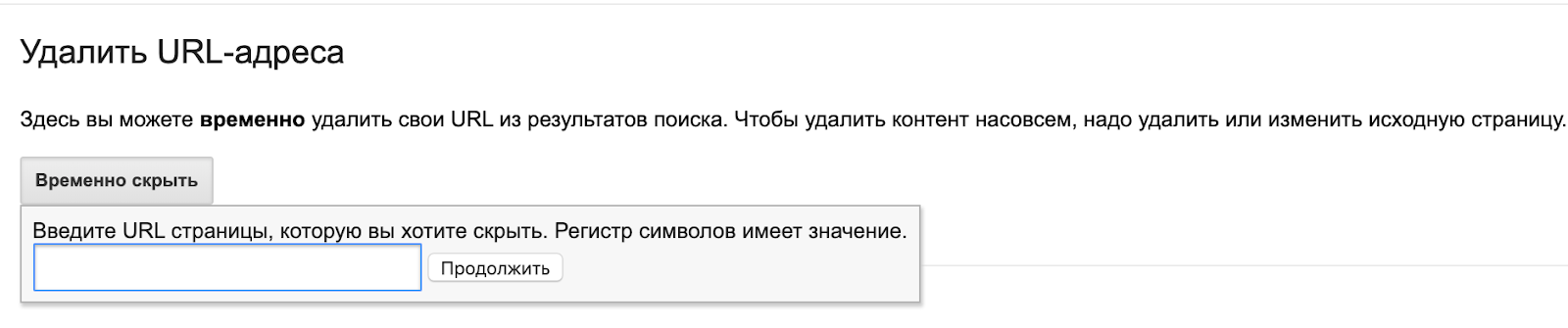
Если необходимо срочно удалить из индекса какую-либо страницу, можно использовать инструмент в старой версии Search Console. Как правило, запросы обрабатываются в день заявки. Главное, нужно понимать — это временная блокировка. По истечении 90 дней URL снова может оказаться в поисковой выдаче, если не будут применены способы для блокировки индексации, описанные выше.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Краткие выводы
Как всегда, профилактика гораздо эффективнее лечения. У Google слишком хорошая память и деиндексации может занять неприлично много времени. Всем терпения и целевых страниц в индексе!