Bard — это генеративный чат-бот с искусственным интеллектом на базе LaMDA. Понимание Bard и того, как он может быть интегрирован в поиск, необходимо каждому, кто занимается или собирается заняться SEO. Напомним, что Google выпустил Bard в ответ стремительно развивающемуся ChatGPT от OpenAI. Далее поговорим о его алгоритмах и чего стоит ожидать SEO-специалистам в ближайшем будущем.
Что такое Google Bard?
Это генеративный ИИ, который принимает запросы и выполняет текстовые задачи, такие как предоставление ответов, а также создание различных форм контента. Bard также помогает изучать темы, обобщая информацию, найденную в интернете и предоставляя ссылки для поиска сайтов с дополнительной информацией. Главное отличие от ChatGPT — у Bard есть доступ к сети, контент обладает более высоким процентом достоверности.
Почему Google выпустил Bard?
Google выпустил Bard после успешного запуска ChatGPT от OpenAI, который создал впечатление, что Google отстаёт в технологическом плане. ChatGPT была воспринята как революционная технология, способная разрушить поисковую индустрию и сместить баланс сил в сторону от поиска Google и прибыльного бизнеса контекстной рекламы.
21 декабря 2022 года, через три недели после запуска ChatGPT, газета New York Times сообщила, что Google объявил «красный код», чтобы быстро подготовить свой ответ на угрозу, возникшую для его бизнеса.
Через сорок семь дней после корректировки стратегии «красного кода» компания Google объявила о запуске Bard 6 февраля 2023 года.
В чём была проблема с Google Bard?
Анонс Bard стал ошеломляюще неудачным, потому что демонстрация, которая должна была продемонстрировать ИИ чат-бота Google, содержала фактическую ошибку. Неточность ИИ Google превратила то, что должно было стать триумфальным возвращением к форме, в унизительный «пирог в лицо». Впоследствии акции Google потеряли сто миллиардов долларов рыночной стоимости за один день, что отражает потерю уверенности в способности Google ориентироваться в надвигающейся эре ИИ.
Как работает Google Bard?
Bard работает на основе «облегченной» версии LaMDA.
LaMDA — это большая языковая модель, которая обучается на наборах данных, состоящих из публичных диалогов и данных. Есть два важных фактора, связанных с обучением, описанных в соответствующем исследовательском документе, который вы можете изучить в формате PDF «LaMDA: Языковые модели для диалоговых приложений».
Что показывает LaMDA?
- Безопасность: Модель достигает определенного уровня безопасности за счёт настройки с помощью данных, которые были аннотированы сотрудниками компании.
- Обоснованность: LaMDA основывается на фактах из внешних источников знаний (через получение информации, которая находится в поиске).
В исследовательском документе LaMDA говорится следующее:
«...фактологическое обоснование включает в себя предоставление модели возможности обращаться к внешним источникам знаний, таким как информационно-поисковая система, языковой переводчик и калькулятор.
Мы оцениваем достоверность ответов с помощью метрики обоснованности, и мы обнаружили, что наш подход позволяет модели генерировать ответы, основанные на известных источниках, а не ответы, которые просто звучат правдоподобно».
Google использовал три метрики для оценки результатов работы LaMDA:
- Чувствительность. Оценка того, имеет ли ответ смысл или нет.
- Специфичность. Определяет, является ли ответ противоположным общему мнению или он контекстуально конкретный.
- Интересность. Эта метрика измеряет, являются ли ответы LaMDA проницательными или вызывают любопытство.

Все три показателя оценивались краудсорсинговыми экспертами и эти данные были возвращены в ИИ для его дальнейшего совершенствования. В заключении исследовательской работы LaMDA говорится, что краудсорсинговые оценки и способность системы проверять факты с помощью поисковой системы показали себя наилучшим образом.
Исследователи Google написали:
«Мы обнаружили, что крауд-аннотированные данные являются эффективным инструментом для получения дополнительных преимуществ, чтобы воплотить их в LaMDA.
Мы подтверждаем, что обращение к внешним API (например, к информационно-поисковой системе) открывает путь к значительному улучшению обоснованности, которую мы определяем как степень, в которой сгенерированный ответ содержит утверждения, на которые можно сослаться и проверить по известному источнику».
Как Google планирует использовать Bard в поиске?
Будущее Bard в настоящее время рассматривается как функция в поиске. Заявление Google, сделанное в феврале, было недостаточно конкретным в отношении того, как точно будет реализован Bard.
Ключевые детали были описаны в одном абзаце, расположенном ближе к концу анонса блога о Bard, где он был описан как функция ИИ в поиске. Отсутствие ясности создало впечатление, что Bard будет интегрирован в поиск, чего никогда не было:
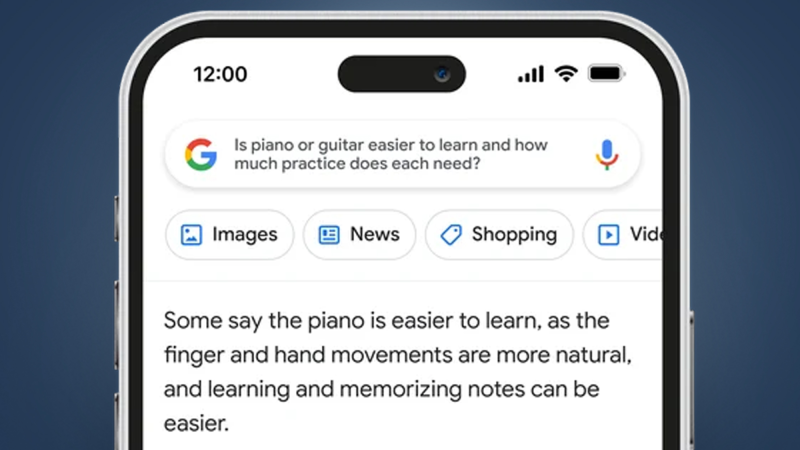
«Вскоре вы увидите в поиске функции на базе ИИ, которые будут переводить сложную информацию и множество точек зрения в удобные для восприятия форматы, чтобы вы могли быстро понять общую картину и узнать больше из интернета. Будет это поиск дополнительных точек зрения, например блогов людей, играющих на пианино и гитаре или углубление в смежную тему, например шаги для начинающих музыкантов.
Эти новые функции ИИ начнут внедряться в поиск уже в ближайшее время».
Понятно, что Bard — это не поиск. Скорее, он задуман как функция поиска, а не как его замена.
Что такое функция поиска?
Функция — это что-то вроде панели знаний Google, которая предоставляет информацию об известных людях, местах и вещах.
На странице Google «Как работает поиск», рассказывается о функциях:
«Функции поиска Google обеспечивают получение нужной информации в нужное время в формате, который наиболее точен для вашего запроса. Иногда это страница, а иногда реальная информация, например карта или товарный остаток в местном магазине».
На одном из внутренних совещаний в Google (об этом сообщает CNBC) сотрудники поставили под сомнение использование Bard в поиске.
Один из сотрудников отметил, что такие крупные языковые модели, как ChatGPT и Bard, не являются источниками информации, основанными на фактах.
Сотрудник Google спросил:
«Почему мы считаем, что первым большим приложением должен быть поиск, который по своей сути является поиском достоверной информации?».
Джек Кравчик, руководитель проекта Google Bard, ответил:
«Я просто хочу внести ясность: Bard — это не поиск».
На том же внутреннем мероприятии вице-президент Google по разработке поиска Элизабет Рид подтвердила, что Bard — это не поиск.
Она сказала:
«Bard действительно отделён от поиска...».
Мы можем с уверенностью заявить, что Bard не является новой итерацией поиска Google. Это функция. Bard — это интерактивный метод для изучения тем. Это означает, что в то время, как поиск даёт ссылки на ответы, Bard помогает пользователям исследовать знания.
В заявлении поясняется:
«Когда люди думают о Google, они часто представляют, что обращаются к нам за быстрыми фактическими ответами, например, «сколько клавиш у пианино?».
Но все чаще люди обращаются к Google за более глубокими знаниями и пониманием, например, «что легче освоить — фортепиано или гитару и сколько практики нужно для каждого из них?».
Изучение подобной темы может потребовать много усилий, чтобы понять, что вам действительно нужно знать и люди часто хотят изучить широкий спектр мнений или точек зрения».
Возможно, полезно рассматривать Bard как интерактивный метод доступа к знаниям о различных темах.
Bard предоставляет информацию на основе поиска в интернете
Проблема больших языковых моделей заключается в том, что они имитируют ответы, что может привести к фактическим ошибкам. Исследователи, создавшие LaMDA, утверждают, что такие подходы, как увеличение размера модели, могут помочь ей получить больше фактической информации.
Но они отметили, что этот подход не работает в тех областях, где факты постоянно меняются в течение времени, что исследователи называют «проблемой временного обобщения».
Свежесть в смысле своевременности информации не может быть обучена с помощью статической языковой модели. Решением, которое было предложено LaMDA, стало обращение к информационно-поисковым системам. Информационно-поисковая система — это поисковая система по типу Google, поэтому LaMDA проверяет результаты поиска.
Эта функция LaMDA, похоже, является функцией Bard.
В заявлении Google Bard поясняется:
«Bard стремится объединить широту мировых знаний с мощью, интеллектом и креативностью наших больших языковых моделей. Он использует информацию из интернета, чтобы предоставлять свежие, высококачественные ответы».
LaMDA и Bard достигают этого с помощью того, что называется набором инструментов (Tool Set — TS).
Набор инструментов объясняется в статье исследователя LaMDA:
«Мы создаём набор инструментов (TS), который включает в себя информационно-поисковую систему, калькулятор и переводчик. TS принимает на вход одну строку и выдает список из одной или нескольких строк. Каждый инструмент в TS ожидает строку и возвращает список строк.
Например, калькулятор принимает «135+7721» и выдает список, содержащий [7856]. Аналогично, переводчик может принять «привет на французском» и вывести [Bonjour].
Наконец, информационно-поисковая система может взять вопрос «Сколько лет Рафаэлю Надалю?» и вывести [Рафаэль Надаль / Возраст / 35].
Информационно-поисковая система также способна возвращать фрагменты контента из открытой сети с соответствующими URL-адресами. TS пробует входную строку на всех своих инструментах и выдает окончательный список строк, объединяя выходные списки от каждого инструмента в следующем порядке: калькулятор, переводчик и информационно-поисковая система.
Инструмент возвращает пустой список результатов, если он не может разобрать входные данные (например, калькулятор не может разобрать «Сколько лет Рафаэлю Надалю?») и поэтому не вносит свой ответ в конечный список результатов».
Разговорные системы ответов на вопросы
Не существует научных работ, в которых упоминалось бы имя «Бард». Однако существует довольно много недавних исследований, связанных с ИИ, в том числе учёными, связанными с LaMDA, которые могут оказать влияние на Bard.
Ниже не утверждается, что Google использует эти алгоритмы. Мы не можем с уверенностью утверждать, что какая-либо из этих технологий используется в Bard.
Ценность знания об этих научных работах заключается в том, что мы знаем, что возможно, а что нет. Ниже перечислены алгоритмы, имеющие отношение к системам ответов на вопросы на основе ИИ.
Один из авторов LaMDA работал над проектом по созданию обучающих данных для разговорной информационно-поисковой системы. Вы можете изучить его исследовательскую работу 2022 года «Dialog Inpainting: Превращение документов в диалоги».
Проблема обучения такой системы, как Bard, заключается в том, что наборы данных «вопрос-ответ» (например, наборы данных, состоящие из вопросов и ответов, найденных на Reddit) ограничены поведением людей на Reddit. Они не охватывают поведение людей вне этой среды, типы вопросов, которые они задают и правильные ответы на эти вопросы.
Исследователи изучили возможность создания системы, которая читала бы страницы, а затем использовала «диалоговый алгоритм» для предсказания того, на какие вопросы будет отвечать тот или иной отрывок из того, что читала машина.
Отрывок из заслуживающей доверия страницы Википедии, где говорится: «Небо голубое», можно превратить в вопрос: «Какого цвета небо?».
Исследователи создали собственную базу данных вопросов и ответов, используя Википедию и другие страницы. Они назвали эти наборы данных WikiDialog и WebDialog.
- WikiDialog — это набор вопросов и ответов, полученных из данных Википедии.
- WebDialog — это набор данных, полученных из диалогов на страницах в интернете.
Эти новые наборы данных в тысячу раз больше, чем существующие. Важность этого в том, что это даёт моделям разговорного языка возможность узнать больше. Исследователи сообщили, что этот новый набор данных помог улучшить системы разговорных вопросов-ответов более чем на 40%.
В научной статье описывается успех этого подхода:
«Важно отметить, что наши исходные наборы данных являются мощным источником обучающих данных для систем ConvQA. При использовании для предварительного обучения стандартных архитектур извлечения и перестраивания, они улучшают современное положение дел в трёх различных эталонах ConvQA (QRECC, OR-QUAC, TREC-CAST), обеспечивая до 40% относительного выигрыша по стандартным метрикам оценки.
Примечательно, что предварительное обучение на WikiDialog позволяет добиться высокой производительности поиска с нулевой точки до 95% от производительности тонко настроенного инструмента извлечения, без использования каких-либо данных ConvQA в домене».
Возможно ли, что Google Bard был обучен с использованием наборов данных WikiDialog и WebDialog?
Трудно представить себе сценарий, при котором Google отказался бы от обучения разговорного ИИ на наборе данных, который более чем в тысячу раз больше. Но мы не знаем наверняка, потому что Google не часто подробно комментирует свои базовые технологии, за исключением редких случаев, таких как Bard или LaMDA.
Большие языковые модели со ссылками на источники
Недавно Google опубликовал интересную исследовательскую работу о том, как заставить большие языковые модели ссылаться на источники информации. Первоначальная версия статьи была опубликована в декабре 2022 года, а вторая версия была обновлена в феврале 2023 года.
Эта технология является экспериментальной по состоянию на декабрь 2022 года.
Вы можете изучить материал «Attributed Question Answering: Оценка и моделирование для атрибутированных больших языковых моделей».
В научной статье говорится о цели технологии:
«Большие языковые модели (LLM) показали впечатляющие результаты, не требуя или почти не требуя прямого контроля. Кроме того, появляется все больше доказательств того, что LLM могут иметь потенциал в сценариях поиска информации.
Мы считаем, что способность LLM атрибутировать текст, который она генерирует, вероятно, будет иметь решающее значение в этой ситуации. Мы сформулировали и изучили атрибутивную QA как ключевой первый шаг в развитии атрибутивных LLM.
Предлагаем воспроизводимую систему оценки для этой задачи и сравниваем широкий набор архитектур. Мы принимаем человеческие аннотации в качестве золотого стандарта и показываем, что корреляционная автоматическая метрика подходит для разработки.
Наша экспериментальная работа даёт конкретные ответы на два ключевых вопроса — «Как измерить атрибуцию?» и «Насколько хорошо текущие современные методы справляются с атрибуцией?». Также она даёт некоторые подсказки, как решить третий вопрос — «Как построить LLM с атрибуцией?».
Такая большая языковая модель может обучить систему, способную отвечать на вопросы с сопроводительной документацией, которая, теоретически, гарантирует, что ответ на чём-то основан.
В исследовательской работе поясняется:
«Чтобы изучить эти вопросы, мы предлагаем атрибутированные ответы на вопросы (QA). В нашей формулировке входной информацией для модели/системы является вопрос, а выходной — пара (ответ, атрибуция), где ответ — это строка ответа, а атрибуция — указатель на фиксированный элемент, например параграф.
Возвращаемая атрибуция должна содержать подтверждающие доказательства ответа».
Эта технология предназначена специально для задач, связанных с ответами на вопросы. Целью является создание лучших ответов то, чего Google, по понятным причинам, хочет для Bard.
Атрибуция позволяет пользователям и разработчикам оценивать «достоверность и нюансы» ответов. Также она даёт разработчикам быстро проверять качество ответов, поскольку указываются источники. Интересно отметить новую технологию под названием AutoAIS, которая сильно коррелирует с человеческими оценщиками.
Другими словами, эта технология может автоматизировать работу человеческих оценщиков и масштабировать процесс оценки ответов, выдаваемых большой языковой моделью (например, Bard).
Исследователи отмечают:
«Мы считаем человеческий рейтинг золотым стандартом оценки системы, но обнаружили, что AutoAIS хорошо коррелирует с человеческим суждением на системном уровне, что открывает перспективы в качестве метрики разработки, когда человеческий рейтинг не представляется возможным».
Эта технология является экспериментальной, вероятно, она не используется. Но она демонстрирует одно из направлений, которое Google исследует для получения достоверных ответов.
Исследовательская работа о редактировании ответов на фактологию
Наконец, в Корнельском университете разработана замечательная технология (также датируемая концом 2022 года), которая исследует другой способ присвоения авторства за то, что выдаёт большая языковая модель и даже может редактировать ответ, чтобы исправить себя. Вы можете изучить PDF-файл «RARR: Researching and Revising What Language Models Say, Using Language Models».
В аннотации объясняется технология:
«Языковые модели (LM) сегодня отлично справляются со многими задачами, такими как обучение на нескольких фрагментах, ответы на вопросы, рассуждения и диалог. Однако иногда они генерируют неподтвержденный или вводящий в заблуждение контент.
Пользователь не может легко определить, заслуживают ли их результаты доверия или нет, потому что большинство LM не имеют встроенного механизма для атрибуции внешних доказательств.
Чтобы обеспечить возможность атрибуции и при этом сохранить все мощные преимущества моделей последнего поколения, мы предлагаем RARR (Retrofit Attribution using Research and Revision) систему, которая:
- Автоматически находит атрибуцию для вывода любой модели генерации текста.
- Редактирует ответ для исправления неподтвержденного содержания, максимально сохраняя исходный ответ.
Мы обнаружили, что RARR значительно улучшает атрибуцию, сохраняя при этом исходный вход в гораздо большей степени, чем ранее исследованные модели редактирования. Более того, для реализации RARR требуется всего несколько обучающих примеров, большая языковая модель и стандартный поиск».
Как получить доступ к Google Bard?
В настоящее время компания Google принимает новых пользователей для тестирования Bard, который пока носит статус экспериментального. Google предоставляет доступ к Bard здесь. Обратите внимание, что доступ с территории России, официально отсутствует. Но если использовать VPN и учётную запись Google с привязкой не к РФ, у вас получиться получить приглашение в систему.
Google официально заявляет, что Bard — это не поиск, что должно успокоить тех, кто испытывает тревогу по поводу наступления рассвета искусственного интеллекта.
Мы находимся на переломном этапе, который не похож ни на один из тех, что мы видели, возможно, за последнее десятилетие. Понимание Bard полезно для всех, кто публикуется в интернете или занимается SEO, потому что важно знать границы возможного и будущее того, что может быть достигнуто.
Благодарим Роджера Монти за статью, с оригиналом можете ознакомиться здесь.
И не забывайте подписаться на канал YouTube, чат Telegram и группу ВКонтакте, чтобы стать частью нашей дружной SEO-тусовки.