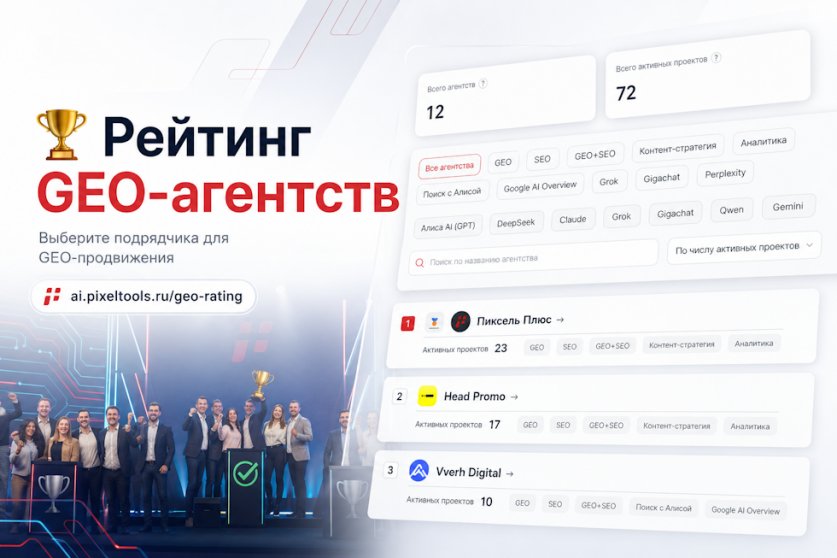
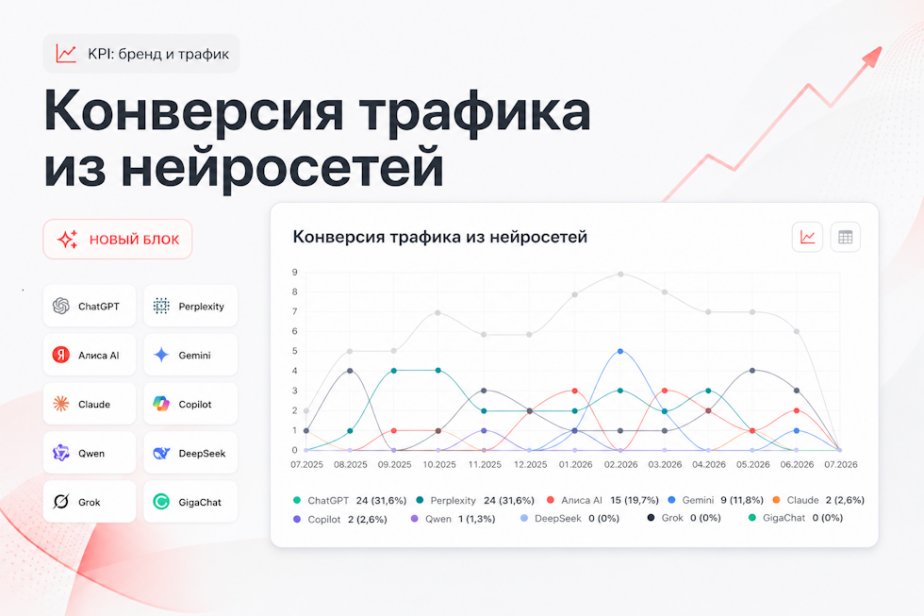
Пиксель Тулс опубликовал первый рейтинг факторов ранжирования в GEO. Девять экспертов оценили 43 фактора, которые влияют на видимость бренда в AI-ответах.
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
Мета-тег noindex, как наиболее эффективный способ удалить страницу из индекса.
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
https://tools.pixelplus.ru/robots.txt
https://www.mozilla.org/robots.txt
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
Примеры:
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта /api/ и /tmp/, несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
User-agent: *
Disallow: /tmp/
Disallow: /api/
User-agent: DuckDuckBot
Disallow: /duckhunt/
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
User-agent: *
# Закрываем раздел /cms и все файлы внутри
Disallow: /cms
# Закрываем папку /images/resized/ (сами изображения разрешены к сканированию)
Disallow: /api/resized/
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
User-agent: *
# Закрываем URL, начинающиеся с /photo после домена. Например:
# /photos
# /photo/overview
Disallow: /photo
# Закрываем все URL, начинающиеся с /blog/ после домена и заканчивающиеся /stats/
Disallow: /blog/*/stats$
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
User-agent: *
# Блокируем весь раздел /admin
Disallow: /admin
# Кроме файла /admin/css/style.css
Allow: /admin/css/style.css
# Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow: /admin/js/
Также Allow можно использовать для отдельных User-Agent.
# Запрещаем доступ к сайту всем роботам
User-agent: *
Disallow: /
# Кроме краулера Яндекса
User-agent: Yandex
Allow: /
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
User-agent: *
Crawl-delay: 5
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/blog-sitemap.xml
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Обратите внимание, правило для Disallow в этом случае не заполняется.
User-agent: *
Disallow:
User-agent: *
Disallow: /
User-agent: *
Disallow: /admin/
User-agent: *
Disallow: /admin/my-embarrassing-photo.png
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
# отредактированная версия robots.txt сайта IMDB
#
# Задержка интервала сканирования для ScouJet
#
User-agent:ScouJet
Crawl-delay: 3
#
#
#
# Все остальные
#
User-agent: *
Disallow: /tvschedule
Disallow: /ActorSearch
Disallow: /ActressSearch
Disallow: /AddRecommendation
Disallow: /ads/
Disallow: /AlternateVersions
Disallow: /AName
Disallow: /Awards
Disallow: /BAgent
Disallow: /Ballot/
#
#
Sitemap: https://www.imdb.com/sitemap_US_index.xml.gz
Общее правило — если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов.
User-agent: *
# /admin/js/global.js разрешён к сканированию
# /admin/js/update.js по-прежнему запрещён
Disallow: /admin
Allow: /admin/js/global.js
Может показаться, что файл /admin/js/global.js попадает под правило блокировки содержащего его раздела Disallow: /admin/. Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
| User-Agent | # |
|---|---|
| Googlebot | Основной краулер Google |
| Googlebot-Image | Робот поиска по картинкам |
| Bing | |
| Bingbot | Основной краулер Bing |
| MSNBot | Старый, но всё ещё использующийся краулер Bing |
| MSNBot-Media | Краулер Bing для изображений |
| BingPreview | Отдельный краулер Bing для Snapshot-изображений |
| Яндекс | |
| YandexBot | Основной индексирующий бот Яндекса |
| YandexImages | Бот Яндеса для поиска по изображениям |
| Baidu | |
| Baiduspider | Главный поисковый робот Baidu |
| Baiduspider-image | Бот Baidu для картинок |
| Applebot | Краулер для Apple. Используется для Siri поиска и Spotlight |
| SEO-инструменты | |
| AhrefsBot | Краулер сервиса Ahrefs |
| MJ12Bot | Краулер сервиса Majestic |
| rogerbot | Краулер сервиса MOZ |
| PixelTools | Краулер «Пиксель Тулс» |
| Другое | |
| DuckDuckBot | Бот поисковой системы DuckDuckGo |
Как упоминалось выше, широко применяются два оператора: * и $. С их помощью можно:
1. Заблокировать определённые типы файлов.
User-agent: *
# Блокируем любые файлы с расширением .json
Disallow: /*.json$
В примере выше астериск * указывает на любые символы в названии файла, а оператор $ гарантирует, что расширение .json находится точно в конце адреса, и правило не затрагивает страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром ?, после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
User-agent: *
# Блокируем любые URL, содержащие символ ?
Disallow: /*?
Заблокировать результаты поиска, но не саму страницу поиска.
User-agent: *
# Блокируем страницу результатов поиска
Disallow: /search.php?query=*
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
User-agent: *
# /users разрешены для сканирования, поскольку регистр разный
Disallow: /Users
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Контроль изменений в файле robots.txt. Теперь точно не упустите, если кто-то из коллег закрыл сайт от индексации (или наоборот).
Держите свои robots.txt в порядке, и пусть в индекс попадает только необходимое!