ТЗ на SEO-текст для копирайтера: LSI, составление, проверка текста, Баден-Баден
В этом материале вы узнаете о том, что такое техническое задание на SEO-текст и как оно выглядит на текущий момент в 2020 году. Мы покажем, как можно составить грамотное ТЗ для копирайтера всего за 7 шагов. Вы научитесь делегировать эту работу, просто следуя нашей инструкции.
Содержание
Мы расскажем о том, что такое LSI, почему о нем столько говорят, и стоит ли об этом много задумываться. Кроме этого, расскажем, как проверять тексты и каким образом антиспам-алгоритмы поисковых систем Яндекса и Google могут показать нам, что не так на сайте.
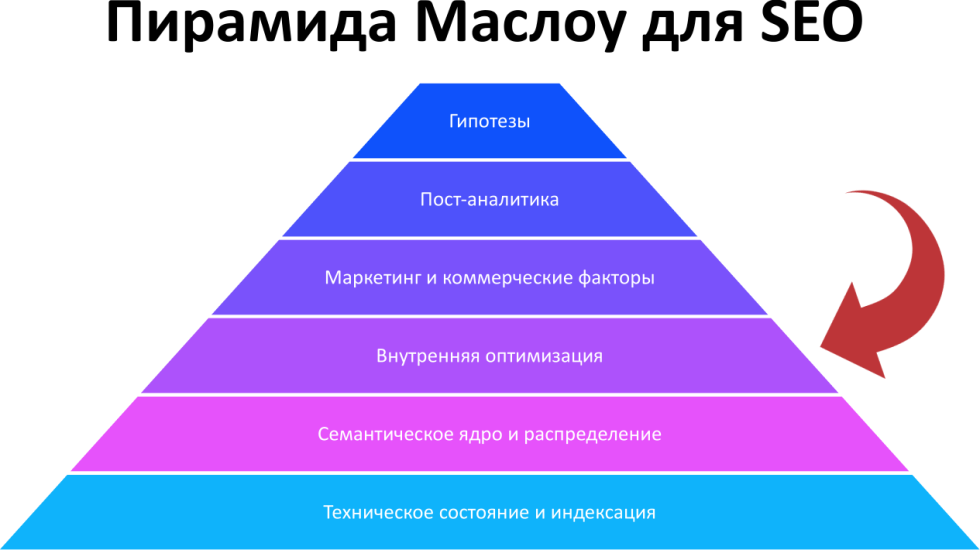
Пирамида Маслоу для SEO
О чем, с точки зрения иерархии, будем сегодня говорить? Понятно, что существует техническая индексация, семантическое ядро, внутренняя оптимизация. Именно о внутренней оптимизации и пойдет речь. Это этап, когда сайт находится уже в более или менее нормальном техническом состоянии, и у нас есть понимание, по каким запросам мы продвигаемся.
Из предыдущих материалов вы могли узнать, что очень важно приоритизировать запросы и понимать, по каким из них продвигаться в первую очередь. И как раз ручная проработка с точки зрения копирайтинга, с точки зрения формирования технического задания для копирайтера, в первую очередь важна для наиболее конкурентных запросов, по которым получается попасть в топ.
Внутренняя оптимизация и все, что касается текстовых факторов ранжирования — один из основных моментов, на которые обращают внимание поисковые системы.
Текстовые факторы ранжирования в поисковых системах
Группы текстовых факторов
Поисковые системы анализируют большое количество факторов, так или иначе связанных с текстом. Их можно условно классифицировать по пяти группам. На самом деле, таких факторов более 50. Они учитывают, каков текст с точки зрения соответствия поисковому запросу, с точки зрения его качества и так далее.
Все это можно систематизировать:
-
Есть факторы, которые касаются отдельных слов. Здесь анализируется вхождение каждого отдельного слова из поискового запроса в тексте. Применяются такие способы вычисления соответствия релевантности текста запросу, как «мешок слов», ВM25, TF IDF и другие модели. Опираясь на вхождение каждого конкретного слова, они пытаются предсказать, хорошо данный текст соответствует поисковому запросу или не очень.
-
Дальше есть определенная группа факторов, которая, так или иначе, учитывает сочетание слов. Это сочетание биграмм, учет порядка слов, удаленность текста от начала страницы и другие различные комбинации, которые учитывают не только отдельные слова, но и их сочетания.
-
Следующая группа факторов учитывает качество текста. Здесь поисковые системы оценивают, насколько текст качественный, высокая или низкая у него естественность, какое соответствие языковой модели, встречаются ли слова в нормальном тексте в такой последовательности или нет.
-
Хостовые факторы — о них мало говорят, но это важно. Большинство из того, что касается таких факторов, как спамность, уникальность и т.д. часто рассчитывается исходя из хостовых составляющих, то есть, что у вас в целом на сайте. Если у вас большинство уникальных текстов, то с большей долей вероятности следующие тексты тоже будут уникальными. Сразу скажем об уникальности — она требуется далеко не всегда. Если ваш сайт в целом содержит оригинальный контент, то в ряде случаев понятно, что не обязательно переписывать какую-то информацию от производителя (характеристики товаров, описание рецептурных свойств лекарств и т.д.).
-
Антиспам — все, что касается того, каким образом поисковая система пытается предсказать, что текст слишком переоптимизирован или выглядит неестественно, написан роботом и т.д. Здесь достаточно сложные факторы, в том числе, доля частей речи, дисперсия длин предложений и тому подобное.

Простые правила для SEO: слова
Факторов много, групп много, поисковых систем много. Что нам нужно запомнить:
-
Больше вхождений — больше релевантность (как правило). То есть, поисковая система с большей долей вероятности будет уверена, что текст именно про то, что искал пользователь в своем запросе, если там будет много слов из его запроса. С другой стороны, «поддавливает» антиспам.
-
Вхождение всех слов во все зоны документа (это такой идеальный вариант).
-
Насыщение — не нужно переспамливать больше 6-8 вхождений. Все зависит от объема текста. Если у нас одно вхождение, то у нас, условно, какое-то одно значение. Второе вхождение увеличивает значение этой функции на 50%, третье вхождение — на 20%, дальше на 11% и так далее. Очень важно, чтобы слова вообще встречались в тексте и, желательно, не один раз.
-
Ставка на слова с большим «весом». Это более редкие слова. Здесь не нужно бояться и IDF (инверсная документная частота) — это ничего запредельного, а просто попытка поисковой системы понять, насколько это слово из поискового запроса важно пользователю или нет. Предположим, если он набирает какой-нибудь «сайт выставки», то понятно, что слово «сайт» встречается на всех сайтах и на большом количестве документов в рунете. Слово «выставка» встречается на меньшем количестве сайтов и документов рунета. Поисковая система понимает, что этот вес, инверсная документная частота, у слова «выставка» выше.

Простые правила для SEO: фразы
-
Вхождение всех слов из запроса в рамках одного пассажа. Пассаж — если говорить просто, это предложение. Иногда оно немного не так бьется, но смысл такой же.
-
Точное вхождение. Если фраза «правильная» и содержит до 4-5 слов. Есть факторы, которые учитывают, что у нас вхождения точные, и они помогают поисковой системе выше ранжировать наш документ.
-
Важен порядок слов в запросе и в тексте. Желательно, чтобы он совпадал с порядком слов из запроса.
-
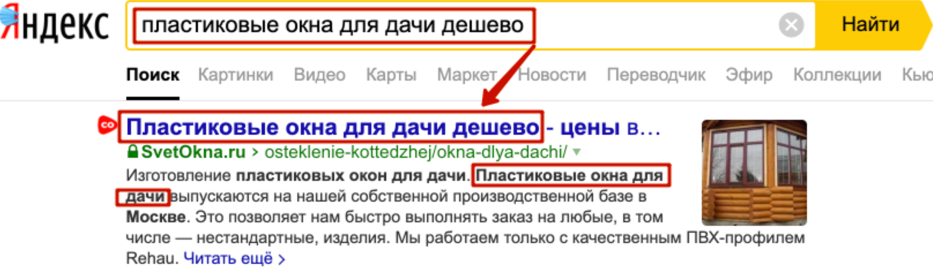
Важна позиция слов в документе относительно начала. Пример: «пластиковые окна для дачи дешево». Видим, что в топ-3 ранжируются документы, у которых прямо в тайтле так и написано, и в тексте так же написано. Это такая типовая история, когда поисковой системе было просто понять, что на этой странице действительно есть информация про тот поисковый запрос, который интересует пользователя.
Какими факторами мы управляем?
Можно назвать много текстовых факторов, но что нужно вынести в техническое задание для копирайтера?
-
Объем текста в словах и символах.
-
Поисковые системы оперируют объемом текста в словах, копирайтеры и SEO-специалисты — в символах, но этот принцип плюс-минус друг с другом переплетается. Средняя длина слова в рунете порядка 5-6 символов, поэтому в одну и в другую сторону можно пересчитать довольно быстро.
-
Процент вхождения каждого слова из запроса — можно, так или иначе, регулировать.
-
Процент вхождения синонимов и специальных терминов или тематических слов, распределение LSI-фраз.
-
Распределение ключевых фраз по тексту.
-
Вхождение фраз и их морфология (либо точное вхождение, либо фрагмент).
-
Структура и оформление документа (списки, подзаголовки, картинки и т.д.).

Это основные факторы, на которые SEO-специалисты и копирайтеры могут влиять.
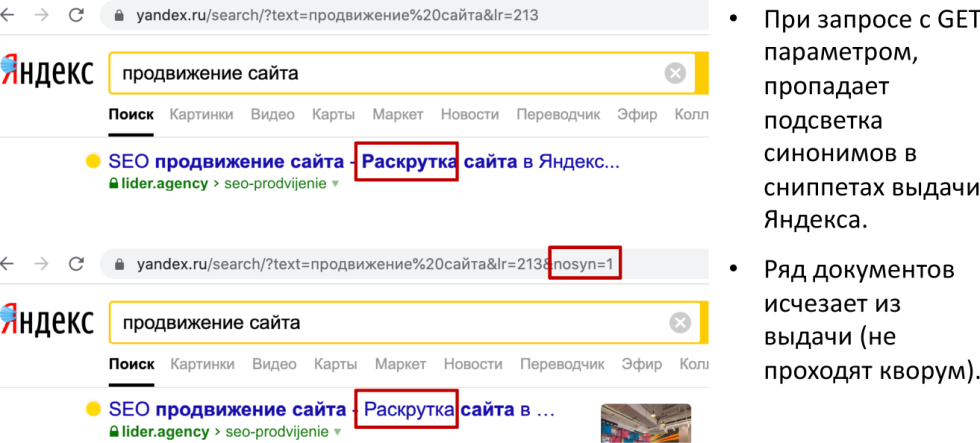
Определение синонимов: nosyn=1
Одна из маленьких «фишек» — это определение синонимов. До сих пор работает GET-параметр nosyn, который заставляет поисковую систему не подсвечивать синонимы. В частности, по запросу «продвижение сайта» в выдаче подсвечивается слово «раскрутка» и можно определить, что это именно синоним таким вот оператором в поисковой строке. Это все собирается в нашем инструменте, о котором мы сегодня говорим.
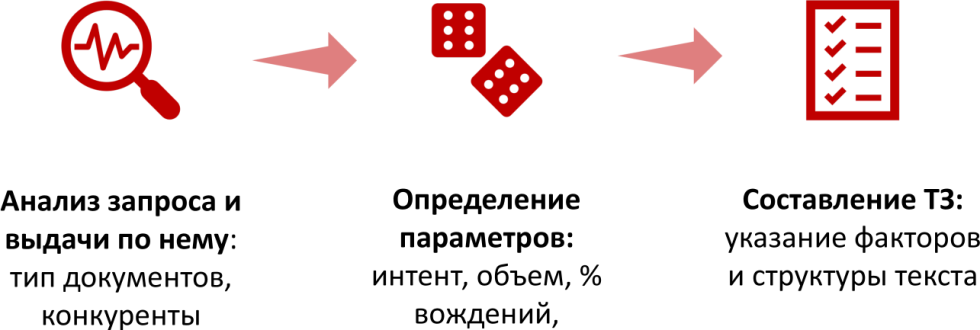
7 шагов составления ТЗ на SEO-текст: основные факторы, LSI, требования и инструменты для работы оптимизатора
Составление ТЗ на текст по шагам
Составить хорошее техническое задание на SEO-текст довольно просто. Действуем по шагам до получения нужного результата:
-
Анализ запроса и выдачи по нему (какие типы документов, какие конкуренты и т.д.).
-
Определение параметров (интент, объем, % вхождений).
-
Составление технического задания с учетом всех основных факторов, на которые мы можем воздействовать с точки зрения оптимизации.
Теперь пробежимся по шагам, используя тот бесплатный инструментарий, который у вас есть.
Шаг 1: определение конкурентов
Это промежуточный, но важный этап анализа. Вы вводите список поисковых запросов (эти поисковые запросы должны быть сгруппированы и ранжироваться в рамках одного вашего документа, который вы планируете продвигать и для которого вы составляете техническое задание копирайтеру) и получаете некий рейтинг URL-адресов, который хорошо ранжируется. Это позволяет провести конкурентный анализ и понять, какие сайты ранжируются, какой тип текста нужен, нужен ли текст вообще и так далее.
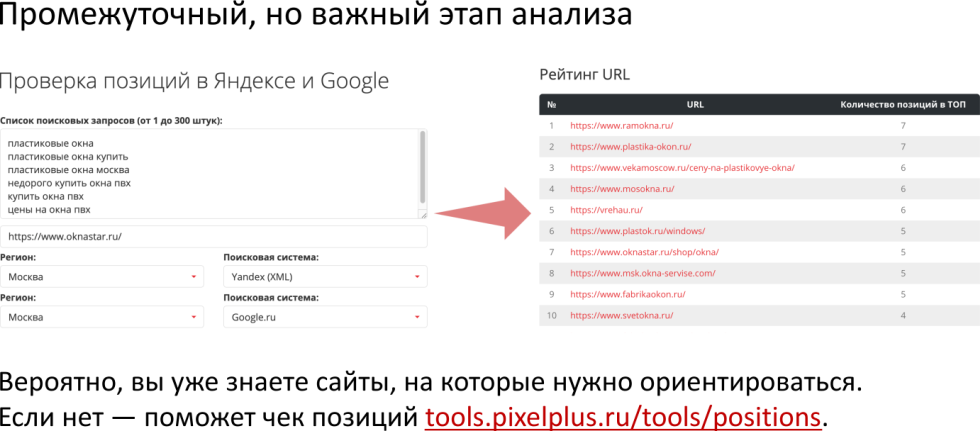
Шаг 2: выбор списка URL
Дальше мы идем в анализ топ выдачи https://tools.pixelplus.ru/tools/analiz-top и делаем анализ основной ключевой фразы (max = точная частота х показатель коммерциализации), если мы продвигаем коммерческие ресурсы. Это значит, что мы привлечем по этому поисковому запросу максимум коммерческого трафика.
По этому запросу мы выбираем URL-адреса, которые требуется анализировать с помощью инструмента анализ-топ.
Здесь есть 4 важных момента:
-
Тот же тип сайта.
Вы не должны анализировать выдачи сайтов, которые не соответствуют вам по типу. Предположим, у вас финансовый агрегатор, а в выдаче сайт банка, или наоборот, у вас какой-то сайт услуг, а в выдаче вам встретились агрегаторы.
-
Тот же тип страницы, причем, главные, внутренние и так далее, тоже желательно иметь в виду. В частности, на примере выбраны только внутренние страницы, которые при этом соответствуют по типу бизнеса.
-
Тот же размер бизнеса. Например, у Леруа Мерлен, Авито и подобных им ресурсов, как правило, вообще другие потоки трафика, другая структура поискового трафика и не всегда имеет смысл обращать на них внимание.
-
Приоритет «топовым» конкурентам из шага 1.
На эти моменты важно обращать внимание, чтобы правильно выбрать URL-адреса для анализа в https://tools.pixelplus.ru/tools/analiz-top.

Шаг 3: получение параметров текста
После этого мы получили параметры текста: желаемый объем, проценты вхождений. При этом необязательно указывать URL, который вы хотите анализировать. Можно просто оставить это поле пустым, и вы очень быстро получите то, что наиболее важно.
Это объем текста в символах, но необязательно сплошной SEO-текст, который вы должны написать. Это общий объем текстового контента на странице. Там могут быть какие-то текстовые фрагменты и так далее. Поэтому если страница у вас уже существует, то желательно ее указать. Даже если у вас текста там нет, как вам кажется, то инструмент покажет какой-то определенный объем текстового контента и вам надо будет понимать, какую дельту, какую разницу вам нужно дописывать.
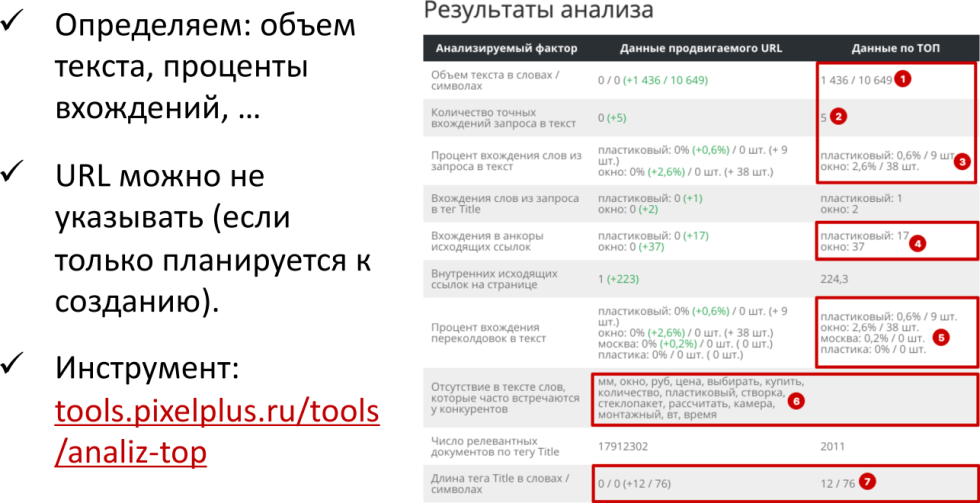
У вас окажется количество точных вхождений в текст, сколько у конкурентов. В частности, на примере: запрос «пластиковые окна» имеет 5 точных вхождений в среднем у тех конкурентов, которые были выбраны.
Есть процент вхождения ключевых фраз, то есть, сколько штук у конкурентов. На примере 9 штук в среднем, 0,6%, но здесь проще ориентироваться на штуки.
«Окно» — 38 раз, то есть видно, что плотность этой фразы 2,6%. Это довольно много, но связано с тем, что синонимов у этого слова не так уж и много, его ни на что нельзя заменить.
Под цифрой 4 у нас указан процент вхождения «переколдовок», то есть, то, как поисковый запрос переформулируется. В данном случае он переформулирован не очень сильно — слово «пластиковые» считается синонимом слову «пластик» и добавляется топоним «Москва».
И есть еще тематика, задающая слова, которые часто встречаются у конкурентов, но отсутствуют у вас. Если мы документ не указали, то это просто частотный словарь конкурентов, и тут видно, что слова «миллиметр», «окно», «рубль», «цена», «выбрать», «купить» и т.д. — это объем и дополнительные слова, которые вам нужно будет добавить.
Длина тега Title под цифрой 7 — это дополнительная история, потому что, как правило, техническое задание для копирайтера пишется в тот момент, когда мы проводим внутреннюю оптимизацию. Если она выполняется, то мы пишем еще и мета-теги.
Шаг 4: определение структуры
Этот шаг очень важный, выделяем ему время, определяем структуру нужного текста:
-
Анализируем «топовых» конкурентов (см. шаг 1).
-
Определяем структуру текстов, которая необходима для раскрытия темы.
-
Указываем нужную структуру текста в ТЗ для копирайтера.
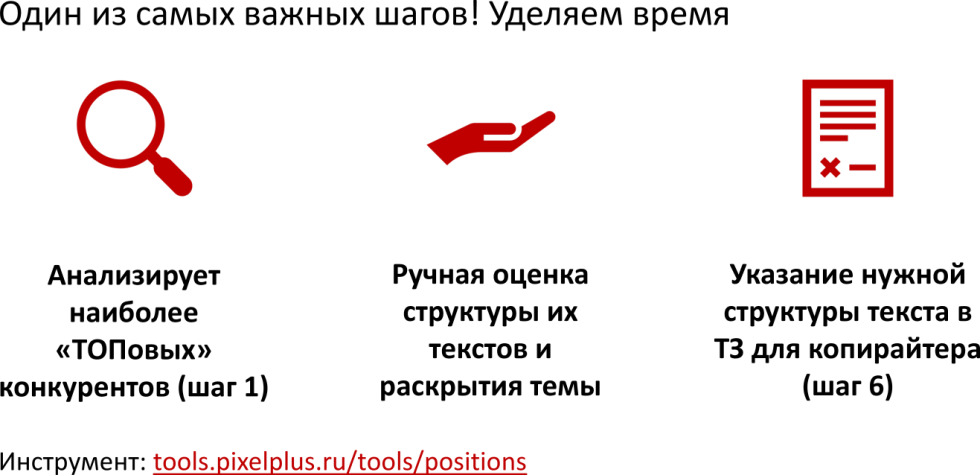
Шаг 5: LSI, синонимы и тематика
В техническое задание для копирайтера мы можем ввести список поисковых запросов. На примере под цифрой 1 у нас список поисковых запросов, которые мы продвигаем. Цифра 2 — это уникальные слова из запросов. Те, которые встречаются чаще всего, выделены и если у вас большой список (20, 30, 50 поисковых запросов), то вы должны в первую очередь обращать внимание на те слова, которые встречаются в ваших поисковых запросах много раз.
Слова из подсветки выдачи — это то, что называют синонимами. Слова, задающие тематику, часто называют LSI (латентное семантическое индексирование).

Шаг 6: формирование файла ТЗ
Ничего не придумываем, продолжаем идти по шагам. Берем:
-
объем текста из шага 3;
-
слова из запросов, которые встречаются не менее 3 раз;
-
основные синонимы и топоним.
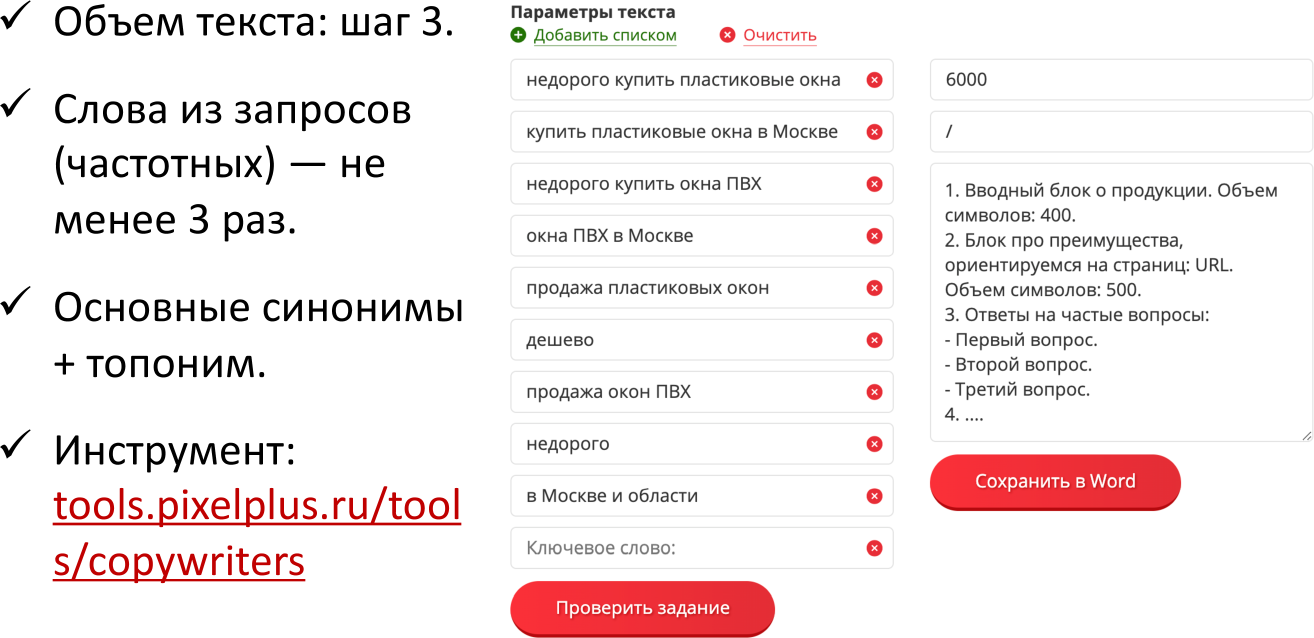
Формируем список поисковых запросов в инструменте «Техническое задание для копирайтера» https://tools.pixelplus.ru/tools/copywriters, которые будут требоваться в тексте.
На примере во второй колонке указана требуемая структура, которую мы изучили, исходя из «топовых» конкурентов. Объем текста тоже указан. Ключевые фразы (из первой колонки) мы просто вставляем так, чтобы у нас:
-
частотные слова из запросов встречались не менее 3 раз;
-
точные вхождения в наиболее популярных запросах встречались в том виде, в котором они встречаются в поисковом запросе, в том случае, если запрос можно нормально сформулировать с точки зрения русского языка.
Этот шаг наиболее важный, потому что все предыдущие шаги были во многом подготовительными. Мы определяли, какие ключевые слова нам нужны, почему они нужны и так далее.
Шаг 7: проверка файла ТЗ
Дальше на выходе мы получаем файл технического задания и должны его проверить. То есть, седьмой шаг для того, чтобы посмотреть на техническое задание для копирайтера и оценить насколько правильно мы его составили:
-
В первую очередь, надо посмотреть на то, что техническое задание выполнимо. Очень часто, учитывая требования, вписывают 50-100 ключевых фраз. Очевидно, что это в принципе невыполнимое задание. Ни один копирайтер не сможет написать такой текст, который будет при этих условиях читабельным.
-
Смотрим на то, чтобы у нас были нормальные корректные ключевые слова. Ключевые фразы, которые нам нужно употреблять в точном виде, должны быть адекватными с точки зрения русского языка.
-
У нас сочетается объем текста, объем ключевых слов и указана нормальная структура текста. То есть, нужно соблюсти некоторое сочетание объема и структуры, потому что часто указывают объем текста 700 символов и при этом структура на 5 пойнтов, и их невозможно раскрыть при таком объеме.

Это все. Дальше мы это техническое задание отправляем, а сейчас будем разбирать нюансы, особенности и вопросы, которые у нас возникают.
Бриф от клиента
Дополнительный важный момент, который нужно делать, особенно если у вас есть какой-то клиент, и вы оказываете услуги — составить бриф.
Это достаточно подробный документ. От клиента необходима информация:
-
как правильно пишется название компании, иногда это неочевидно;
-
особенности бизнеса;
-
ключевые услуги;
-
количество лет на рынке, или с какого года они существуют на рынке;
-
ценовой сегмент, в котором они существуют;
-
спецпредложения (если у них есть);
-
условия продажи и доставки;
-
целевая аудитория (пол, возраст, география, интересы и т.д.);
-
другая информация.
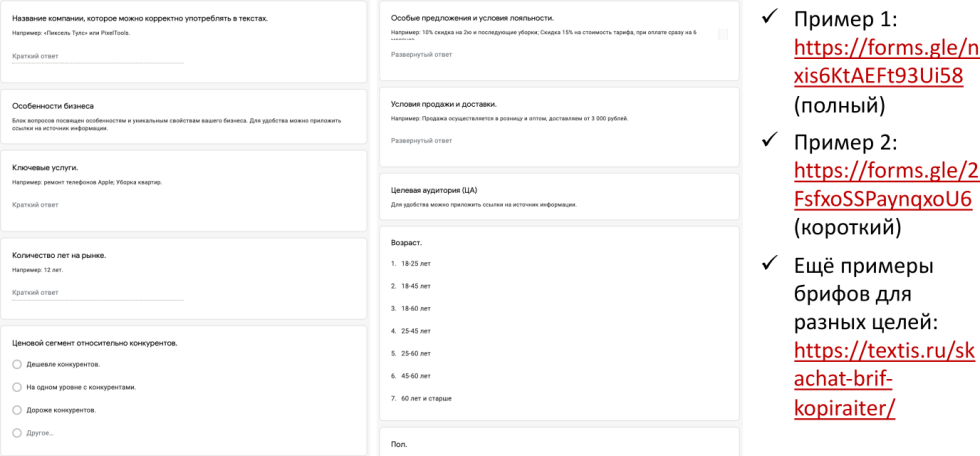
Это не все вопросы, которые есть в брифе. Вы можете сами дорабатывать документ, используя имеющиеся типовые формы. Мы рекомендуем обязательно использовать бриф. В этом случае вы ссылку на заполненный бриф от клиента вставляете в техническое задание для копирайтера, и у вас получается полноценный заказ, когда нужно не просто написать текст, а написать текст, применительно к какой-то компании. Это помогает эффективно решить задачу.
Частые ошибки в ТЗ
-
Переспам и «кривые» фразы, перебор ключевых фраз.
Сейчас поисковые системы продолжают много внимания уделять тексту, но все же вот этот классический переспам, написание больших «портянок» — оно не очень работает, если это не работает в сочетании с хорошими поведенческими факторами на странице и так далее. С большей вероятностью это приведет вас к применению санкций, нежели к тому, что документ будет очень хорошо ранжироваться. Поэтому постарайтесь в первую очередь сделать акцент на тех основных ключевых запросах, которые нужны именно вам, на тех, которые привлекут вам максимум трафика.
-
Отсутствие слов — вторая крайность, типичные качели, когда слов из запросов либо очень много, либо очень мало.
Слова из запросов в принципе в требованиях. То есть, у вас есть список из поисковых запросов, которые вы продвигаете, в нем есть 20 уникальных слов и, естественно, все эти 20 слов должны в том или ином виде встречаться в документе.
Если они не встречаются, то очевидно, что поисковая система просто не догадается о том, что данный документ соответствует данному поисковому запросу. Либо она догадается по каким-то другим критериям, но если у конкурентов будут и текстовые факторы хорошие, а у вас только запрос на индексе, или анкор-лист, или монолитный индекс, ссылки на документ будут содержать эти слова, то этого будет маловато.
-
Отсутствие продуманной структуры.
Это три типовых истории, которые, к сожалению, очень часто встречаются и нужно стараться их избегать.

Примеры критических ошибок в ТЗ
Инструмент https://tools.pixelplus.ru/tools/copywriters проверяет типовые критические ошибки в техническом задании для копирайтера.
-
Он проверяет, что у вас слова из продвигаемых поисковых запросов встречаются 3 раза. 3 раза — это такой эмпирический порог, на который можно ориентироваться, если запросов не очень много.
Если запросов и фраз очень много, либо они супернизкочастотные, микроНЧ, то 3 раза может быть и завышено даже, особенно если запрос и так у вас в топе, то возможно и не стоит его в количестве вхождений трогать.
-
Требуется упоминать топоним. Это «Москва» в случае продвижения по Москве, «Санкт-Петербург» в случае продвижения в Санкт-Петербурге. Если у вас продвигается геозависимый поисковый запрос, то смотрите что это такое в наших предыдущих материалах.
-
Превышена максимальная рекомендованная плотность ключевых фраз в ТЗ. Здесь у нас где-то 2,6%, но это тоже такая эмпирическая история. На самом деле до этого мы видели, что слово «окна» у конкурентов встречается в среднем 2,6 раз, около максимального порога, то есть здесь вы не сильно ошибетесь.
-
Превышена максимальная плотность биграмм, предположим. То есть, у вас встречаются слова «мебель купить», «мебель купить», «мебель купить», «мебель купить». Начиная с того, что так вообще не должно быть, так люди не говорят и не пишут, кончая тем, что поисковой системе будет слишком много этих вхождений и могут быть применены санкции переспама, понижение выдачи.
-
Объем текста слишком маленький для того, чтобы можно было вставить эти ключевые слова.
Это основные ошибки.

Примеры замечаний в ТЗ
Есть еще определенные замечания, которые инструмент https://tools.pixelplus.ru/tools/copywriters также подсвечивает и сигнализирует о том, что требуется использовать синонимы, требуется использовать тематические слова. Они позволяют копирайтеру лучше написать текст и лучше раскрыть тему. Необходимо использовать слова в том же виде, в котором они встречаются в запросе. То есть, если у вас только склонения, но не учтена морфология и то же вхождение, что и в поисковом запросе, это не очень хорошо.
Это все выведено на основании статистики по текстам, которые есть сейчас в рунете, с точки зрения оптимизации. Для своего проекта вы можете и должны использовать какие-то свои определенные нюансы, либо проверить работу параметрами, которые выставлены в инструменте по дефолту для вашей тематики.

Кейс: много фраз на URL
Что делать, если на URL идет 20-100 поисковых запросов? В этом случае нужно действовать в три этапа:
-
Сортируем все запросы по точной частоте и вставляем их в техническое задание для копирайтера именно исходя из той частоты либо приоритета, который мы высчитывали. До этого мы говорили о том, как приоритизировать поисковые запросы с точки зрения отдачи. В частности, точная частота, умноженная на показатель коммерциализации — это уже первый шаг к приоритизации.
-
Определяем основные ключи и делаем акцент на них. Основные — это наиболее приоритетные, слова из которых чаще встречаются в поисковых запросах. Это шаг 5 под цифрой № 2: видно, что если у нас тут будет большой список, то какие-то слова будут много раз встречаться (допустим, 20 раз), а какие-то мало. Тогда их можно не принимать во внимание.
-
Второстепенные слова и фразы, которые в принципе встречаются в поисковых запросах, но в малом количестве и не в приоритетных фразах, в общем-то, должны просто встречаться на URL-адресе. Они должны встречаться, рекомендованное дефолтное значение в ТЗ на копирайтинг — это 3.

Типовое ТЗ: низкая конкуренция
Очень часто можно упростить и выкинуть некоторые шаги, о которых мы до этого рассказывали, если с чего-то надо начать.
-
Очень часто объем текста 1000-3000 символов (условно). Можно определить какой-то типовой размер, который работает в вашем случае и его использовать.
-
Процент вхождений — типовой порог, где-то 2%.
-
Морфология — как правило, одно точное вхождение и одно второстепенное.
-
Тематические слова.
-
Слова из подсветки.
-
Минимум один список, минимум одна картинка на 1000 знаков.

На самом деле поисковые системы очень не любят в последнее время даже в информационных текстах какие-то сплошные полотна текста. Обязательно все фрагментируем. Количество текстовых фрагментов — это реально один из мощных факторов.
Мы даже смотрели корреляцию, какое количество этих маленьких текстовых фрагментов есть на странице, и чем их больше, тем, как правило, выше текст. Чем более тезисно он сформирован, тем лучше — как презентация, в которой есть какая-то мысль на слайде и вы подаете ее сжато. Она нужна посетителю, он ее получает и остальной текст его не интересует, он не будет читать всю эту «портянку».
Важнее всего, чтобы текст помогал пользователю быстрее и правильнее решить его задачу, то есть, удовлетворил его пользовательский интент. Если текст не решает этой задачи, то пользователи придут, но будут плохие значения поведенческих факторов, есть вероятность применения антиспам-санкций и так далее.
Все шаги, которые мы показали, можно использовать как некую инструкцию, чтобы делегировать кому-то, в том числе, и копирайтеру в ряде случаев. Если вы на регулярной основе сотрудничаете с копирайтером, можно дать ему этот набор инструментов.
Три инструмента, которые надо освоить: это анализ топа, ТЗ на копирайтинг и дополнительно будет еще анализ выявления топовых конкурентов (но это уже вспомогательный инструмент).
Проверка текста и регулярные корректировки
Основная проблема в том, что недостаточно один раз сделать и забыть, SEO так не работает. Нужно все время вносить какие-то корректировки.
Тексты не всегда пишутся по ТЗ
Факт состоит в том, что тексты пишут не всегда по ТЗ. Вы дали какое-то сложное ТЗ, вам прислали какой-то текст и вы думаете, что, наверное, он соответствует техническому заданию. Но это вообще не так.
Даже если дать программисту, как правило, более усидчивому человеку, техническое задание на 10 пойнтов, которые нужно реализовать, то есть вероятность, что он сделает 6. Надо проверять.

Результат: соответствие текста ТЗ
Для проверки нам нужен еще один инструмент, это оценка текста https://tools.pixelplus.ru/tools/text-natural. Там есть возможность добавить сам текст и загрузить URL-адрес и техническое задание для копирайтера, либо просто указать список поисковых фраз, которые вы хотите проверить на наличие их в тексте.
Инструмент это все проверит, покажет, например:
-
В ТЗ для копирайтера объем был указан 5000 символов, а в тексте он уменьшен на 66%. То есть, возможно, вам тарифицировали по цене за 5000 символов, но написали в два раза меньше.
-
Вхождение ключевых фраз отсутствует. То есть, в ТЗ для копирайтера есть какие-то фразы, они согласованы, в них содержатся точные вхождения наиболее приоритетных поисковых запросов и в списке ключевых фраз содержится каждое слово из продвигаемого запроса минимум 3 раза. Вхождения вроде не переспамлены, слова из тематики используются, биграммы тоже используются, то есть, текст более-менее соответствует.

Оценка и параметры текста
Какие дополнительные параметры текста также анализирует инструмент, который можно использовать? Количество слов, количество символов с пробелами и без, наиболее частотные слова, степень соответствия текста распределению Ципфа (Этот параметр говорит о том, что в естественном языке каждое первое слово встречается условно 100 раз, а следующее слово должно быть во столько раз меньше, какой у него порядок. То есть, второе слово в два раза меньше, чем первое, третье слово в три раза меньше, чем первое и так далее).
Если объем текста большой, то этот эмпирический закон более-менее выполняется. Иногда бывает полезно посмотреть на эту цифру, чтобы посмотреть, реалистичный ли текст или там переспам какими-то биграммами. Самая частая проблема, когда у нас два или три слова встречаются очень много раз и в этом случае у нас получается несоответствие.
Проценты вхождения биграмм, частей речи, сжатие текста — такая дополнительная метрика, которая позволяет оценить, насколько текст разнообразен. То есть, если вы возьмете один и тот же текст и скопируете два раза, то у него сжатие очень сильно увеличится, потому что уникальности в нем не добавилось. Это дополнительный параметр. Мы рекомендуем, чтобы нормальное значение было менее 60%.

В целом в инструменте очень много проверок и по каждой проверке есть определенные подсказки.
Реальность состоит в том, что не выполняются даже самые базовые требования, когда мы работаем с проектом. На примере — реальный проект из модуля Пиксель Тулс.

Что у нас происходит? Мы берем один конкретный URL-адрес и видим, что у нас есть список низкочастотных поисковых запросов с небольшой точной частотой — 9, 11 и т.д. Запросы при этом где-то там за соткой, двадцатые места. Мы смотрим: в тайтле нет ничего, вхождения в тексты нет, вхождений точных нет, слов из запроса нет, топонима нет, то есть, все плохо.
Поэтому, если вы выполните даже не то что 7 шагов из ТЗ на копирайтинг, а хотя бы просто два (пятый и шестой — нормально составите ключевые запросы и более-менее адекватно сформулируете техническое задание), то будет уже гораздо лучше.
Если у вас большой проект, много-много фраз, тогда кейс такой: вы заводите в модуль ведения проектов https://tools.pixelplus.ru/projects/ всю семантику, он вам проверяет, вы выгружаете и смотрите, какие URL-адреса не доработаны. Сейчас мы в этом помогаем и делаем TO DO лист по оптимизации.
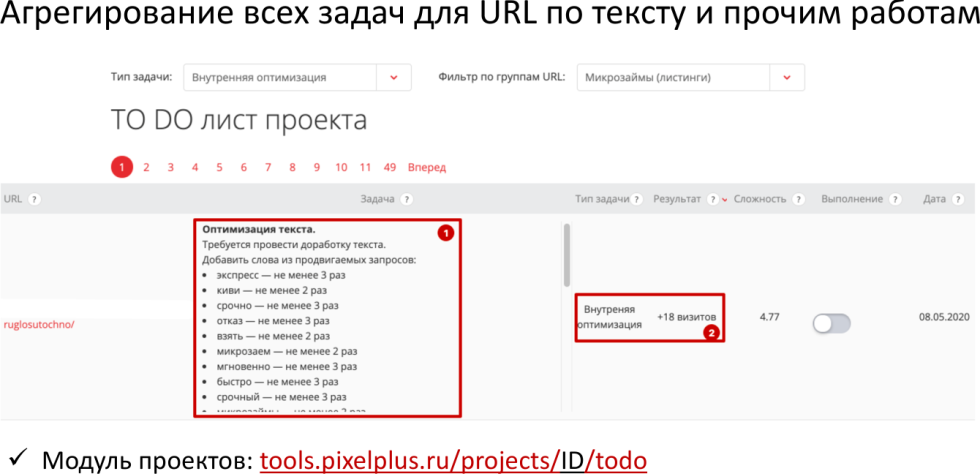
Эту вещь мы скоро запустим, сейчас мы ее дорабатываем по фидбеку наших пользователей. Здесь просто для всего URL-адреса будут сформированы конкретные рекомендации по оптимизации текста и даже прогноз визитов.
Вывод: работа с текстом — это в каком-то смысле искусство, хотя мы только что подробно разобрали, как правильно составлять текст, по шагам увидели, какие этапы нужны для того, чтобы текст был хороший и поняли, что это все можно делегировать, просто предоставив доступ к нашим инструментам и обучающим материалам.
Баден-Баден и другие текстовые фильтры: учитываем, избегаем, диагностируем и снимаем
Текстовые фильтры Яндекса
Есть пять таких фильтров, которые, в общем, очень похожи. Мы составили хорошее техническое задание для копирайтера, он написал отличный текст, мы его разместили на странице, там много вхождений, все замечательно с точки зрения текстовой релевантности.
Но поисковые системы давно поняли, что это некий лайфхак. SEO-специалисты и вообще люди, которые более-менее разбираются в том как вообще ранжируются документы, они просто пишут тексты, вставляют туда много вхождений и получают профит. Документ никак не улучшается с точки зрения решения пользовательских задач. И поисковые системы начали штрафовать за это, понижая выдачи документов, которые переспамлены вхождениями. Изначально понижали на 20 позиций, сейчас чуть более умная просадка, она может составлять и несколько позиций.
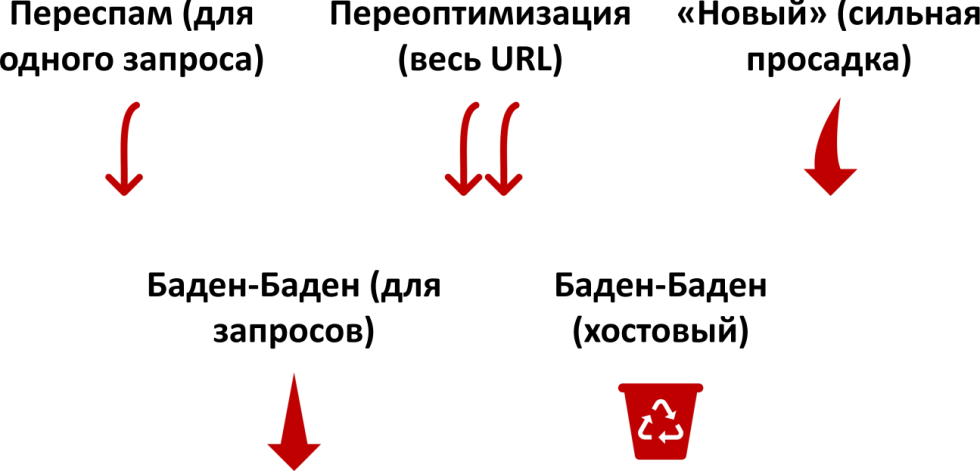
Вот эти названия запоминать необязательно. Можно запомнить, если вы хороший SEO-специалист, а если вы просто делаете оптимизацию, потому что хотите сами разобраться, надо просто понимать, что здесь есть три типа:
-
«Просаживается» один запрос. Просто какой-то запрос выпал и все.
-
«Просаживается» весь документ целиком. Он может выпасть, понизиться на 20 или на 6 мест — каждый запрос по-своему.
-
Выпал весь сайт.
Все сайты на IP никогда не просаживаются, все-таки это хостовая история, целиком соответствующая сайту. Хотя есть определенный набор факторов в антиспаме, который высчитывается целиком для IP-адреса, но это, как правило, связано с желанием поисковой системы избавиться от генерирования большого количества дорвеев и так далее.
То есть, три случая: один запрос, одна страница, один сайт.
Нюанс состоит в том, что о проблемах сайта говорят в панели Вебмастера Яндекса, но в случае с запросом и документом ничего не говорится. Если мы пишем напрямую в службу поддержки, нам отвечают, что все отлично, ранжируется согласно значению релевантности и так далее. Но это не так.
Вторая история, которую надо уметь определять и можно определять с помощью инструментов, которые есть у нас. На иллюстрации наглядно показано (без привязки к математической точности с точки зрения процентов), как примерно выглядит этот антиспам и оптимизация.
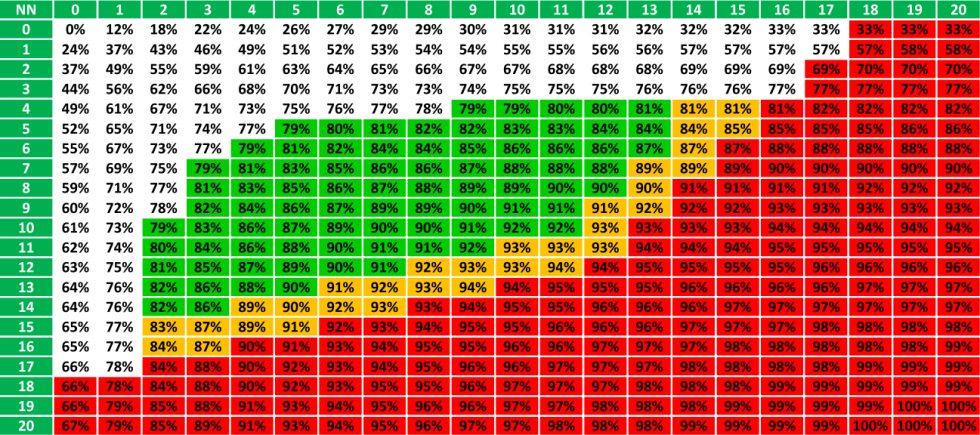
Если у вас ноль вхождений первого и второго слова на страницу, то у вас значение релевантности равно нулю. Если вы добавляете одно слово, то релевантность растет на несколько процентов. Если у вас 20 вхождений каждого слова, то вы получаете максимум релевантности, который вообще можно получить.
Если у нас одного слова нет, и только второе добавляется, то мы движемся по горизонтальной или вертикальной шкале — в зависимости от того, какое слово добавляется. Слово, которое по первой вертикальной шкале растет, оно в два раза более весомое. Такая IDF история, когда мы определяем вес слова и это реально рассчитанное значение функции BM25 для соотношения частот IDF двушка.
И вот мы добавляем второе вхождение, третье, четвертое, а потом добавляем одно вхождение второго слова. На примере мы видим фазовый переход с 49% релевантности от максимального до 61% релевантности.
Дальше мы пишем более или менее хорошее ТЗ на копирайтинг и попадаем в «зеленую зону». Например, в нашем хорошем тексте 8 вхождений одного слова, 5 вхождений другого слова и мы имеем хорошие значения от максимального значения текстовой релевантности, которые можно получить по этому конкретному фактору. Понятно, что факторов более 50, но вот так наглядно это можно представить даже на одном факторе, это соответствует реальности.
Дальше вы выходите в такую зону «на грани». Вы думаете, что маловато вхождений, поисковая система не на 100% понимает, чему посвящен мой текст, давайте добавим еще пятнадцатое вхождение какого-то слова. Сначала поисковая система это как-то переварит, а потом вы взяли и добавили шестнадцатый раз и попали под санкции.
То есть, у вас значение текстовой релевантности очень высокое, но вас очень сильно понизило, просто потому что вы начали применять тот «лайфхак», который не нравится поисковым системам — так как вы переспамливаете.
Вот эти пороги — зеленая зона, желтая и красная зона — они сдвигаются. Например, что-то произошло в поисковой системе, они переобучили алгоритм, раз — и пороги сдвинулись. Это такая «плавающая» стратегия, поэтому выгоднее и правильнее существовать вот в этой зеленой зоне.
Более того, есть второй подход, который говорит о том, что у нас меняются пороги вот этих санкций, в том числе, и при значениях самого сайта. То есть, у вас на сайте, на документе хорошие значения поведенческих факторов или хороший уровень доверия к сайту, поэтому в идеале это высчитать невозможно.
Инструмент диагностики по выдаче
Как проверить по выдаче, что у нас есть санкции? Как говорилось выше, поисковая система не сознается в том, что существуют санкции какого-либо типа, понижающие документ либо запрос. Точнее, у них в блоге написано, что такие фильтры есть, а то, что они реально применяются, никто не сознается.
Мы заходим в расширенный инструмент проверки на переоптимизацию https://tools.pixelplus.ru/tools/reoptimization-advanced, вставляем список поисковых запросов, вставляем сайт и получаем результат — вероятность применения фильтра к каждому. Им можно проверить до 50 штук на любом PRO-тарифе и дальше там некоторые рекомендации по тому, что есть.

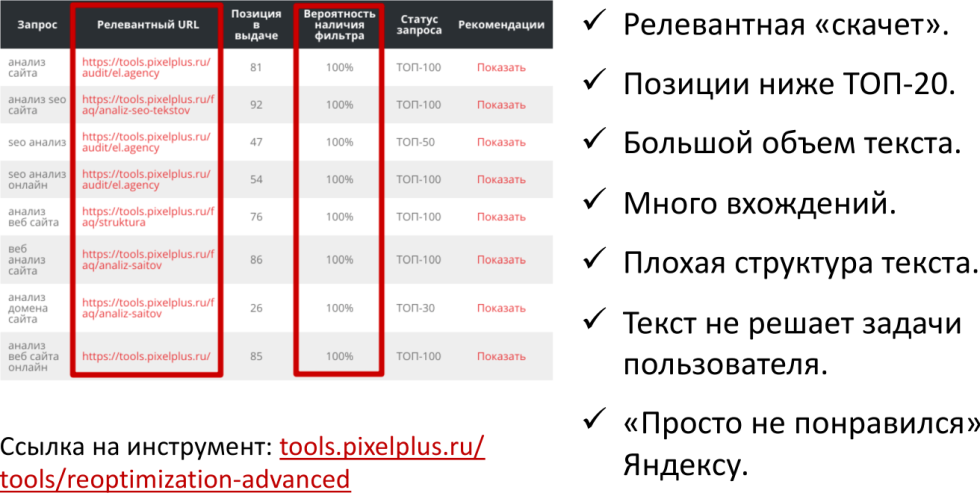
Результат проверки
На примере показано, что у нас есть вероятность наличия фильтра, она 100%, и дополнительные признаки, говорящие о том, что санкции действительно есть:
-
Релевантная страница «скачет», то есть, вы хотите одну страницу видеть в выдаче, а она меняется.
-
Позиции ниже топ-20.
-
Большой объем текста.
-
Много вхождений.
-
Плохая структура текста.
-
Текст не решает задачи пользователя.
-
«Просто не понравился» поисковой системе.
Проверка в модуле SEO-проектов
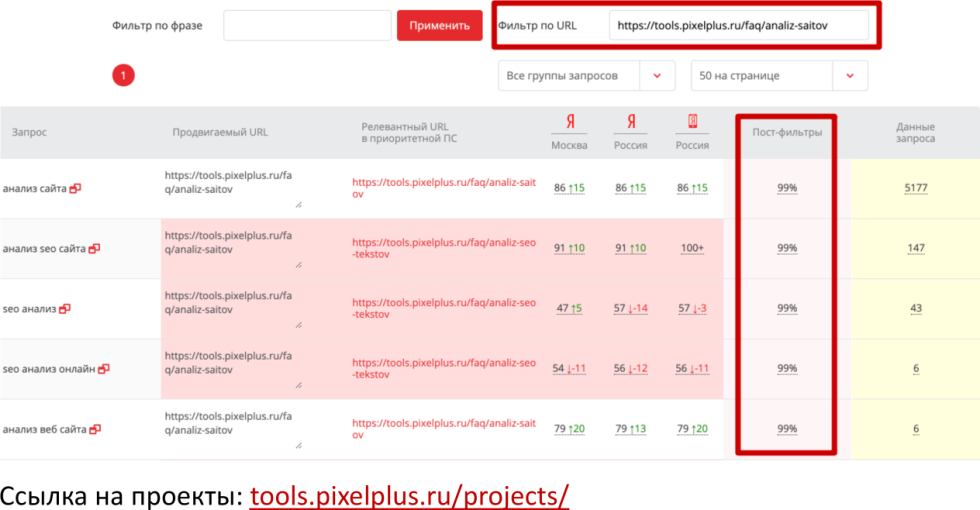
Если запросов очень много, надо обязательно пойти в модуль проектов https://tools.pixelplus.ru/projects/, завести туда семантику и каждый раз в съем позиций или около того, в зависимости от того, как у вас выставлены настройки, будет проверять вероятность санкций (есть или нет). Конечно, будет дергать не все запросы, а только те, по которым не в топе, у которых есть достаточный объем текста.
Меры снятия санкций, которые работают
Если у вас прямо сейчас есть подозрение, что копирайтер написал вам текст, плохо решающий проблемы пользователя, переспамленный и так далее, то есть три рабочих методики, которые можно применить. Часто сделать это гораздо быстрее, чем долго думать — есть санкции или нет, диагностировать, искать информацию по форумам и т. д.
-
Удалить весь SEO-текст со страницы. То есть, вы быстро проверяете гипотезу. Бывает такое, что санкции снимаются, но сайт при этом не растет по запросам выдачи, но, как правило, это довольно редкая история. Если у вас единственное что есть на странице — это текст, то да, так произойдет. Но в целом вы увидите какую-то динамику, либо отрицательную, либо положительную. Если она будет положительная, то гипотеза, что удалили текст, у вас понизилось значение текстовых релевантностей, но вы выросли, значит, единственный верный вариант — это у вас сняли санкции.
-
Полностью переписать текст. Действенная методика, она состоит в новом техническом задании и привлечении нового копирайтера.
-
Внести значительные изменения в текст. Самый простой вариант — это уменьшить его в два раза. Дополнительные требования: удаление воды, чистка вхождений.

Это все, что мы хотели сказать про текстовые фильтры. Если вы хотите в дальнейшем пройти сертификацию от Пиксель Тулс, то вам важно ответить на три вопроса.
Ответы на вопросы
Работает ли добавление тематических слов и LSI-фраз?
Ответ: Это добавление помогает вам определить тематику текста, более точно задать для копирайтера, о чем будет текст. С точки зрения ранжирования мы проводили определенные замеры на этот счет. Какого-то большого профита либо нет, либо он находится на уровне статистической погрешности до сих пор.
Если говорить о ранжировании в Google, там может быть немного по-другому, и это связано с тем, что Google чуть хуже понимает русскую морфологию и немного больший вес (по нашей оценке) там имеет все, что касается не прямых вхождений, а тематического соответствия страниц. Возможно, поэтому этот тренд на LSI и пришел к нам с запада.
Иногда на странице продвигается более 25 запросов, как их использовать?
Ответ: Если у вас есть проблемы с ограничением на 25 запросов в ТЗ на копирайтинг, то либо используйте сортировку, либо обрабатывайте пачками, тоже вариант: 25 первых, 25 вторых и так далее.
Показывается ли тег ?
Как сделать анализ топа сразу по группе запросов?
Как можно выявить постраничный Баден-Баден?
Ответ: Нужно зайти в инструмент проверки на переоптимизацию https://tools.pixelplus.ru/tools/reoptimization-advanced и сделать диагностику.
Подробнее про хостовые санкции. Хост тут сайт или IP? Влияет ли на санкции количество сайтов и их спамность на одном IP на конкретный неспамный сайт?
Ответ: Сайт или IP — сайт. Если у вас на одном IP 200 сайтов и 199 из них, допустим, под фильтром Дорвей, удалены, то да, влияет. То есть, вероятность что двухсотый тоже будет признан Дорвеем, довольно высока. Если у вас 200 небольших сайтов и они нормально себя чувствуют, то глобального какого-то плюс-минус нет, хотя есть такая «карма айпишника» и если проект серьезный и вы боитесь дополнительных неопределенностей, то вы выделяете отдельный IP.
Какой смысл считать BM25 в современный период?
Ответ: Мы рассказывали о том, какие есть факторы текстового ранжирования, люди должны понимать, что это такое, что такое ВМ25. Поисковая система, безусловно, использует ВМ25 в своих алгоритмах. И важно иметь наличие вхождений слов и запросов в текст. Зачем это важно — чтобы удовлетворить этим факторам. Это актуально по сей день.
Работа с текстом — это определенное искусство и очень важно понимать, каким образом должен выглядеть текст, решающий проблемы ваших пользователей.
Мы даем технологию, ваша задача — действовать. Делайте крутые технические задания для копирайтеров, пишите умные и грамотные тексты, решайте задачи пользователей и будете в топе, потому что это одна из самых важных групп факторов, которые есть в поисковой системе.
Запись вебинара
Чтобы не пропускать новые материалы, подписывайтесь на наши группу ВКонтакте, чат Telegram и канал YouTube.

Рейтинг статьи:
По оценкам 35 пользователей

Другие материалы