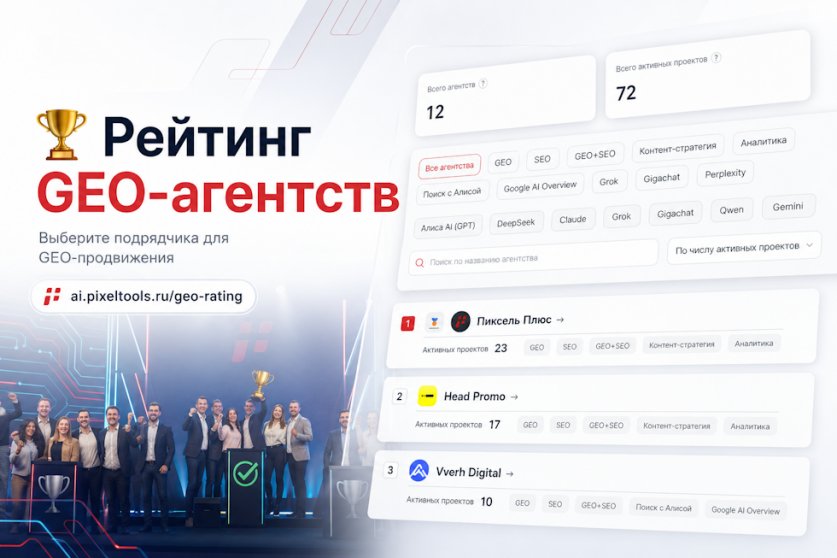
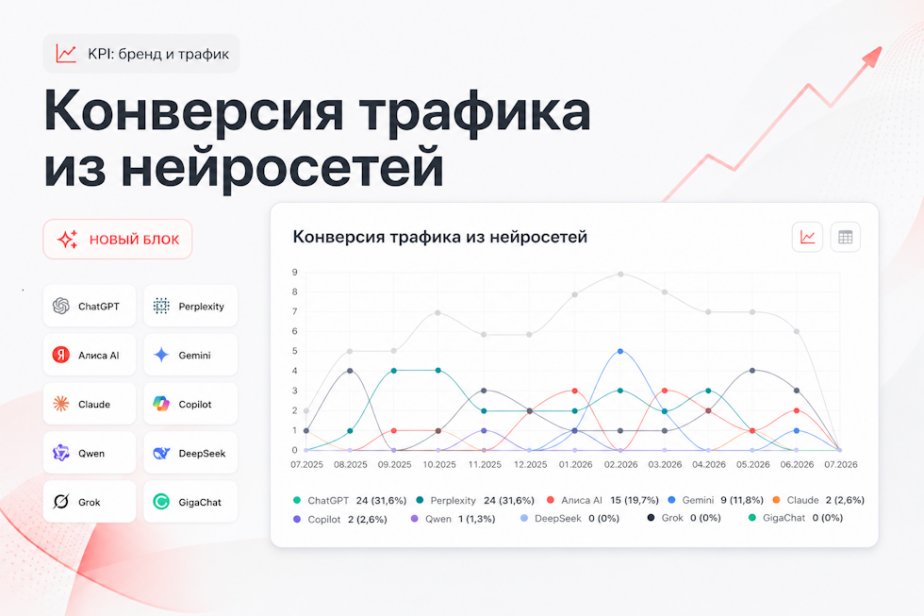
Пиксель Тулс опубликовал первый рейтинг факторов ранжирования в GEO. Девять экспертов оценили 43 фактора, которые влияют на видимость бренда в AI-ответах.
Применим ли семантический поиск в вашем бизнесе и маркетинговых планах, как вы можете использовать его в своих интересах?
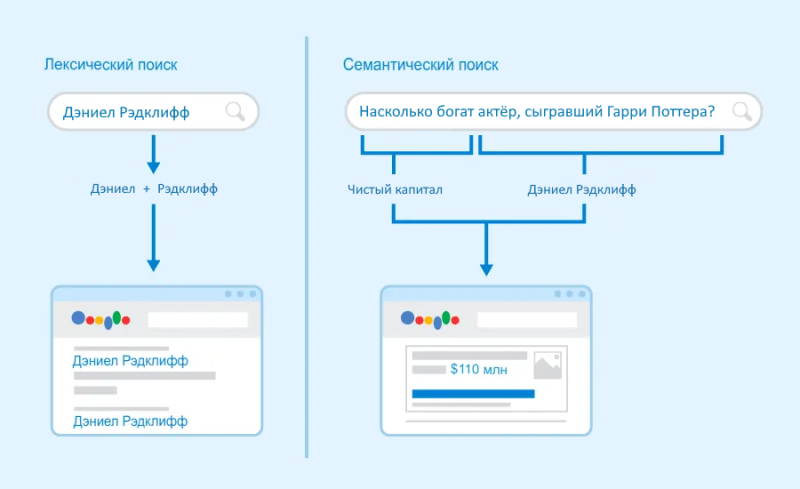
Для простых пользовательских запросов поисковая система может найти нужный контент, используя только подбор ключевых слов. Запрос «красный тостер» показывает все продукты со словом «тостер» в названии или описании и красным цветом в атрибуте цвета. Добавьте синонимы, например, «бордовый» и вы сможете найти еще больше вариантов тостеров.
Но всё усложняется, когда вам приходится добавлять разные синонимы самостоятельно и поиск продолжит выдавать тостеры. Здесь на помощь приходит семантический поиск.
Семантический поиск пытается использовать намерения пользователя и значение слов (фраз) для поиска нужного контента. Он выходит за рамки подбора ключевых слов, используя информацию, которая может не присутствовать непосредственно в тексте (сами ключевые слова), но тесно связана с тем, что хочет найти пользователь.
Например, поиск свитера по запросу «свитер» или «джемпер» не представляет проблемы для поиска по ключевым словам, в то время как запросы «теплая одежда» или «как согреть тело зимой?» лучше поддаются семантическому поиску.
Как вы уже поняли, попытка выйти за рамки поверхностной информации, заложенной в тексте, является сложной задачей. Её пытались осуществить многие, и она включает в себя множество компонентов.
Кроме того, семантический поиск — это термин, который иногда используется для поиска, который на самом деле не оправдывает своего названия. Чтобы понять, применим ли семантический поиск к вашему бизнесу и как лучше им воспользоваться, для начала, надо изучить как он работает и какие компоненты входят в семантический поиск.
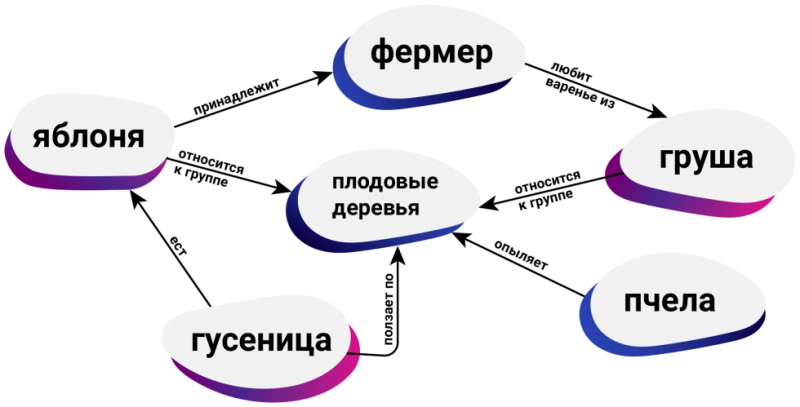
Семантический поиск использует намерения пользователя, контекст и концептуальные значения, чтобы сопоставить запрос пользователя с соответствующим контентом. Он использует векторный поиск и машинное обучение для выдачи результатов, которые направлены на соответствие запросу пользователя, даже если нет словесных совпадений. Эти компоненты работают вместе для получения и ранжирования результатов на основе смысла, чтобы максимально удовлетворить поисковый запрос. Одним из наиболее важных его компонентов является контекст.
Контекст, в котором происходит поиск, важен для понимания того, что пытается найти пользователь. Контекст может быть завязан на местности (американцу, ищущему «футбол» нужно что-то другое, чем британцу, ищущему то же самое) или состоять из нескольких факторов для обработки. Интеллектуальная поисковая система будет использовать контекст как на личном, так и на групповом уровне по отношению к пользователю.
Влияние на результаты выдачи на индивидуальном уровне называется персонализацией. Персонализация использует индивидуальные особенности пользователя, его предыдущие поиски и взаимодействия, чтобы выдать контент, который лучше всего подходит для текущего запроса.
Это применимо ко всем видам поиска, но семантический поиск может пойти ещё дальше.
На групповом уровне поисковая система может изменить ранжирование результатов используя информацию о том, как все поисковики взаимодействуют с результатами поиска, например, на какие результаты чаще всего нажимают или даже о сезонности, когда определённые результаты более популярны, чем другие.
Опять же, это показывает, как семантический поиск может привнести интеллект в поисковую выдачу, в данном случае, интеллект прослеживается через поведение пользователей. Семантический поиск также может использовать контекст в тексте.
Синонимы полезны во всех видах поиска и могут улучшить его по ключевым словам, расширяя соответствие запросов в начальной ключевой фразе. Но мы также знаем, что синонимы не универсальны — иногда два слова равны в одном тексте, но не равны в другом. Когда кто-то ищет «футболисты», каковы будут правильные результаты?
Ответ будет отличаться в Кенте, штат Огайо, от ответа в Кенте, Великобритания. Однако для запроса типа «футболисты Тампа Бэй» не нужно знать, где находится искатель. Добавление общего синонима, делающего американский футбол и футбол в Великобритании эквивалентными, привело бы к негативному пользовательскому опыту, когда искатель увидел бы футбольный клуб Тампа Бэй Роудиз (американский футбольный клуб) рядом с Роном Гронковски (игрок команды Нью-Ингленд Пэтриотс).
Конечно, если мы знаем, что пользователь предпочёл бы увидеть Tampa Bay Rowdies, поисковая система может принять это во внимание, но только при условии более раннего поиска информации по этому клубу. Это пример понимания запроса с помощью семантического поиска.
Конечная цель любой поисковой системы — помочь пользователю успешно выполнить поставленную задачу. Это может быть чтение новостных статей, покупка одежды или поиск документа. Поисковая система должна понять, что хочет сделать пользователь или каковы его намерения.
Мы можем увидеть такой вариант при поиске на сайте-агрегаторе или в крупный онлайн магазинах. Когда пользователь набирает запрос «jordans» поиск автоматически выдает категорию «Обувь». Это предвосхищает намерение пользователя найти обувь, а не миндаль компании Jordan (который находится в категории «Еда и закуски»).
Если вы хотите более точно понять интент того или иного поискового запроса, рекомендуем воспользоваться инструментом «Комплексная оценка запросов», который покажет 5 основных категорий поисковых интентов и поможет корректного сформировать семантическое ядро в соответствии с тематикой вашего сайта.
Таким образом предугадывая интент запроса, поисковая система может выдать наиболее релевантные результаты и не отвлекать пользователя элементами, которые совпадают по тексту, но не по релевантности. Это может быть тем более актуально, если применить сортировку поверх поиска, например, по цене от самой низкой до самой высокой.
Следующим будет пример категоризации запроса. Категоризация запроса и ограничение набора результатов гарантирует, что появятся только релевантные результаты. Мы уже рассмотрели способы, с помощью которых семантический поиск становится интеллектуальным, но стоит подробнее рассмотреть ещё и чем он отличается от поиска по ключевым словам.
Хотя поисковые системы по ключевым словам также используют обработку естественного языка для улучшения соответствия между словами, с помощью таких методов, как использование синонимов, удаление стоп-слов, игнорирование множественного числа — эта обработка всё равно опирается на соответствие между словами.
С другой стороны, семантический поиск может показывать результаты, где нет подходящего текста, но любой человек понимающий тематику, может увидеть, что есть очевидные совпадения. Это связано с большой разницей между поиском по ключевым словам и семантическим поиском, которая заключается в том, как происходит сопоставление между запросом и историей поиска.
Чтобы немного упростить ситуацию, поиск по ключевым словам происходит путем сопоставления текста. Слово «мыло» всегда будет соответствовать словам «мыло» или «мыльный» из-за схожего смыслового контекста. Если быть точнее, есть достаточно совпадающих букв (или символов), чтобы дать понять системе, что пользователь, ищущий одно, может захотеть увидеть и другое.
Это же соответствие подскажет системе, что запрос «мыло» является более вероятным совпадением со словом «мылась», чем слово «стиральный порошок».
Если только поисковой системе не сообщили заранее, что мыло и стиральный порошок являются эквивалентами, в этом случае при определении сходства поисковая система будет «считать», что стиральный порошок на самом деле является мылом.
Поисковые системы на основе ключевых слов также могут использовать такие инструменты, как синонимы, альтернативы или удаление слов из запроса — все виды расширения и ослабления запроса для помощи в решении этой задачи поиска информации.
Инструменты NLP (Natural Language Processing — обработка текстов на естественном языке) и NLU (Natural Language Understanding — понимание естественного языка) такие как возможность опечаток, токенизация и нормализация, также работают на улучшение поиска. Хотя все эти инструменты помогают получить улучшенные результаты, они могут не справиться с более интеллектуальным подбором и подбором по концепциям.
Поскольку семантический поиск основан на понимании запросов, поисковая система больше не может определять релевантность на основе количества совпадающих символов в словах. Опять же, подумайте о «мыле» в сравнении с «мылась» и «стиральный порошок». Или более сложные запросы, например, «средство для стирки», «удалить пятна с одежды» или «как вывести пятна от травы с джинсов?».
Похожим примером в реальной жизни этого может быть клиент, спрашивающий сотрудника, где находится «не засоренный унитаз». Сотрудник, понимающий этот запрос только по ключевым словам, не справится с просьбой, если только магазин явно не называет свои вантузы, сливные устройства и шнеки для унитаза «устройствами для очистки унитаза». Но мы надеемся, что сотрудник достаточно опытен, чтобы установить связь между различными терминами и направить покупателя в нужный отдел.
Кратко о том, что делает семантический поиск, можно сказать так: семантический поиск с помощью векторного поиска развивает интеллект, чтобы сопоставить понятия, а не слова. Благодаря этому интеллекту семантический поиск может работать в более человекоподобной манере, как, например, поисковик при запросе «вечерний наряд» выдаёт платья и костюмы, при этом в поле зрения не попадают джинсы.
К настоящему времени семантический поиск должен использоваться как мощный метод улучшения качества поиска. Поэтому вас не должно удивлять, что значение семантического поиска применяется всё шире и шире. Зачастую такой поиск не всегда оправдывает своё название.
И хотя официального определения семантического поиска не существует, мы можем сказать, что это поиск, который выходит за рамки традиционного поиска по ключевым словам. Для этого он использует знания реального мира, чтобы определить намерения пользователя на основе смысла запросов и контента.
Можно сделать вывод, что семантический поиск — это не просто применение NLP и добавление синонимов в индекс. Действительно, токенизация требует некоторых знаний реального мира о построении языка, а синонимы используют понимание концептуальных соответствий. Однако в большинстве случаев им не хватает искусственного интеллекта, который необходим для того, чтобы поиск поднялся до уровня семантического.
Именно это последнее обстоятельство делает семантический поиск одновременно мощным и сложным. Как правило, при использовании этого термина подразумевается, что в нём задействован определённый уровень машинного обучения. Почти так же часто речь идёт о векторном поиске. Векторный поиск работает путем кодирования деталей о предмете в векторы, а затем сравнивает векторы, чтобы определить какие из них наиболее похожи.
Опять же, даже простой пример может помочь. Возьмём две фразы: «Toyota Prius» и «стейк». А теперь давайте сравним их с «гибрид». Какие из двух первых фраз больше подходят ко второму слову? Текстуально ни одна из них не подходит, но вы наверняка скажете, что «Toyota Prius» подходит больше.
Вы можете так сказать, потому что знаете, что «Prius» — это тип гибридного автомобиля, потому что вы видели «Toyota Prius» в таком же контексте как и слово «гибрид». К примеру, «Toyota Prius — гибрид, который стоит рассмотреть» или «гибридные автомобили типа Toyota Prius». Однако вы совершенно уверены, что никогда не видели «стейк» и «гибрид» в подобном сочетании.
Именно так обычно работает и векторный поиск. Модель машинного обучения берёт тысячи или миллионы примеров из интернета, книг или других источников и использует эту информацию для последующего прогнозирования.
Конечно, для модели не представляется возможным перебирать сравнения одно за другим (часто ли Toyota Prius и гибрид встречаются вместе? А как насчет гибрида и стейка?), поэтому вместо этого модель кодирует закономерности, которые она замечает в различных фразах.
Это похоже на то, как вы можете посмотреть на фразу и сказать: «эта фраза положительная» или «в этой фразе есть цвет».
Только в машинном обучении языковая модель не работает так прозрачно, именно поэтому языковые модели сложно отлаживать. Эти кодировки хранятся в векторе или длинном списке числовых значений. Затем векторный поиск использует математику, чтобы вычислить, насколько похожи разные векторы.
Другой способ представить себе измерения сходства, которые проводит векторный поиск — это представить векторы в виде графика.
Это очень сложно, если вы попытаетесь представить себе вектор, построенный в сотнях измерений. Если вместо этого визуализировать вектор, изображенный в трех измерениях, принцип будет тот же.
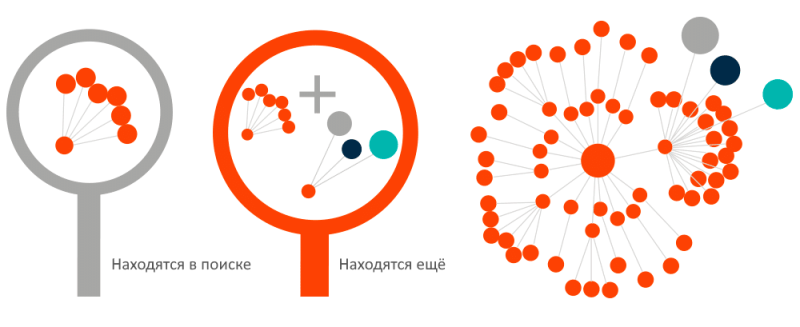
Эти векторы при построении образуют линию и вопрос заключается в том, какие из этих линий ближе всего друг к другу? Линии для «стейка» и «говядины» будут ближе, чем линии для «стейка» и «автомобиля», поэтому они более схожи.
Этот принцип называется векторным сходством. Векторное сходство имеет множество применений. Оно может давать рекомендации на основе ранее приобретенных продуктов, находить наиболее похожие изображения, а также определять, какие товары лучше всего соответствуют семантически по сравнению с запросом пользователя.
Семантический поиск — это мощный инструмент для поисковых приложений, который вышел на передний план с появлением мощных моделей глубокого обучения и аппаратного обеспечения для их поддержки.
Хотя мы затронули здесь ряд различных распространенных вариантов, существует еще больше систем использующих векторный поиск и ИИ.
Даже поиск изображений или извлечение метаданных из изображений может относиться к семантическому поиску.
И, тем не менее, его применение еще только начинается, а его известная мощь может привести к неправильному использованию этого термина. В конвейере семантического поиска есть много компонентов, и правильная работа каждого из них очень важна. Если все сделано правильно, семантический поиск будет использовать знания реального мира, особенно с помощью машинного обучения и векторного сходства, чтобы сопоставить запрос пользователя с соответствующим контентом.
Благодарим Дастина Коатс и коллег из Search Engine Journal за статью о редиректах, с оригиналом вы можете ознакомиться по ссылке.
Подписывайтесь на наш канал YouTube, чат Telegram и группу ВКонтакте, чтобы стать частью дружной SEO-тусовки.