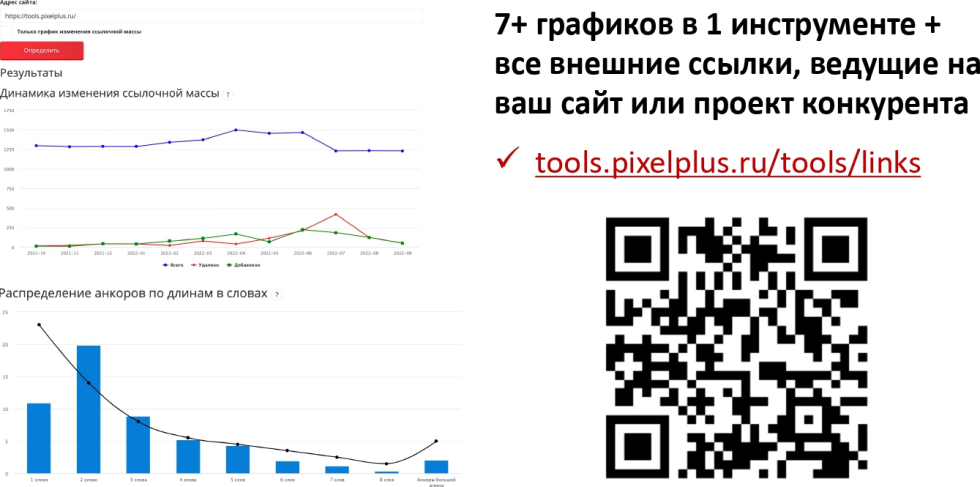
Какие факторы при анализе сайтов конкурентов сделают SEO еще более эффективным в Яндексе и Google. Пошаговая инструкция, а также шаблоны и инструменты для удобного анализа поисковой выдачи.
Сегодня мы будем говорить о новом алгоритме Яндекса — Y1. Поговорим о том, как продвигать сайты в условиях этого алгоритма, который был запущен в 2021 году.
Мы знаем, что это новая версия поиска Яндекса, которая объединяет более 2000 улучшений. В её основе лежат две мощные технологии, связанные с машинным обучением, с такими привычными для Яндекса вещами, как глубинные нейросети-трансформеры, а также алгоритмы YATI и YALM (Yet another Language Model). По сути дела, это объединение разных фич: быстрых ответов, поиска внутри видео, оценки по отзывам, визуального поиска, повышения безопасности и других.

Немного ностальгии. Говоря о новом алгоритме Y1, вспоминается то время, когда Яндекс выкатывал новую версию алгоритма на бета-версию «buki», мы могли его посмотреть и потестировать. Наверняка многие из вас не спали ночами и пытались разобраться, как ранжируется сайт в этой новой версии поиска. В ней не было никаких сервисов съёма позиций, всё проверяли и сравнивали руками. Сейчас, конечно, всё иначе, да и речь уже совсем о другом алгоритме. Сегодня мы попробуем разобраться в этой теме и понять, какая доля в новом алгоритме Y1 — это реальные улучшения в поиске, а какая — доля пиара.
На повестке дня следующие вопросы: что реально поменялось и когда, что такое YALM и как с ним жить. В конце мы дадим 7 практических рекомендаций, которые позволят лучше продвигать ваши сайты в условиях нового алгоритма.
Для начала нужно разобраться, а был ли апдейт? Понятно, что мы можем посмотреть, когда выходил алгоритм, в какое время был анонс, и увидеть, что нет никакого фактического изменения в датах, которыми должен был сопровождаться алгоритм.
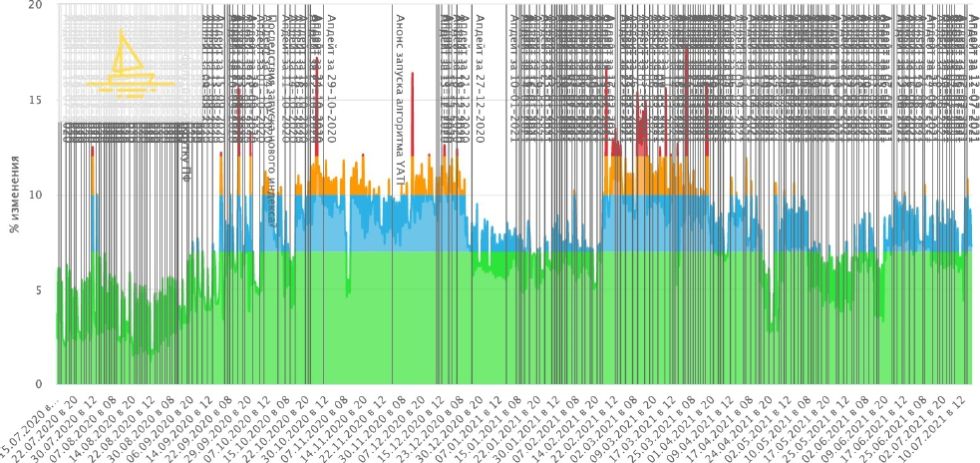
В показанном промежутке нет значительных изменений — напротив, есть определенная просадка, есть ощущение, что поиск немного затомился. Гораздо больше этих изменений было не 10 июня, когда был анонс алгоритма, а в феврале-марте. Безусловно, единой даты выхода нового алгоритма Y1 не было. Рандомизированно выбирается 2% из всей целевой аудитории, которая приходит на поиск, им показывают какие-то эксперименты. Если всё идёт хорошо, набираются какие-то поведенческие характеристики, доли постепенно увеличиваются, происходит выход в реальности.
Но если посмотреть динамику в интервале 1-1,5 лет в сводке по Яндексу, то можно заменить определенные подвижки, на которые стоит обращать внимание SEO-специалистам и владельцам бизнеса.

Если раньше на поддоменах мало что могло нормально ранжироваться, то сейчас доля растёт — за год в ТОП-10 она увеличилась на 29%. Продолжающееся старение выдачи — не самый оптимистичный момент, но на сегодняшний момент средний возраст документов в Яндексе — 4,74 года. В апреле изменилась длина Title и Description на 2 символа — это большая редкость и знаменательное событие, которое многие не заметили. Что касается HTTPS, можно с уверенностью сказать, что он победил — доля составляет 97,2%, а также внутренние страницы стали ранжироваться лучше. Доля главных страниц в ТОП-10 постепенно снижается со временем — это говорит о том, что поисковая система всё лучше и лучше начинает разбирать интент. В результате лучшего понимания интента поисковая система лучше разводит трафик. В ряде случаев это может приводить к объединению кластеров запросов, в других — к распаду кластеровых запросов, которые можно было бы продвинуть на одной странице на несколько URL-адресов.
Первое, на что делает акцент нейронная сеть YALM — языковая модель, которая может генерировать запросы и вопросы, которые близки к пользовательским. Если вы напишите в Яндексе «что такое SEO», то она сгенерирует близкие по смыслу запросы «что такое SEO простыми словами», «что такое SEO текст» и другие.
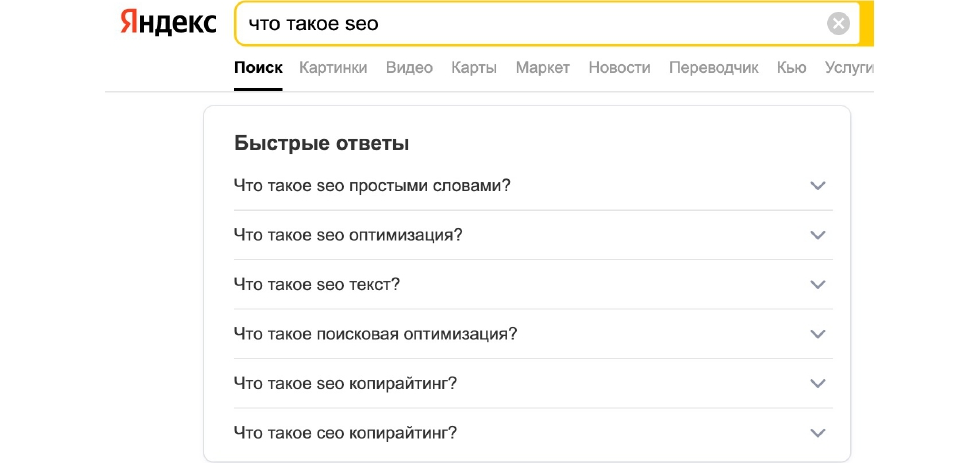
То есть, автоматически генерируется большое количество запросов, которые подтягиваются с других сайтов. Задача по генерации этих запросов ложится на нейронную сеть. Потестировать новые возможности можно в сервисе «Балабоба». Думаем, уже многие начали брать оттуда тексты и генерировать на них дорвеи. Интересно, как будет реагировать поисковая система на такие естественные с точки зрения языка тексты.
Нужно сказать, что расширенные ответы были уже в 2011 году, но сейчас их количество резко увеличивается. У Яндекса продолжается тренд замыкания трафика на себя. Вот свежий пример с расширенными карточками:
Нейросети, машинное обучение и искусственный интеллект начинают распространяться абсолютно во все сферы: распознавание речи, лиц, диагностика заболеваний, игры, управление автомобиля, кредиты и другие.
На что способен искусственный интеллект? Технологии распознают:
что изображено на картинке или видео;
какой текст произносит спикер в видеоролике;
куда ведут ссылки, которые вы показываете в видео.
Может быть, когда-нибудь будут индексироваться и те ссылки, которые произносит человек на видео. На сегодняшний момент мы имеем довольно неплохое понимание структуры видео.
Продолжаются массовые баны за накрутку ПФ, хотя технически называть их банами не совсем корректно. Те, кто привык подходить к продвижению академическим образом, сказали бы, что это не бан, а пессимизация, так как сайты остаются в индексе.
За последний год мы наблюдаем такую картину:
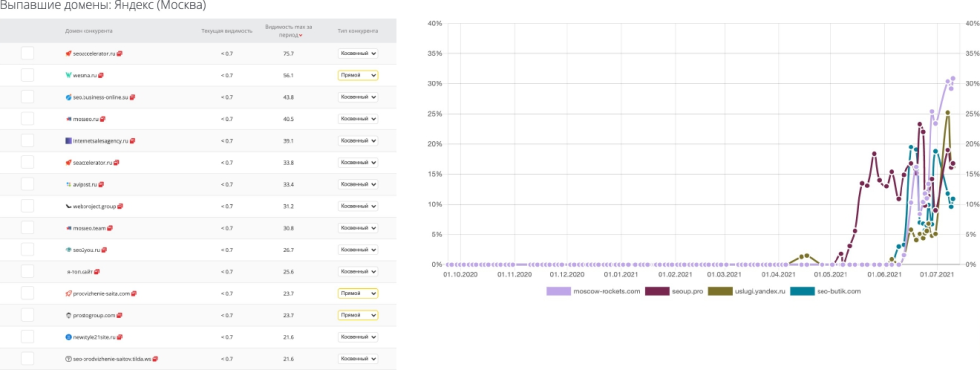
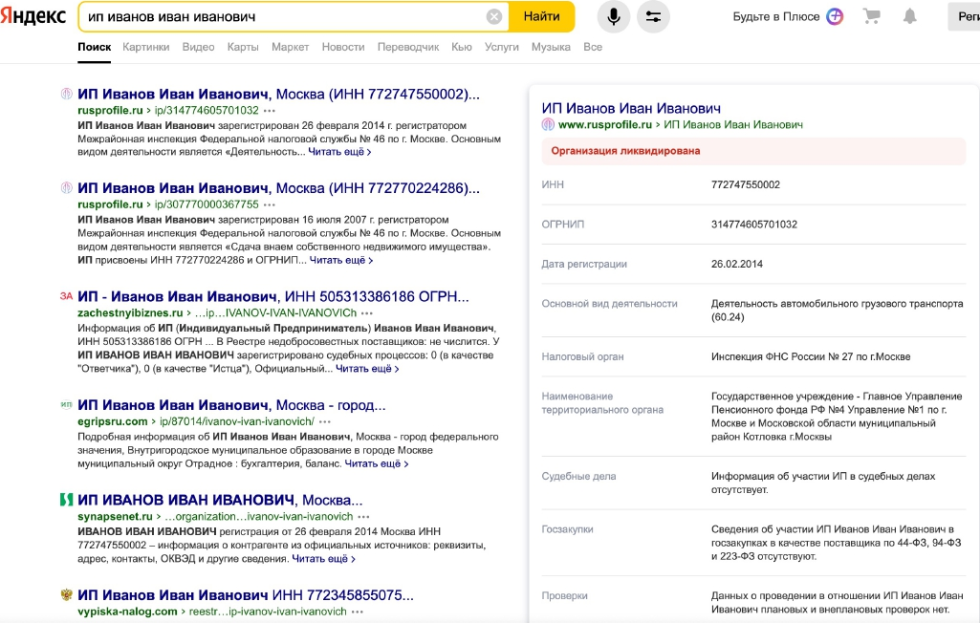
Более 35 проектов были пессимизированы за последний год только в одной тематике создания и продвижения сайтов, на изображении выше вы можете видеть список этих проектов. А вырастают ли новые головы на месте отсечённых? Как показано на картинке справа — да, есть проекты, которые динамично и стремительно растут с нуля. Например, moskow-rockets.com, seoup.pro, seo-butik.com — такие «знаменитые» сеошные агентства, о которых вы точно также слышите впервые. Мы не можем со стопроцентной уверенностью утверждать, что эти сайты накручивают ПФ, но даём 95%, что это именно так.
Удивительно, но факт — поддомен uslugi.yandex.ru тоже выглядит как накрутчик поведенческих факторов. Его внезапный рост очень неочевиден. Но здесь, естественно, история может быть совершенно другой.
Главная наша мысль заключается в том, что поисковые системы и крупные компании, как Google, IBM, Facebook, Яндекс стали адептом распространения машинлёрнинга. Это подтверждает зарождение новой религии, в которую начинает верить человечество — дадаизм. Мы постепенно оцифровываем все данные, в том числе сигналы от самых разных предметов, внедряем систему «Умный дом» и т.д. Всё это попадает в какие-то выборки. Считается, что удалять данные это кощунство, поэтому мы храним их бесконечно.
Со временем это приводит к тому, что мы начинаем доверять машине принятие тех решений, в которых раньше участвовал только человек. Например, на вопрос «что посмотреть сегодня вечером», вам не нужно выбирать самим — машина сама выберет оптимальный фильм или передачу после нажатия кнопки «плэй». Возможно, через некоторое время это уже будет не просто выбор фильма, а ответ на вопрос, что вообще делать вечером. Например: вам нужно прогуляться 15 минут пешком, поесть такое-то блюда и т.д.
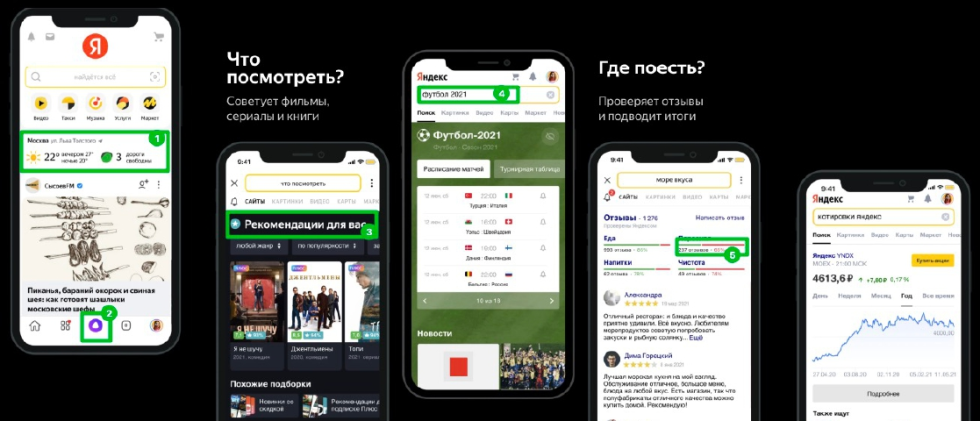
Давайте посмотрим на поисковую выдачу в экран смартфона — что здесь отвечает за машинное обучение:
Яндекс погода;
Яндекс пробки — машина анализирует трафик, делает прогнозы и строит оптимальный маршрут с их учётом;
Яндекс Алиса;
рекомендательные системы;
фильтрация отзывов и т.д.
Всё это построено на алгоритмах, связанных с машинным обучением.
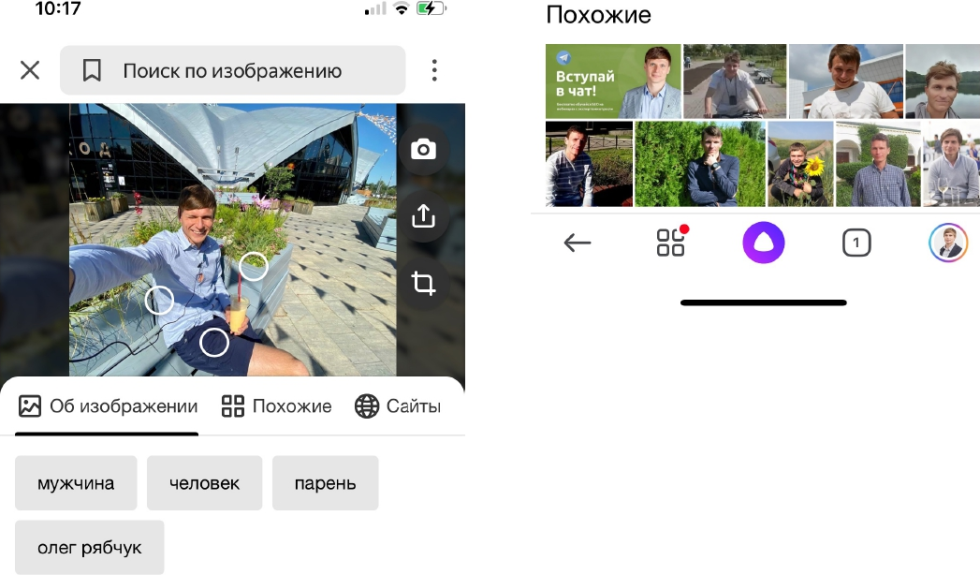
Я загрузил свою фотографию в Алису и узнал, что я — парень, мужчина, человек. А еще она предположила, что моё имя — Олег Рябчук. Таким образом, вы можете находить людей, которые на вас похожи. Довольно забавно.
Постепенное закручивание и выход в сторону отзывов, рейтингов и оценки бизнеса с точки зрения коммерческих факторов ранжирования, но уже связанных с этими отзывами и рейтингом.
О чём идёт речь:
Рейтинг магазинов по отзывам прямо в поиске. Служба контроля качества проверяет отзывы и удаляет нечестные и бесполезные.
Фильтрация мошеннических сайтов. Тех, кто мимикрирует под банки и платежные системы.
Отзывы о сайте в адресной строке. Соотношение положительных и отрицательных отзывов и его влияние на ранжирование.
Мы рассказали о пяти основных изменениях, но хотелось бы упомянуть про некий +1 — СНСС продолжает жить. То есть ссылки продолжают работать и всё в этой среде ок.
Игрушка «балабоба» с нейронной сетью YALM найдена по ссылке. Раньше с помощью этой надписи можно было диагностировать отключение и включение ссылочного по запросам. А ещё раньше — пробивать анкор-листы. В принципе, и сейчас остались определённые комбинации составления поискового запроса и get-параметров в поисковую систему Яндекс с целью повышения количества сайтов, найденных по анкор-листу. То есть у нас есть возможность хотя бы косвенно заглядывать в анкор-лист документов, хотя, на наш взгляд, теперь это не несёт никакой практической ценности.
Подводим итог первой части. Мы рассмотрели пять основных изменений, на которые делают акцент сами разработчики поисковой системы, авторы алгоритма. Переходим ко второй части — разбор архитектуры нейросетей трансформеров YALM.
Нейронная сеть, некий алгоритм Яндекса, который может генерировать текст (слово за словом), с заданными на входе параметрами. У него достаточно широкое применение:
создание подзаголовков для объектных ответов;
ранжирование сниппетов для быстрых ответов;
генерация ответов для Алисы.
Например, когда у нас есть расширенный блок для ответов, то формирование заголовка, оптимального названия делает эта новая нейронная сетка.
Ранжирование сниппетов для быстрых ответов, что это значит? Вообще, сниппет можно составит по-разному, но можно посмотреть, какой сниппет лучше соответствует запросу. Считается, что фактор, который оценивает соответствие новой яндексоидной языковой модели, вносит львиный вклад в ранжирование сниппета, отображение текстовых описаний и вывод тех, что наиболее подходят по поисковому запросу в Яндексе.
Что касается «Алисы», это история на стыке речевых технологий и ранжирования. Имеет отношение к ранжированию в выдаче, но больше относится к генерации текста «слово за словом».
Языковые модели использовались в поиске давно. Уже не менее 10 лет они применялись для вычисления текстовой релевантности и не только.
Что рассматривается:
Униграммная языковая модель для документа с учётом зоны встречаемости слова. Рассматривались разные вероятности того, что Title нормально составлен, текст написан человеком, а не сгенерирован автоматически, соответствует обвязка и верхняя часть.
Языковая модель «с окошком N слов», учитывающая удаление от начала страницы. Например, берем окошко 20 слов, бежим по тексту и оцениваем, насколько эти текстовые фрагменты соответствуют языковой модели. При этом вводим какую-то весовую функцию с убыванием от начала страницы. Чем более глубоко текст на странице, чем ниже он находится, тем меньшую роль играет.
Классификация документов и сайтов по тематикам. Мы можем посмотреть, какой тематике соответствует этот набор слов и терминов, которые встречаются на странице, довольно детально классифицировать документы.
Переход от униграммных языковых моделей к «более сложным» прогнозируемо должен был повысить качество информационного поиска, хотя это довольно неочевидная вещь.
В общем и целом, поисковые системы идут в сторону того, что они прокачивают и формируют всё более грамотные языковые модели, которые можно применять в поиске.
Перейдем к тому, какие цели преследовали разработчики YALM. Как мы уже говорили ранее, это — языковая модель на архитектуре Трансформерс (как YATI).
Главная цель YALM — получить связанный грамматически правильный текст ответов для Алисы, для генерации заголовков и расширенных ответов.
Главная особенность — модель может учиться новой стилизации, умеет генерировать тексты для новостей, заголовков, пиара и рекламных объявлений, обучаясь на небольшом количестве примеров.
Используется для генерации заголовков объектных ответов, оценивает качество сниппетов для быстрых ответов, сочиняет ответы для голосового ассистента Алисы. Быстрая гибкость этой модели является основной отличительной способностью.
Факторы, посчитанные с помощью алгоритма нейронных сетей (YATI), являются одними из общей совокупности тех факторов, которые используются для построения итоговой формулы ранжирования (CatBoost).
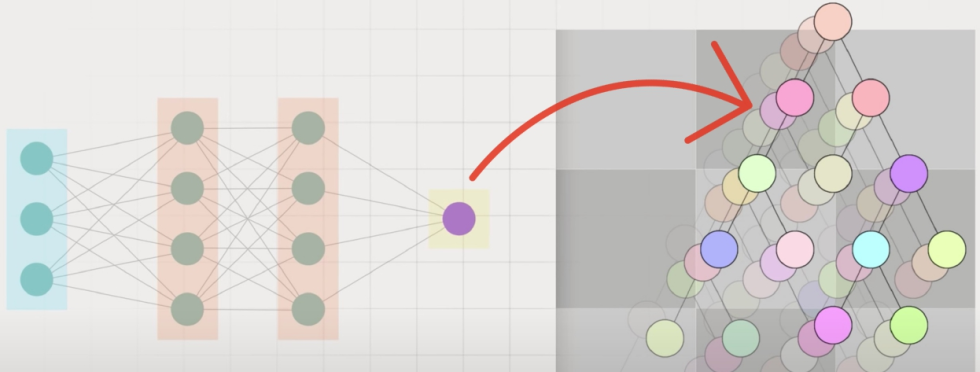
Изначально, это некоторый фактор, который загружается и уже идет в построение итоговых решений. Важно понимать, что не сама нейронная сеть строит какое-то ранжирование, а это является одним из факторов.
Когда мы разобрали, что такое YALM, можно переходить к практическим рекомендациям, которые будут полезны в 2021 году. Советы основаны на изменениях в выдаче и анализе той информации, которая была в анонсах.

Вы можете сказать, что Y1, конечно, крутая вещь, но как использовать её для продвижения своего проекта? Пришло время перейти к конкретике.
Об этом разработчики намекают достаточно прозрачно и понятно. Важно повышать рейтинг сайта, который сказывается на ранжировании и конверсии. Можно посмотреть количество оценок и отзывов о сайте, например, через Яндекс.Вебмастер.
Что нужно смотреть:
есть ли у сайта отзывы в принципе;
какое соотношение положительных и отрицательных;
отвечает ли владелец сайта на отзывы.
Это дополнительный пункт в чек-листе SEO-специалистов, который также следует оценивать и смотреть на текущий момент. Мы можем сказать, что конкурентные сайты в популярных тематиках имеют достаточно хороший рейтинг.
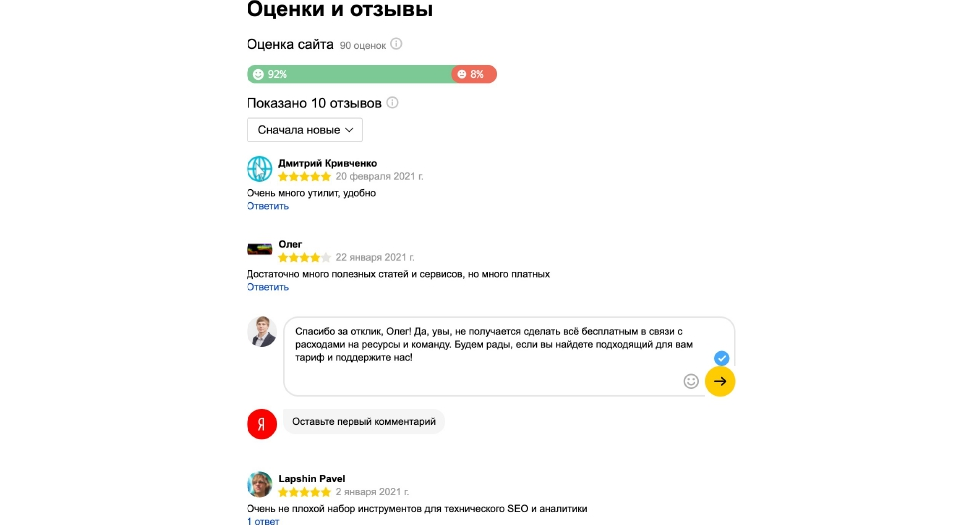
Мы ещё не смотрели корреляцию на большой широкой выборке, но если вам это интересно, сделаем это обязательно на следующих вебинарах.
Эта история была и продолжает сохранять актуальность с запуском YATI. Рекомендация заключается в следующем — сбор окружения тематики и слов у конкурентов. Мы берем инструмент Пиксель Тулс оптимизации ТЗ для копирайтера, парсим выдачу конкурентов по списку поисковых запросов, которые вы хотите продвигать в рамках этой страницы, смотрим, какие у них встречаются N-граммы — какие последовательности слов встречаются у конкурентов, в каком количестве.
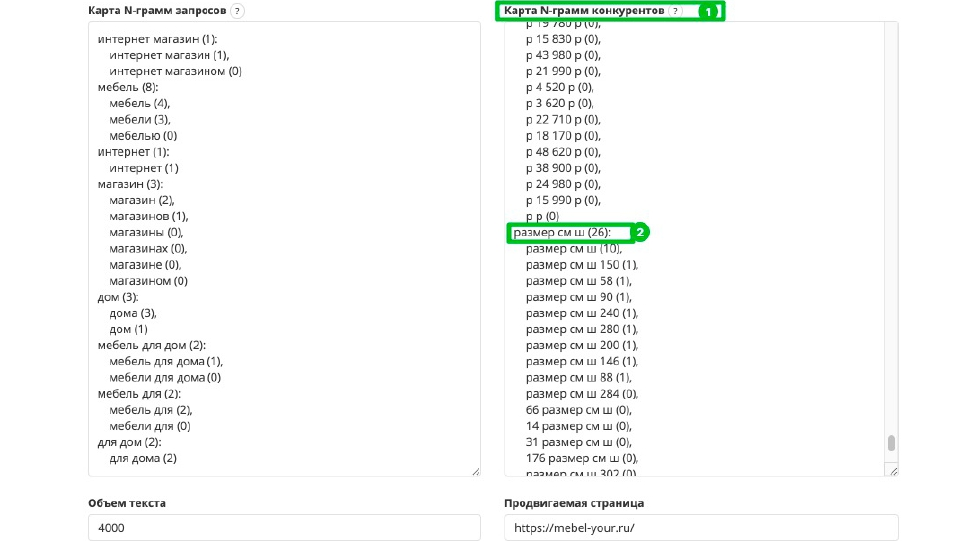
Причём, это не всегда слова из поисковых запросов и не синонимы ключей, а именно дополнительные, которые являются окружением. В данном случае, окружение будет самым точным и уместным термином. Все это делается с помощью того же инструмента «ТЗ на копирайтинг». Здесь можно провести аналогию с уже знакомым многим LSI, расшифровывается как латентная семантическая индексация. Действительно, смысловая нагрузка, тот самый LSI, и окружение поисковых запросов в ряде случаев побеждают вхождение ключевых фраз, но это достаточно редкие кейсы.
Это один из наиболее важных моментов для SEO-специалистов, которые нужно делать сейчас и сегодня. Самое время составить новое распределение! С 70% вероятностью ваша текущая группировка, после того как было внесено достаточно большое количество изменений, устарела.
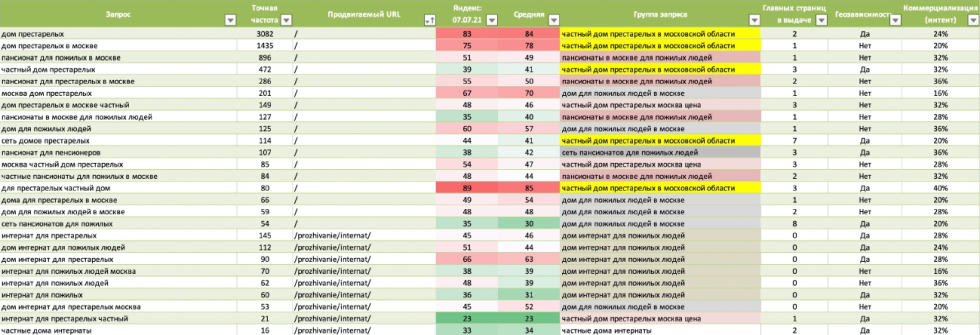
Для тех, кто только недавно присоединился к сеошному движению и пока не слишком разбирается в терминологии даём ссылку на инструмент для оценки и группировки запросов. Распределение — это таблица, в которой содержится поисковый запрос, по которому вы хотите попасть в выдачу и страницы, которые должны быть в выдаче с вашего сайта — главная или внутренние. Остальные колонки содержат дополнительные параметры, которые тоже могут быть полезны. Настоятельно рекомендуем заняться перегруппировкой сразу после прочтения, так как скорее всего вы продвигаете те документы, которые продвинуть уже нельзя.
Советуем добавлять на сайт максимальное количество блоков, содержащих ответы на вопросы. У вас есть реальная возможность погнаться сразу за тремя зайцами и всех их поймать:
Вы повышаете текстовую релевантность, плюс здесь есть небольшой лайфхак. Опираясь на наш опыт и ощущения, антиспам-алгоритмы не очень внимательно смотрят на вхождения ключевых фраз и очевидный переспам в этих блоках. Вы можете догнаться процентным вхождением и количеством ключевых фраз, не словив текстовые фильтры.
У вас есть возможность привлечь показы и трафик по смежным запросам. Такие блоки делаются довольно часто, ответы с различных сайтов выдёргиваются тоже динамично, и практически по любому информационному запросу можно найти блоки FAQ, тем самым трафик на них повышается.
Улучшение кликовых поведенческих факторов. По сути, за счёт внедрения микроразметки FAQ на все страницы, которые у вас есть в принципе, улучшить и ранжирование, и трафик.
Очень крутая вещь, советуем внедрять и пользоваться. Как говорят, ответов много не бывает. Тем более, что преимущества их очевидны.
Под этим мы подразумеваем классические факторы, роль которых сейчас крайне весома. Казалось бы, с внедрением нейронных сетей и пониманием смысла все факторы типа вхождения ключевого запроса в Title в текст должны просто умирать — но этого не происходит. В реальности картина следующая:
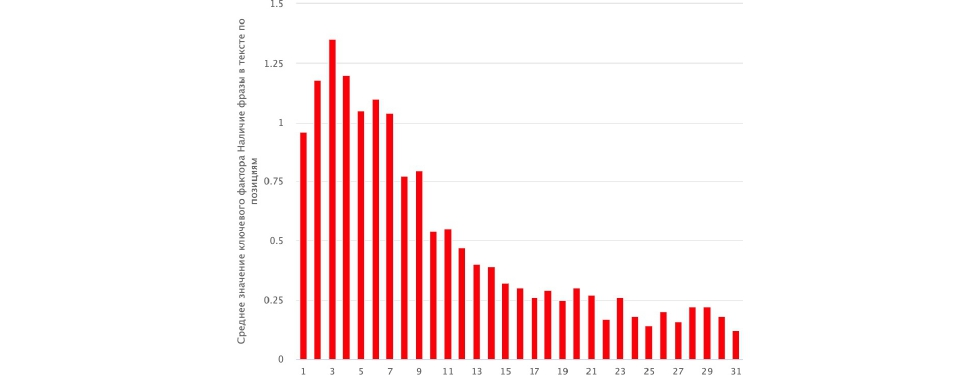
У нас точное вхождение запросов в текст. На первом месте есть некоторое западение, связанное с тем, что выборки не отфильтрованы — есть брендовые запросы, витальные ответы и т.д. Начиная с третьей позиции и далее, среднее значение фактора резко падает. Это означает, что есть очень сильная корреляция между наличием точного вхождения и позицией. Это НЧ фраза с частотой до 30 «Яндекс Москва (десктоп)».
Вторая история:
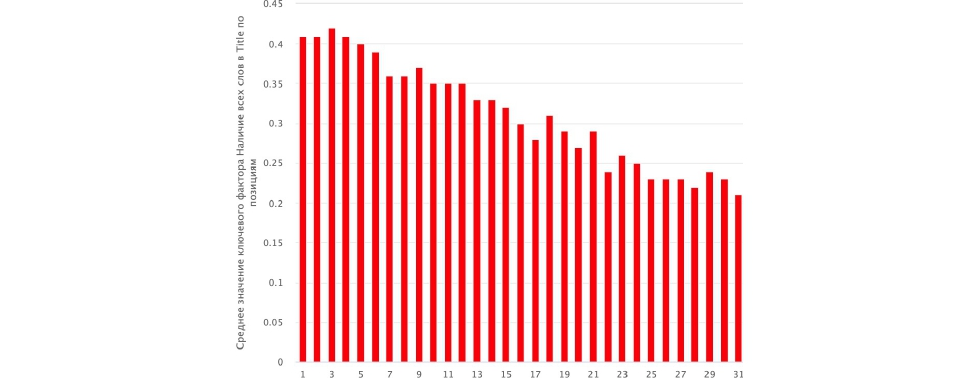
Здесь плавное убывание, среднее значение фактора тоже не единица. Мы видим значение 0,4 — это значит, что в среднем 40% на первых местах. Затем следует резкое убывание, с ухудшением выдачи у нас все меньше и меньше слов из поисковых запросов содержится в теге Title. Мы не фильтровали 4-5 слов или 5-6 слов — это просто низкочастотная выборка. Есть смысл посмотреть на графиках отдельно 2-5 слов и больше.
Эти графики выглядят убедительнее корреляции, которую мы проводили два года назад. Делаем отсюда вывод, что классика никуда не делась, нужно продолжать оптимизировать.
Здесь терминология плавающая — кто-то называет запросным индексом те запросы, по которым были переходы на конкретный URL-адрес, кто-то им запросы, по которым были показаны конкретные URL-адреса, кто-то подразумевает клики на сайт и показы сайта. То есть существует четыре разных сводки, которые называют запросным индексом. Нужно, как минимум, различить показы и клики, чтобы терминология была более устоявшейся — возможно, у вас будут варианты для обозначения и чёткого разграничения.
В YATI много внимания уделяется запросному индексу документа, можно оценивать весь сайт.
Анализируйте и оптимизируйте запросный индекс для документов (Яндекс.Вебмастер — Поисковые запросы):
Изучите поисковые запросы, по которым были зафиксированы переходы на URL, они должны быть релевантными!
Проверьте релевантность запросов, по которым были показы, но не было переходов. Нерелевантные фразы? Примите меры!
Работать с поисковыми запросами нужно не только в рамках конкретной страницы, но и в масштабах всего сайта.
Многие факторы, которыми оперирует YATI, (а значит и Y1) удовлетворяются автоматически при грамотной проработке спроса. То есть расширение высокочастотки в сторону низкочастотки, но более масштабное, чем синонимы. К примеру, вы продвигаетесь по запросам «seo продвижение» или «продвижение сайта в Москве» — это поможет продвижению и соответствию языковой модели по таким запросам как «продвижение сайтов», «smm продвижение».
Есть такой блок, который выводится в Яндексе:

Можно брать эти расширения и синонимичные запросы из выдачи, здесь всё очень легко и понятно.
Есть еще один бонусный совет в нагрузку к предыдущим семи — чаще смотрите на выдачу. Все специалисты чаще смотрят SERP через призму инструментов, а не своими глазами.
Пример:
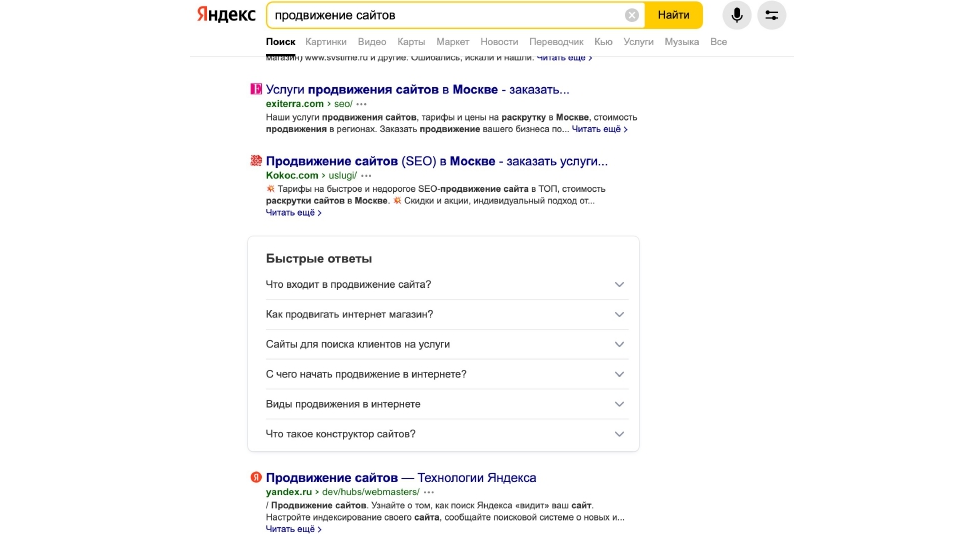
По запросу «продвижение сайтов» мы можем увидеть блок быстрые ответы, а также посмотреть, какие вопросы сгенерировала языковая модель. Яндекс создал чек-листы — «Продвижение сайтов-Технологии Яндекса», при этом отжав одну страницу по запросу. Но вообще, полезно смотреть выдачу, как минимум по 3-4 запросам, которые вам знакомы. Можно набирать рандомные фразы и ВЧ-запросы из семантики.
Наверное, многие из вас пришли к выводу, что в итоге нужно опять оптимизировать сайты и вроде как ничего нового. Если вы чувствуете какое-то западение мотивации, приглашаем присоединиться в телеграм-канал «FillUpYourSelf». Очень надеемся, что он поможет вам найти мотивацию.
Ключевые выводы:
Поисковые алгоритмы постоянно меняются. Среднее количество небольших изменений — более 5 в день, к этому нужно адаптироваться.
SEO-специалисту важно отличать PR-заявления в пресс-релизе от реальных изменений в ранжировании. Мы должны разбираться в том, что говорит Яндекс, и что происходит в реальности.
Классические факторы ранжирования играли, играют и будут играть крайне важную роль для SEO, что объясняется их фундаментальной природой. Что может говорить лучше о соответствии страницы поисковому запросу, чем вхождения слов из этого поискового запроса в текст страницы? Это фундамент, природа, это никак не может перестать учитываться.
Машинное обучение — теперь везде.
Если бы мы отвечали на вопрос, какая доля в Y1 реальных изменений и пиара, то 80% — это пиар и только 20% — реальные изменения. Как оказалось, никакой глобальной революции в поиске не произошло, больше всё это похоже на пиар. Как будто Y1 просто надо было сделать, поскольку будет больше новостей о компании. Хотя, конечно, была проделана работа с определёнными технологиями.
Какие две технологии объединяет новый алгоритм Y1?
Перечислите не менее трёх наиболее важных изменений, которые мы можем наблюдать в результатах выдачи в результате запуска нового алгоритма?
Назовите не менее 5 наиболее важных SEO-работ, которые требуется провести сейчас после запуска Y1?
Может ли изменение алгоритма ранжирования вести к необходимости корректировки файла распределения сайта и почему?
Чтобы не пропускать новые материалы, подписывайтесь на наши группу ВКонтакте, чат Telegram и канал YouTube.