25 октября Google анонсировал крупное обновление поискового алгоритма — BERT (Bidirectional Encoder Representations from Transformers, то есть двунаправленный кодировщик на основе искусственного интеллекта).
Последнее схожее по своей важности обновление вышло 5 лет назад в виде алгоритма RankBrain. BERT также направлен на лучшее понимание интента пользователей и будет затрагивать более 10% всех поисковых запросов.
В чём суть BERT?
Алгоритм на основе deep learning поможет Google определять контекст и нюансы длинных поисковых запросов, сформированных на естественном/разговорном языке, с использованием предлогов. Каждое слово из запроса анализируется в отношении с остальными частями фразы, находящимися до и после слова (это и есть «двунаправленность» из названия алгоритма).
Кстати, Google представил открытый исходный код BERT ещё год назад, но развёртывать его в рамках поисковой системы начал только сейчас. То есть использовать предобученную модель BERT для NLP-задач (обработка естественного языка) может любой желающий.
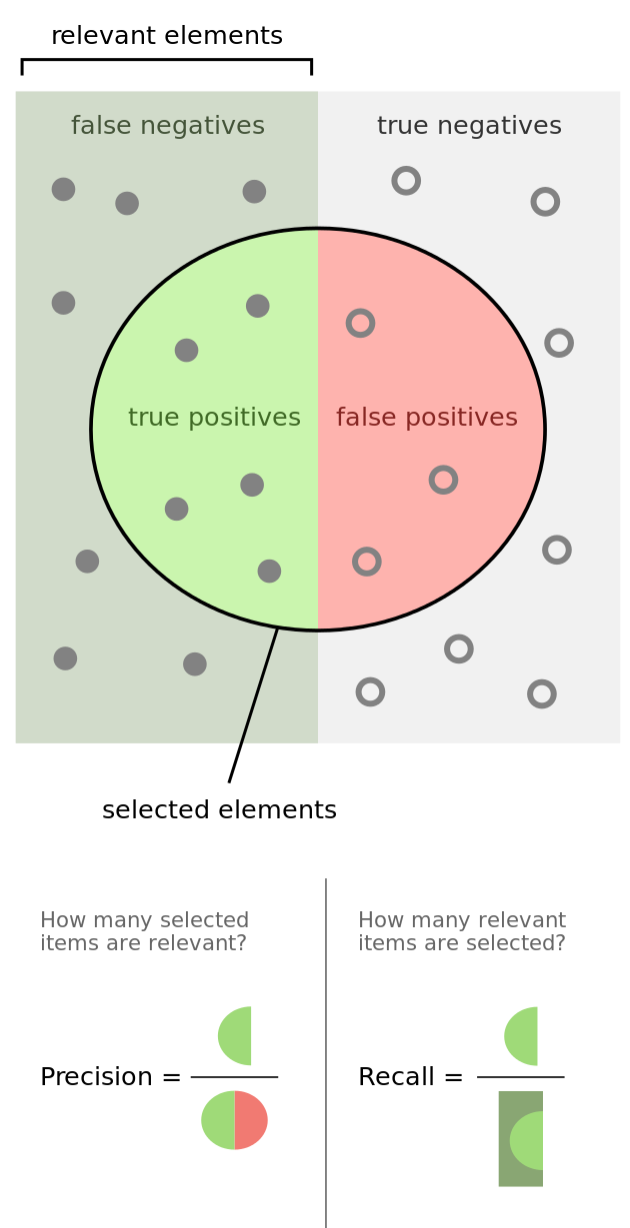
Ниже приведены данные об эффективности использования алгоритма в сравнении с пользовательским выбором (первая строчка) и схожими технологиями обработки естественного языка. EM — показатель точности, F1 — аккуратности (баланс точности и полноты классификации).
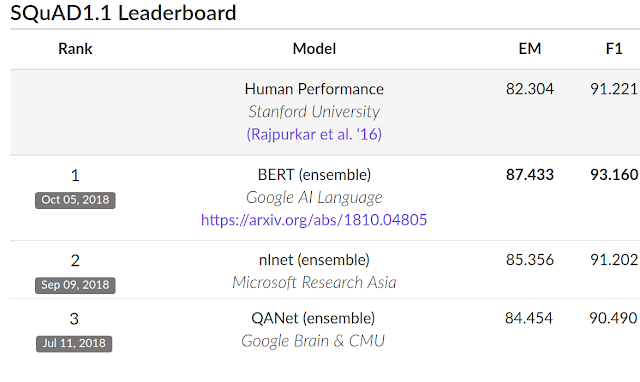
Иллюстрация расчета F-меры (баланс точности и полноты):
Как нововведение отразится на SEO?
Алгоритм повлияет как на ранжирование в Google, так и на формирование блоков ответов (featured snippets). Но BERT не будет затрагивать 100% ключевых фраз.
В ближайшее время модель начнёт действовать для 1 из 10 запросов на английском языке в США. BERT достаточно сложен и требует больших мощностей аппаратного обеспечения, поэтому пока его использование будет ограничено.
Примеры тестирования
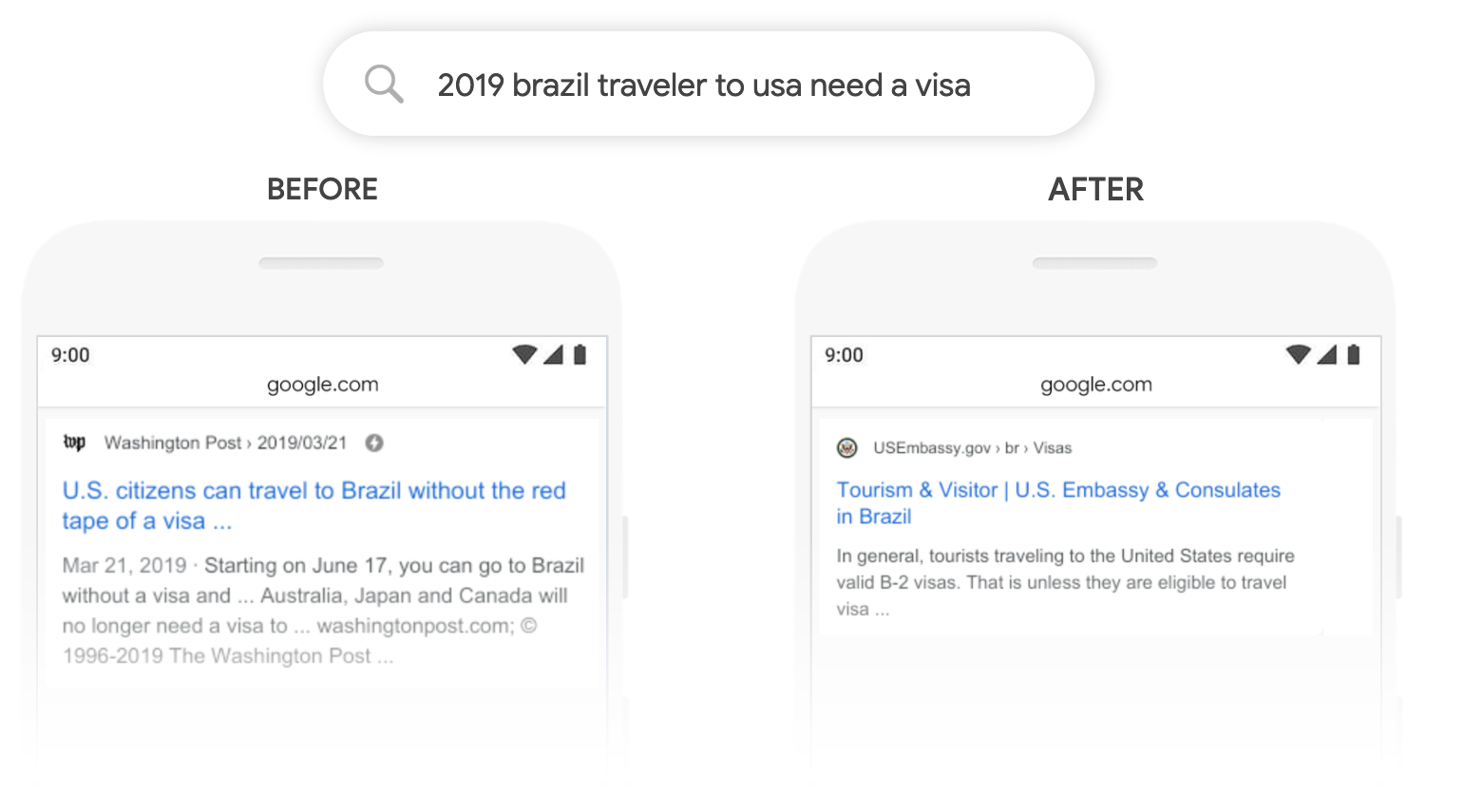
Запрос [2019 brazil traveler to usa need a visa], то есть «нужна ли виза бразильцу для путешествия в США». Фраза на английском языке осложняется предлогом «to» и до апдейта алгоритма понималась неправильно. В результатах выдачи в ТОПе были страницы о поездке граждан США в Бразилию, теперь — наоборот.
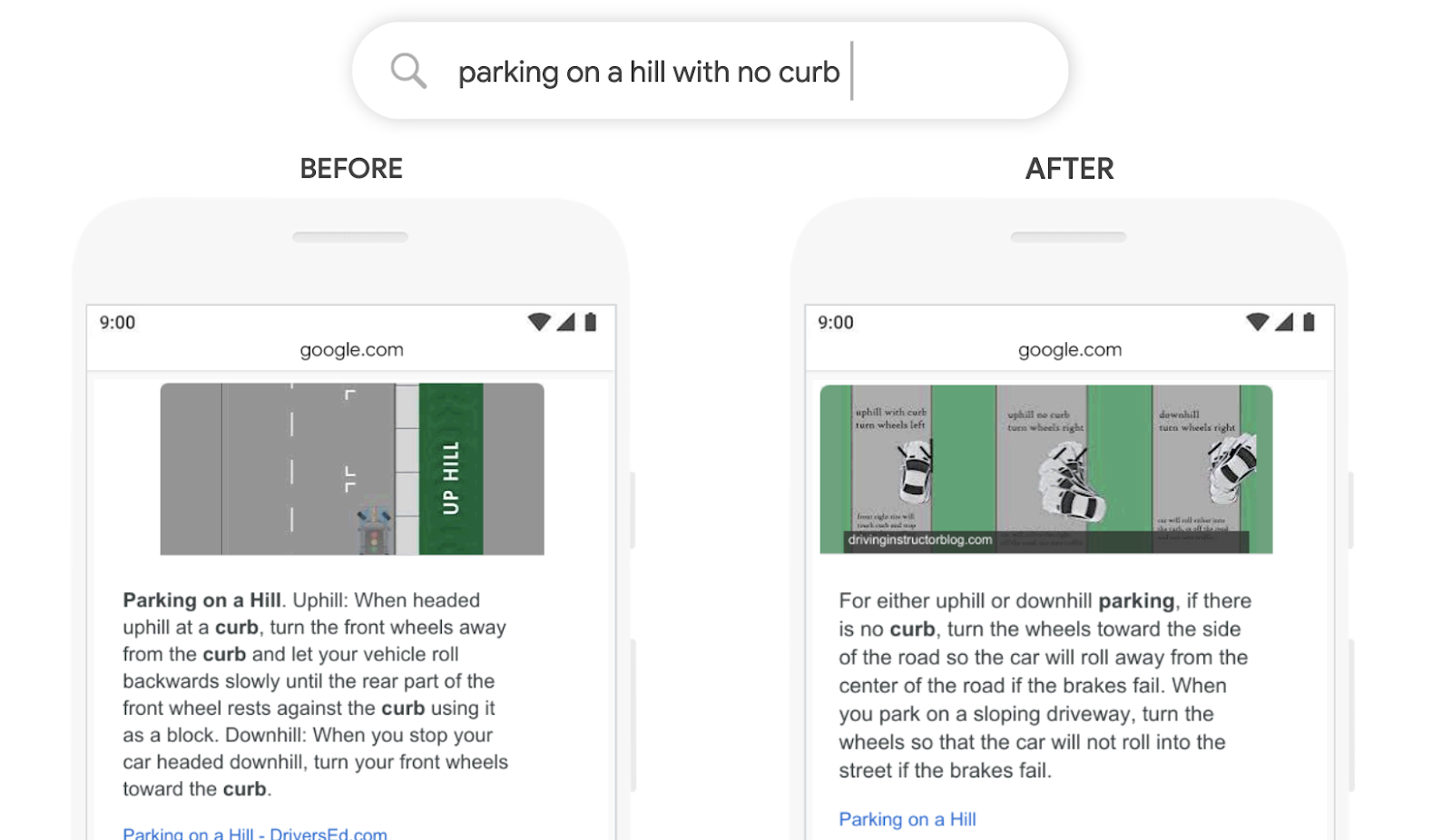
Разумеется, такое «переосмысление» должно привести к масштабным изменениям выдачи по ряду ключевых фраз. Например, запрос [parking on a hill with no curb], то есть «парковка на холме без бордюра». Ранее слову «бордюр» придавалась излишнее значение и результаты выдачи были нерелевантными. Использование BERT даёт правильный и наглядный ответ.
Ещё один интересный пример: специалист по поисковому маркетингу Роджер Монтти, 1 октября (до внедрения алгоритма) проверил выдачу по запросу [how to catch a cow fishing], то есть «как ловить корову на рыбалке». Слово «cow» в Новой Англии также обозначает полосатого окуня. Google проигнорировал слово «рыбалка» и отдал результаты, связанные с коровами. Тот же запрос 25 октября приводит к результатам, посвященным именно рыбалке и полосатым окуням.
Но новый алгоритм не даёт право расслабляться по части оптимизации текстов, наоборот, привлечь больше трафика смогут те страницы, где контент хорошо проработан и организован.
Что делать уже сегодня?
Экспертный комментарий и советы Дмитрия Севальнева, евангелиста проекта «Пиксель Тулс»:
BERT — хорош, но пока только на английском. Будем ожидать запуска алгоритма и на остальных языках.
Поисковые системы активно работают над повышением качества поиска по длинному хвосту запросов. Google запустил свой RankBrain в 2015 году, потом его догонять начал Яндекс, в 2016 — запуск алгоритма Палех в 2017 — Королёв. Мы даже проводили сравнение качества работы алгоритмов Королёв от Яндекса и RankBrain от Google на выборке, будет повод повторить.
Бурный рост числа голосовых запросов, заданных на естественном языке и, часто, с ошибками, приводит к необходимости и далее улучшать качество выдачи по этой группе фраз.
Что делать оптимизаторам и копирайтерам?
Основные пожелания:
-
Полное раскрытие темы = лонгриды, гайды и руководства будут ранжироваться выше.
-
Анализировать статистику поисковых запросов, по которым осуществлялись заходы и поисковые подсказки. Да, там тоже появляются НЧ и мНЧ-фразы, которых нет в других системах статистики. Добавляйте их в контент.
-
Больше UGC на сайте. Если пользователи будут создавать контент, то он будет хорошо ранжироваться по запросам, которые будут совпадать по теме. Q&A-блоги, FAQ — аналогично.
-
Анализировать логи внутреннего поиска и создавать контент под запросы, найденные там.
-
В первую очередь, анализировать оптимизацию мобильной версии сайта и только потом — десктопа.