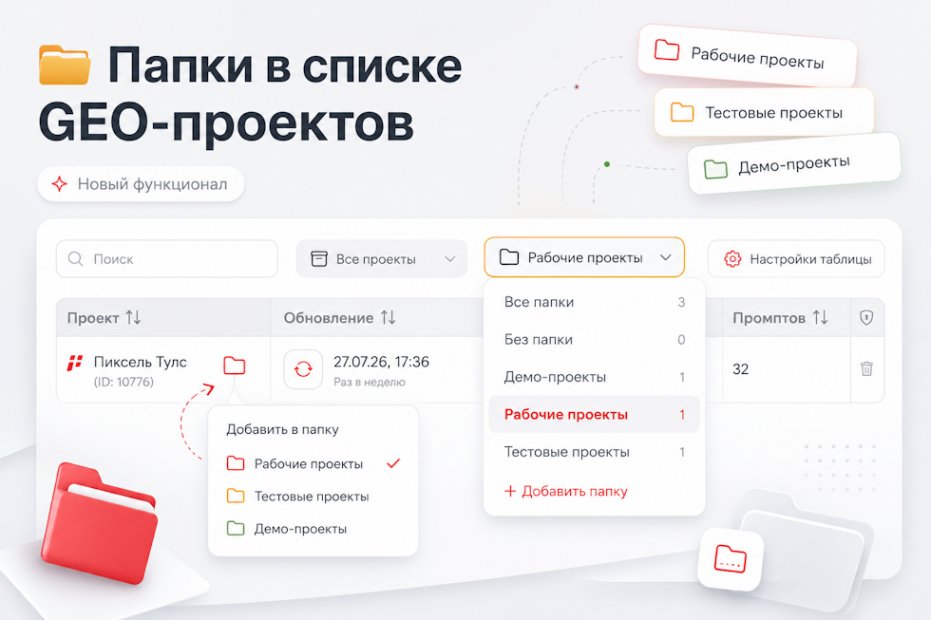
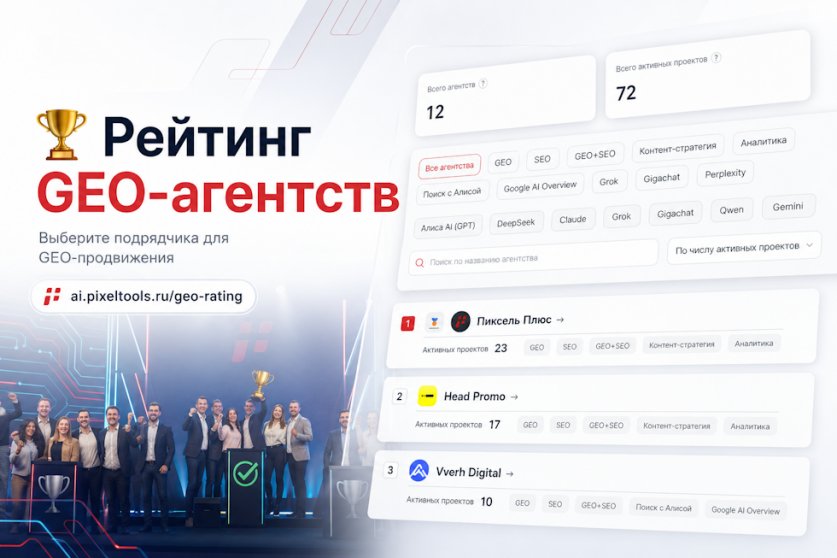
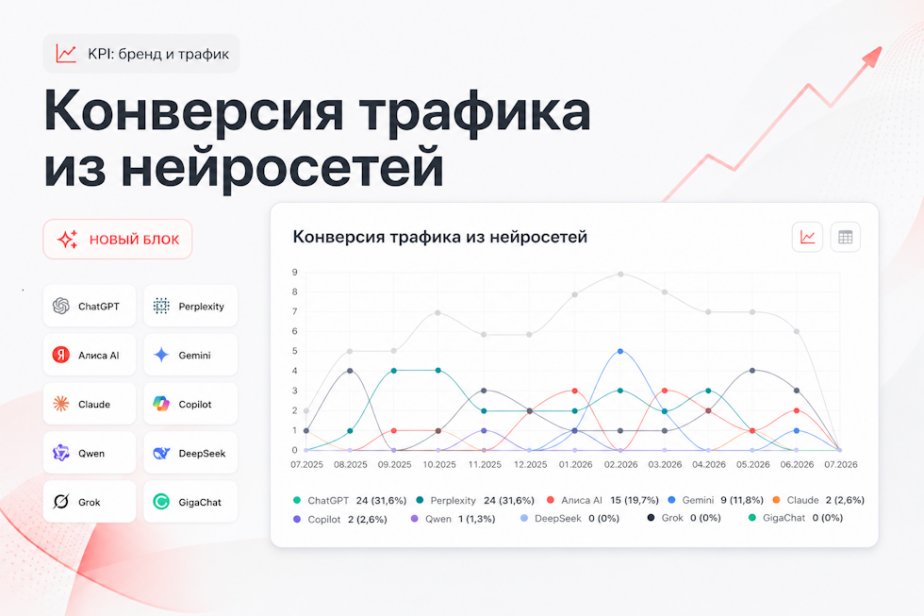
Новая функция в GEO-проектах покажет, на каких источниках из ответов нейросетей упоминается ваш бренд.
Сегодня, мы расскажем вам об утечке факторов ранжирования Google и расскажем, как это можно использовать для улучшения ваших SEO-экспериментов и стратегий.
В конце мая, была обнаружена утечка документа из публичной платформы Google Cloud под названием Document AI Warehouse, которая используется для анализа, организации, поиска и хранения данных. Эта публичная документация называется Document AI Warehouse overview. В сообщениях говорится, что «утечка» данных — это «внутренняя версия» публично доступной документации Document AI Warehouse.
Это, похоже, ставит крест на идее, что «утечка» данных представляет собой внутреннюю информацию Google Search.
Важно относиться к этим данным непредвзято, потому что многое в них не подтверждено. Например, неизвестно, является ли это внутренним документом команды ответственной за развитие поиска. Поэтому, вероятно, не стоит воспринимать эти данные как истину в последней инстанции. Также не стоит анализировать данные, чтобы подтвердить свои давние убеждения. Так человек попадает в ловушку Confirmation Bias.
Confirmation Bias — это тенденция искать, интерпретировать, отдавать предпочтение и воспринимать информацию таким образом, чтобы она подтверждала или поддерживала прежние убеждения или ценности.
Такое поведение приводит к тому, что человек отрицает то, что эмпирически является правдой. Например, существует давняя идея, что Google автоматически не дает новым сайтам ранжироваться — теория, называемая «песочницей». Люди каждый день сообщают, что их новые сайты и новые страницы почти сразу попадают в первую десятку поиска Google. Но если вы твердо верите в «песочницу», то такой реальный опыт будет отвергнут, сколько бы людей ни наблюдали обратное.
Единственный вопрос, который мы должны себе задать, изучая этот документ, звучит так: «Как я могу проверить и узнать как можно больше из этих данных?» SEO — это прикладная наука, где теория не конечная цель, а основа для экспериментов.
Лучшего рассадника идей для тестов и не придумаешь. Но мы не можем тестировать все факторы одинаково. У них разные типы (число/целое число: диапазон, булево: да/нет, строка: слово/список) и время реакции (имеется в виду скорость, с которой они приводят к изменению органического ранжирования).
В результате мы можем проводить A/B-тестирование быстрых и активных факторов, в то время как медленные и пассивные приходится тестировать до/после.
Сетка 2x2 с осями «Быстрый» - «Медленный» по оси Y и «Пассивный» - «Активный» по оси X, отражающая факторы ранжирования Google.
Систематически тестируйте факторы ранжирования:
Дмитрий Севальнев, евангелист Пиксель Тулс, считает:
«В этом и парадокс подобных утечек, что вроде ВОТ У ТЕБЯ В РУКАХ самое ценное, что есть у поисковой системы, а сделать с этим ты, фактически, почти ничего не можешь =)
— Хорошая идея брать факторы и тестировать работу с ними на реальном проекте. Но, по опыту, это будут делать единицы.
— Можно попробовать построить свою формулу на этих факторах с помощью ML, но, это ещё менее подъёмная задача.
Мы просто изучаем списки, читаем описания. Чем-то похоже на академическую работу, когда ты повышаешь свою глубину знаний и начинаешь думать, как ПС».
Большинство факторов ранжирования в утечке — целые числа, то есть они работают на спектре, но некоторые булевы факторы легко протестировать:
Факторы, которые вы можете непосредственно контролировать:
Негативные факторы ранжирования:
Факторы, на которые вы можете повлиять только пассивно:
Начните с оценки ваших показателей в той области, в которой вы хотите провести тестирование. В качестве примера можно привести Core Web Vitals.
Выберите правильную метрику для нужного фактора, основываясь на описании в документе или на своем понимании того, как фактор может повлиять на метрику:
Найдите подходящее место для тестирования:
Факторы ранжирования могут работать как вместе, так и против друг друга, поскольку они являются частью уравнения. Люди, как известно, плохо понимают интуитивно функции с большим количеством переменных, поэтому мы, скорее всего, недооцениваем, как много зависит от достижения высоких результатов по весомым факторам, но также и то, как несколько маленьких переменных могут существенно повлиять на результат.
Высокая сложность взаимосвязи между факторами ранжирования не должна удерживать нас от экспериментов. Агрегаторам тестировать легче, чем интеграторам, потому что у них больше сопоставимых страниц, которые приводят к более значимым результатам. Интеграторы, которым приходится самим создавать контент, имеют различия между всеми страницами, по итогу они размывают результаты тестов.
На этот счет Дмитрий Севальнев рекомендует:
«Мы в российском сегменте немного избалованы утечками из других поисковых систем… =)
Из мыслей:
— Инженеры поисковых систем мыслят в одну сторону. Если что-то работает, скажем, в Яндексе, то оно с большой долей вероятности есть и в Google.
— Всё, что вы придумаете и что будет иметь логику — будет в поисковой системе!
— Google и правда более замороченный в плане ссылочных факторов.
Каждая ссылка — под микроскопом!»
Сергей Просветов, старший SEO-специалист команды Пиксель Плюс, поддерживает мнение Дмитрия:
«Одна из самых обсуждаемых тем сегодня, при этом уверенно сказать, что мы сейчас проработаем 2-3 пункта и сайт займет лидирующие позиции – нельзя.
«Вот тебе слитые данные Google, почему мы еще не в ТОПе!?»
Если предположить, что факторы являются частью общего уравнения, едва ли получится достигнуть высоких результатов влиянием на какие-то отдельные из них (как последнее время ПФ в Яндексе).
Более того, нет гарантий, что целенаправленно усилив влияние каких-то отдельных факторов (например, ссылочное или поведенческие), мы не сделаем только хуже.
В конечном итоге мы не отходим от концепции комплексного развития проектов с тестированием гипотез.»
Игорь Хомяков, руководитель SEO-производства Пиксель Плюс настроен более рационально:
«К сожалению, того, что мы действительно можем применить на практике не так и много. В сведениях нет четкого руководства к действию, когда взяли один или несколько факторов, проработали документ/сайт и далее получили рост видимости/трафика. Там вы не увидите однозначных критериев по оптимизации Title или того какие и сколько блоков должно находиться на странице, чтобы она ранжировалась в ТОП-10.
Я бы слитые данные предложил рассматривать в плоскости исследовательской деятельности:
Знание действительно сила, ведь в руках пытливого SEO-шника они перевоплощаются в мощнейшие инструменты осознанного контроля и управления поисковой оптимизации любых сайтов. Каждая гипотеза, каждое действие и принятое решение будет находиться в реальной «зоне влияния» на документ и сайт в целом».
Тестирование дает лишь первоначальный ответ на вопрос о важности факторов ранжирования. Мониторинг позволяет измерить взаимосвязь с течением времени и прийти к более надежным выводам.
Идея заключается в том, чтобы отслеживать метрики, отражающие факторы ранжирования, как CTR может отражать оптимизацию заголовков, и строить графики с течением времени, чтобы увидеть, приносит ли оптимизация плоды. Идея ничем не отличается от обычного (или того, что должно быть обычным) мониторинга, за исключением новых метрик.
Вы можете настроить мониторинг проекта в Пиксель Тулс, используя Группы URL, проводите тестирование, отслеживайте эффективность ваших доработок и масштабируйте результаты на весь домен.
Измерьте метрики по типу страницы или группе URL-адресов с течением времени, чтобы оценить влияние оптимизации. На какие метрики можно ориентироваться?
Одним из примеров является сопоставление заголовков исходных и целевых страниц для обратных ссылок. С помощью обычных SEO-инструментов мы можем получить заголовки, якорный текст и окружающий контент ссылки для ссылающейся и целевой страниц.
Затем мы можем оценить тематическую близость или совпадение маркеров с помощью распространенных инструментов искусственного интеллекта, интеграций Google Sheets/Excel или местных LLM и базовых подсказок типа «Оцените тематическую близость заголовка (столбец B) по сравнению с анкором (столбец C) по шкале от 1 до 10, где 10 — это абсолютно одинаково, а 1 — вообще нет связи».
Утечка данных о факторах ранжирования Google — не первый случай, когда внутренняя работа алгоритма крупной платформы становится достоянием общественности:
1. В январе 2023 года утечка из Яндекса раскрыла многие факторы ранжирования, которые мы также обнаружили в последней утечке из Google.
2. В марте 2023 года Twitter* опубликовал большинство частей своего алгоритма. Как и в случае с утечкой из Google, в нем отсутствует контекст между факторами, но, тем не менее, он был очень интересным.
3. Также в марте 2023 года глава Instagram* Адам Моссери опубликовал подробный пост о том, как платформа ранжирует контент в различных частях своего продукта.
Сергей Просветов, старший SEO-специалист команды Пиксель Плюс, считает:
Вопрос: «SEO мертво или еще нет?» в условиях утечки данных Яндекса и Google об алгоритмах ранжирования, играет новыми красками.
Не сказать, что информация «открыла Америку», тем не менее ряд пунктов подтвердили определенные догадки относительно влияния на ранжирование документа и сайта в целом.
В любом случае предстоит проверить информацию на практике и протестировать гипотезы с привязкой к полученным данным, чтобы удостовериться, что: «да, вот это действительно имеет место!
Не стоит игнорировать и тот факт, что официального подтверждения / опровержения со стороны Google (на момент написания статьи) так и не последовало, поэтому полностью отказываться от намеченных планов и стратегий продвижения не стоит, а внести корректировки в список задачи и приоритеты — вполне возможно!»
Игорь Хомяков, руководитель SEO-производства Пиксель Плюс, на вопрос «Открыли ли вы для себя что-то новое с данной утечки?», отвечает:
«Я бы сказал — расширил горизонты. Это как смотреть на мир через узкую щель, ты вроде бы видишь очертания предметов, движения каких-то тел, а что-то и целиком.
Общую же картину составляешь из части увиденного, домысленного. А потом тебе дают кольцевую пилу на 81 мм и ты делаешь круглое отверстие. Стал ли ты больше видеть? Безусловно. Увидел ли ты все? Конечно нет.
Чтобы увидеть весь мир, нужно снести это забор. А когда снесешь его, то всегда встанет вопрос: а как ты его понимаешь? И вот тут уже нужно работать с «заборами» в своей голове.»
Чем больше платформа поощряет вовлеченность в свой алгоритм, тем сложнее с ней взаимодействовать. И все же утечка информации об алгоритме Google весьма интересна, поскольку это платформа, ориентированная на намерения, где пользователи указывают на свои интересы через поиск, а не через поведение.
В результате знание ингредиентов для торта — это уже большой шаг вперед, даже если не знать, сколько каждого из них использовать.
На данный момент нет никаких веских доказательств того, что утечка данных действительно связана с Google Search. Существует огромное количество неясностей относительно назначения этих данных. Примечательно, что есть намеки на то, что эти данные являются внешним API для создания хранилища документов, как следует из названия и никак не связаны с тем, как сайты ранжируются в Google Search.
Вывод, что эти данные были получены не из Google Search, на данный момент не является окончательным, но именно в этом направлении дует ветер доказательств.
* Организации запрещенные на территории Российской Федерации.