Брендинг в эпоху нейросетей: как технологии меняют подход к созданию идентичности
Сегодня мы поговорим о новом алгоритме Яндекса, который запустился в 2020 году — YATI. Расскажем, как он влияет на поисковую оптимизацию, как к нему адаптироваться и нужно ли это делать в принципе. Также мы разберем ряд интересных теоретических подводок, посвященных происхождению этого алгоритма, какие шаги сделали поисковые системы, чтобы к нему прийти. Является ли Яндекс догоняющим относительно Google или наоборот, Google опережает и задает тренды.
В 2020 году Яндекс анонсировал одно изменение алгоритма, это была технология YATI — «архитектура нейросетей-трансформеров», которая призвана повысить качество понимания «смысла» текста с точки зрения поисковой системы. Аббревиатура YATI является сокращением английской формулировки Yet Another Transformer with Improvements. То есть это некоторая архитектура нейронных сетей, которые называются «трансформерами» с определенными улучшениями. Она предложена поисковой системой Яндекс в качестве некоторой доработки архитектуры трансформеров, которая достаточно широко используется для решения задач компьютерной лингвистики и понимания естественного языка.
По большому счету, в этом нет ничего суперсложного с точки зрения нашего понимания. В разрезе SEO это новый фактор, который играет существенную роль в ранжировании. Что такое нейронные сети? В этом тоже нет ничего запредельного. Это некий метод машинного обучения, способ извлечения из машины знаний, исходя из загруженной информации. Кроме того, это попытка оценки «смысла» страницы и ее близости запросу.
Возникает вопрос, зачем все это нужно? До 2016 года до 95% всей текстовой информации на страницах никак не учитывались поисковой системой Яндекс, то есть они просто существовали. Конечно, были некоторые попытки — языковые модели, латентное семантическое индексирование, но фактически, поисковая система видела текст приблизительно так:
Цветным шрифтом выделено то, что она каким-то образом воспринимает. То есть по запросу «что такое SEO» она понимала заголовок, понимала вхождение слова «SEO», некоторые синонимы, так называемые «костыли» — «engine optimization», СЕО и т.д. При этом большинство текста, который находится на слайде без цветного выделения, просто не учитывается и не берется во внимание. В этом и заключается глобальная проблема — мы не можем извлекать из текста всю информацию, которая в нем содержится. Это послужило толчком к развитию технологий нейронных сетей, и на текущий момент она уже достаточно развилась.
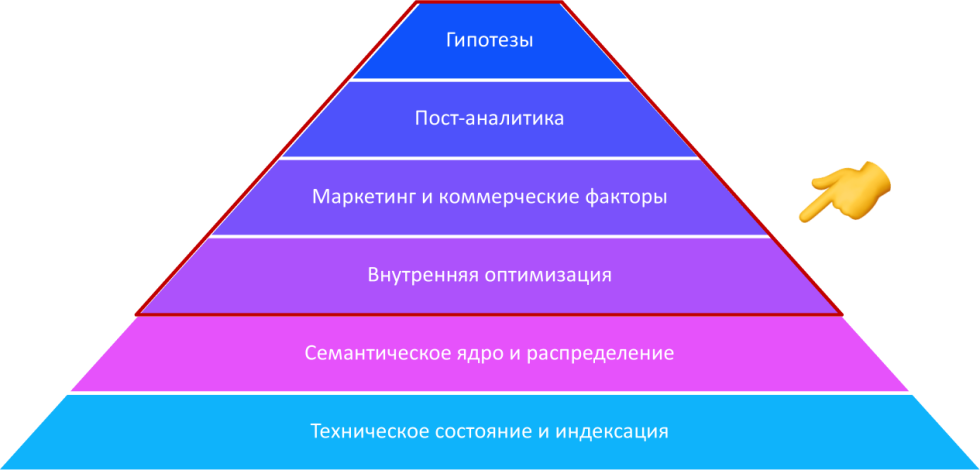
На повестке 5 основных поинтов, связанных с изучением нового алгоритма Яндекса, запущенного в 2020 году:
Чем отличаются регулярные изменения от Core Update (алгоритм YATI относится к категории Core Update).
Как используются нейронные сети в алгоритмах ранжирования, поговорим об основных вехах и рассмотрим примеры использования.
Поговорим об отличиях и сходствах подходов BERT (Bidirectional Encoder Representations from Transformers), который запущен в Google и YATI.
Коснемся актуальной темы, которая волнует многих SEO-специалистов — сможет ли новый алгоритм победить накрутку поведенческих факторов.
Несколько практических рекомендаций для маркетологов, владельцев бизнеса и SEO-специалистов.
Для поисковой системы Яндекс 2020 год был насыщенным событиями, с октября по декабрь наблюдался режим перманентного шторма, выдача Яндекса стремительно менялась.
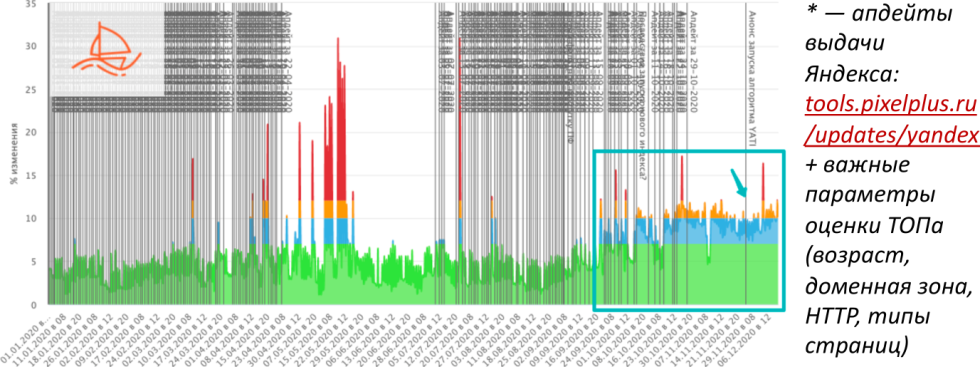
При этом у нас есть возможность отличать некоторые регулярные изменения, которые постоянно происходят и анонсируются в поиске. Только в 2018 году Google произвел порядка 300 изменений. В Яндексе, в связи с меньшим штатом инженеров, количество несколько более скромное, но плюс-минус сопоставимое. Наряду с этим есть фундаментальные изменения, и Core Update, как правило, затрагивает большую долю поисковых запросов. Эти изменения часто связаны с переобучением формулы или с изменением подхода и новыми идеями, затрагивают фундаментальные принципы ранжирования.

Анонсы этих Core Update встречаются в разных поисковых системах по-разному. Например, в Google — Денни Саливан емко рассказал о последних нововведениях 2020 в своем блоге.
В тоже время Яндекс по факту не анонсирует запуски, но часто раскрывает больше деталей на русском языке в статьях на HUBR или еще где-то. Если копнуть немного глубже, то станет ясно, что все материалы про адаптацию к алгоритму BERD и его запуск есть в открытых источниках. То есть, у вас есть возможность понять, каким образом люди приходят к тем или иным идеям, какой профит они дают, погрузиться в эти факторы глобально.
По факту Яндекс анонсировал запуск нового алгоритма в ноябре, но в ноябре не было никаких изломов средних показателей выдачи.
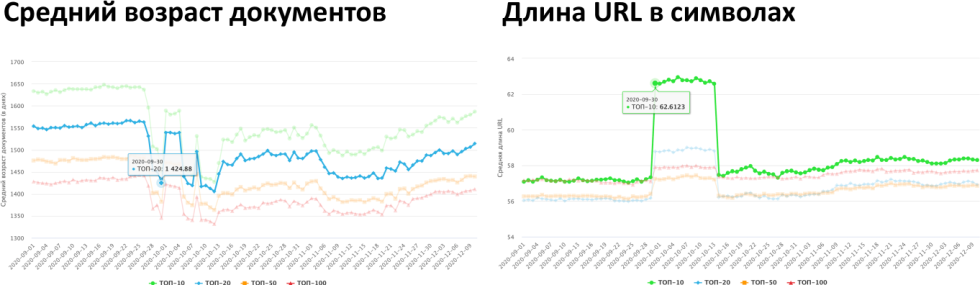
При перманентном шторме ситуация постоянно меняется, но происходит это достаточно плавно. Когда запускается новый алгоритм, как правило, происходит некоторый излом показателей графиков, которые достаточно сглажены. К примеру, средний возраст документов в выдаче или средняя длина URL-адресов, доля доменных зон выдачи — усредненные показатели, которые не часто меняются.
У нас есть предположение, что реальная дата запуска YATI была размазана во времени. Скорее всего, это был конец сентября, косвенно об этом говорит один из разработчиков — глава нейросетевых технологий в Яндексе. То есть мы уже давно живем в новых реалиях с новым алгоритмом Яндекса.
Не нужно бояться новой терминологии, в ней нет ничего сложного и запредельного. Так же, как SEO-специалисты свободно используют термины «переспам», «переоптимизация», «фильтры», «апдейты», «видимости» и т.д., так и математики, работающие с машинным обучением, окружили себя «своей» терминологией и специализированными сервисами. Машинное обучение в поиске используется с 2000-х годов, нейронные сети — один из методов такого обучения.
В 2009 году Яндекс анонсировал алгоритм «Снежинск», который использовал технологию MatrixNet — это стало реальным прорывом в области поиска на тот момент. До этого инженеры поисковой системы хотели активно использовать аналитическую формулу, но столкнулись с рядом трудностей и поняли, что нужно обучить алгоритм, который будем сам разбираться и выстраивать определенным образом документы, исходя из обучающей выборки. Эта технология и получила название MatrixNet.
В 2016 году Яндекс впервые публично заявил о применении нейросетей, хотя они использовались и раньше — в частности, в технологии «Яндекс.Переводчик». Основные вехи развития: 2016 год — алгоритм Палех, 2017 — Королёв, 2020 — YATI. Google в 2013 придумал word2vec, а в 2019 году — Bert. Алгоритм Word2vec был первым заходом, который представлял собой нейронную сеть, только в миниатюре с одним слоем, где есть входящий и выходящий вектор, и есть некоторый слой без функции активации. Word2vec могла и может переводить любое слово, на которое вы попадаете, в некоторый вектор «смысла» размерности 300. Эти векторы обладают интересными свойствами. С помощью простого обучения мы можем вычислить, на сколько слова близки друг другу по смыслу. То есть, мы даем большое количество выражений, и алгоритм сам вычисляет, какая вероятность, что это слово встретится в контексте рядом.
Это важный момент. Нужно понимать, что анонсированная нейронная сеть не пришла на замену всей формуле ранжирования. Она является по сути одним из факторов, которые вычисляются и используются для построения итоговой формулы релевантности (Cat Boost). Cat Boost пришел на замену MatrixNet — это алгоритм машинного обучения на решающих деревьях, который во многом нам близок.
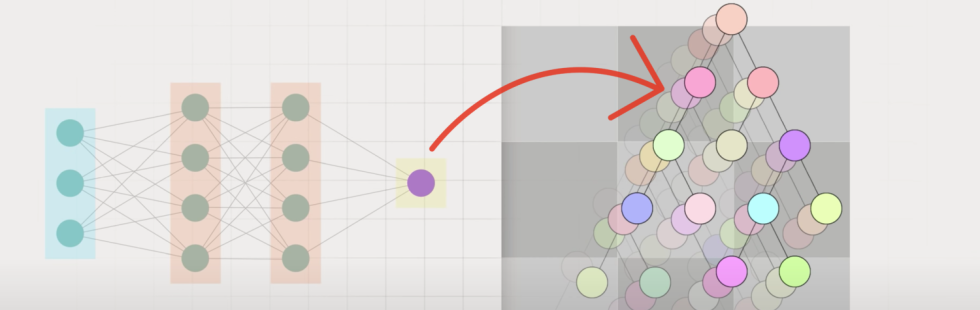
Тот фактор, который вычислен по алгоритму YATI, он является одним из факторов, на котором строится итоговая формула ранжирования. Важный момент — итоговая формула ранжирования все равно строится алгоритмом Cat Boost, а не оперирует какими-то нейронными сетями — это не итоговый ответ релевантности.
В таких случаях один из факторов «тянет» в свою сторону, то есть в каком-то смысле это можно воспринимать как борьбу между факторами, которые отвечают за смысл, и теми, которые отвечают за «обычные вхождения» в текст. При этом понятно, что в борьбе принимают участие все остальные группы факторов:
поведенческие;
хостовые (сайт);
ссылочные.
В результате выдача носит смешанный характер, как на примере с фразой «картина, где небо закручивается»:
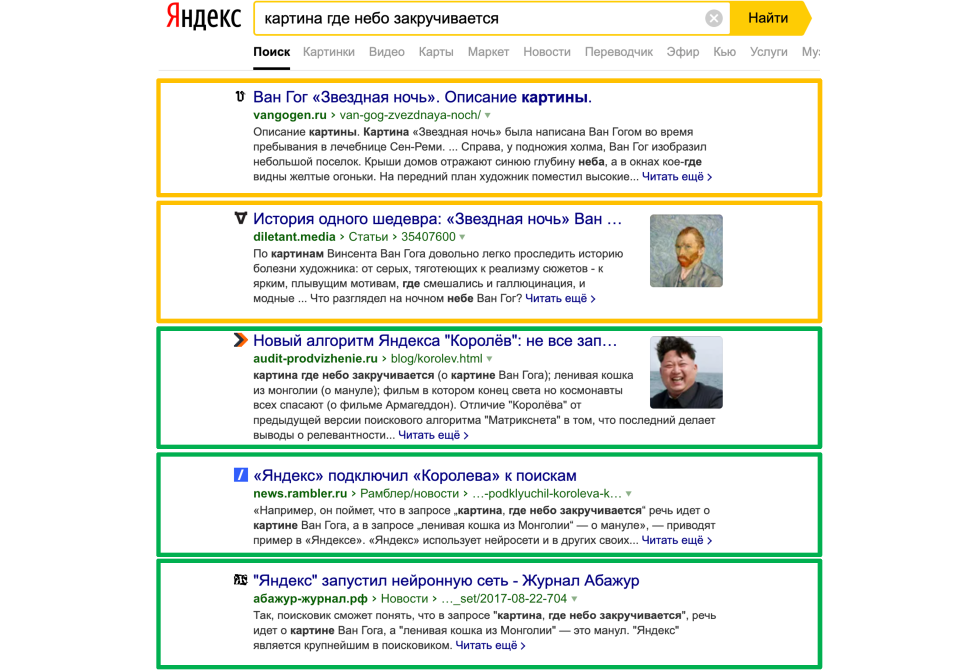
По запросу находятся результаты, в которых нет точного вхождения слов, но есть фразы, похожие по смыслу —например, картина «Звездная ночь» Ван Гога. Но присутствуют и документы, в которых есть точное вхождение запроса. Здесь максимально ярко проиллюстрирована борьба нейронной сети со смыслом, с классическими СЕОшными факторами. Достаточно хорошо видно, что Яндекс строит все не по принципу «мы придумали какой-то новый фактор, который теперь будет описывать смысл и смысловую близость запроса и документа», а по принципу «давайте добавим к текущим факторам набор дополнительных рычагов, которые буду улучшать выдачу». Еще один пример «доминирования смысла», как мы его назвали, когда есть большое количество документов (в данном случае 24) с точным вхождением длинной фразы «фильм про человека, который выращивал картошку на другой планете». Поисковая система понимает, что речь идет о фильме «Марсианин», находит документы без прямого вхождения, а иногда и вовсе без вхождения прямых слов. В этом случае смысл побеждает.
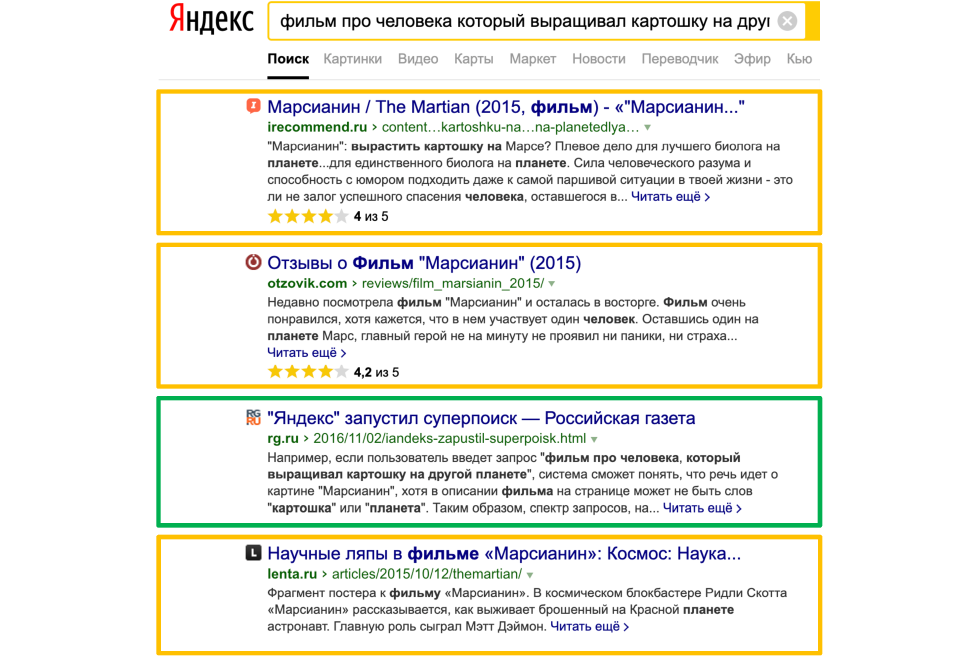
Но когда добавляют хостовые факторы, как например на «Российской газете», достаточно прокачанной с точки зрения хоста — документ с точным вхождением, абсолютно не оптимизированный, не посвященный фильму, тоже попадает в выдачу!
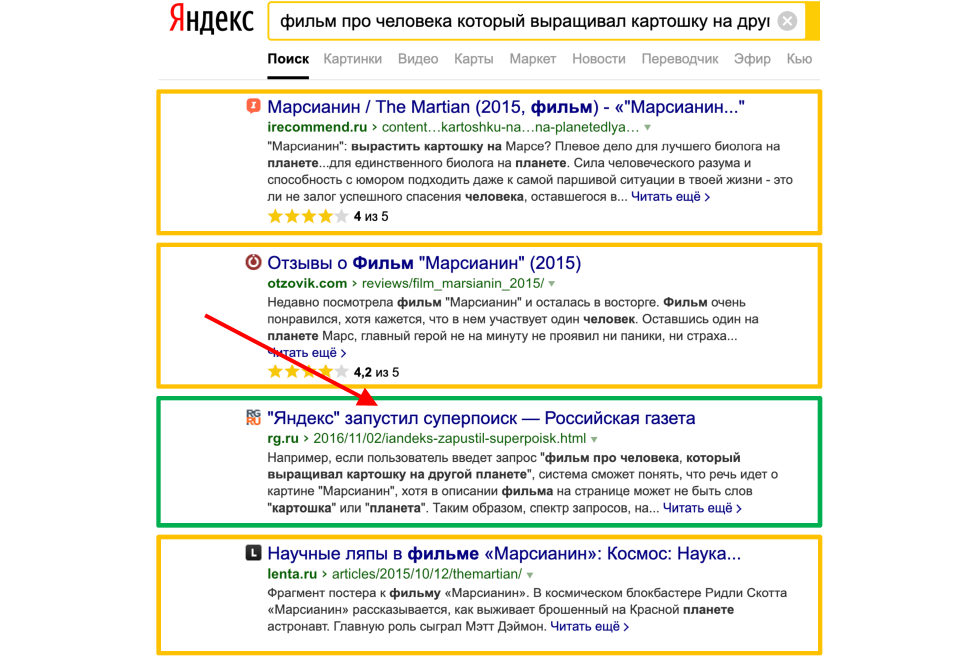
Отсюда исходит очень важный вывод, на который мы хотели бы обратить ваше внимание:

Приведенные примеры — это примеры из анонсов алгоритмов Палеха и Королёва, где Яндекс говорит примерно такие вещи — «Мы придумали поисковый запрос, видим, что по нему была не релевантная выдача, а теперь она стала релевантной». То есть по запросу «фильм про человека, который выращивал картошку на другой планете» в выдаче есть фильм «Марсианин». Как только Яндекс это анонсировал, большое количество сайтов растиражировали это, и тут же момент алгоритм ломался, поисковая система продолжала отдавать предпочтение классическим вхождениям в текст. На наш взгляд, YATI — это тот самый момент, когда факторы этого смысла и смысловой близости запросов документа стали побеждать факторы вхождения, что очень хорошо видно на низкочастотных поисковых запросах.
YATI рассматривается как один из конкурентов BERT, об этом сказано в анонсе и в раскрытии технических деталей на Habr. Дело в том, что BERT способен решать значительно большее количество задач. Это нейронная сеть, тоже на трансформерах, двунаправленная и предобученная таким образом, чтобы добавить к ней один или два дополнительных слоя. Достаточно дообучить ее, и она будет решать задачи — на разделение запросов и ответов, поиск этих вопросов, поиск сущностей, в том числе задач на поиск смысловой близости.
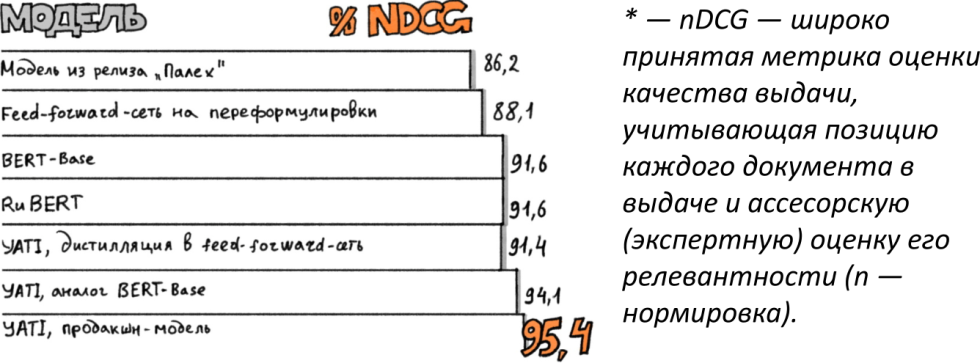
Яндекс пробует выделиться на фоне конкурента, говоря, что YATI оказался лучше в сравнении с BERT. С точки зрения лингвистики — это достаточно близкие алгоритмы, и возникает вопрос — какая конкретно реализация, дообучение BERT происходит в Google, чтобы он был запущен в продакшн. Но с точки зрения метрики NDCG (общая метрика качества выдачи, которая учитывает позицию выдачи документа) Яндекс победил BERT.
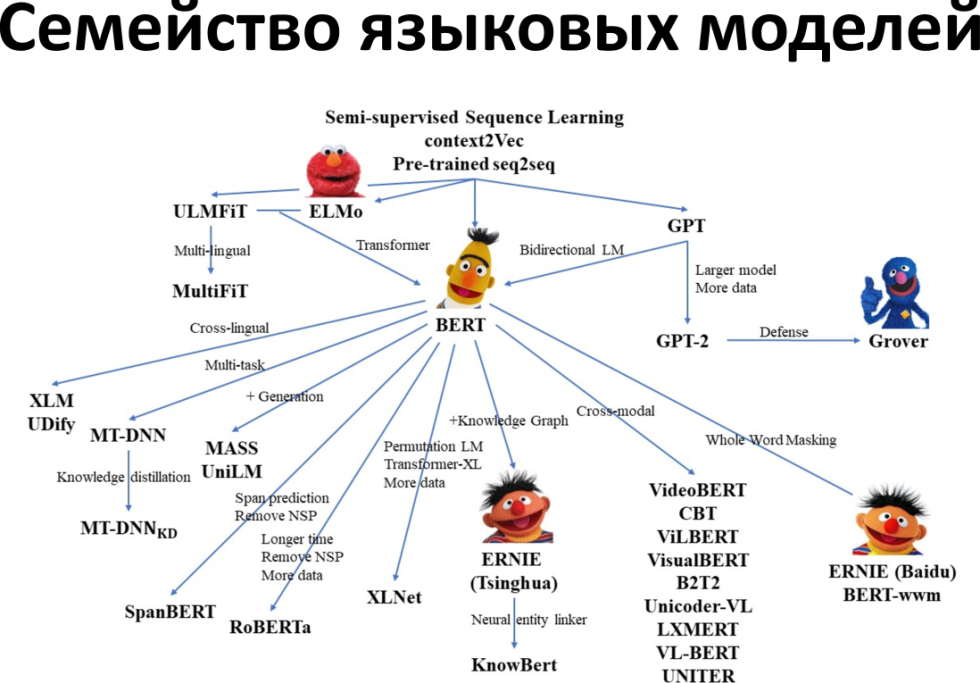
BERT является хорошо натренированной нейронкой, от которой исходит много разных алгоритмов. Где-то здесь, к слову, находится и YATI.
Нужно сказать, что поисковая система Яндекс не сразу пришла к YATI. Вначале был Палех, затем Королёв. Для SEO-специалистов и интересующихся людей важно разобраться, какая это была эволюция, и что последовательно добавлял Яндекс для учета, почему он не был удовлетворен Королёвым. В каком-то смысле, Яндекс в третий раз пытается «сделать шум» на том же заголовке. Когда запускали «Палех», был шум вроде «Яндекс научился понимать смысл текстов», «Яндекс придумал нейронную сетку, которая крутая с точки зрения понимания текста», использовались такие громкие термины, как «суперпоиск» и т.д. Когда запускался Королёв, все было так же, только с еще больше помпезностью и размахом. Поэтому YATI не зашел и особо не анонсировался, его запустили без шумихи и достаточно скромно — презентация не более двух минут + статья на Habr. Третий раз делать шум на том же инфоповоде, что Яндекс научился понимать смысл текста — не очень правильно. Возник бы вопрос: а до этого, в двух предыдущих случаях, вы делали это плохо?

Палех. Был запущен с кардинально другой архитектурой с точки зрения машинного обучения и нейросетей. Учитывается только запрос и заголовок документа. В обучение было загружено миллион слов из словаря, миллион биграмм слов и буквенные триграммы. Таким образом, слова разбивались на «трибуквия», в том числе, чтобы понять, что слова «большой» и «большущий» близки друг другу, также грузить триграммы полезно для опечаток. Полностью алгоритм ранжирования использовался только для первых 150 «лучших» документов. Конечно, в процессе отборки могут быть потеряны документы, которые могли бы попасть в ТОП-10.
Королёв. Он использовал ту же основу, что и Палех, при этом частично учитывал текст запроса, некоторые важные зоны. Здесь уже появляются стримы, когда мы анализируем с помощью нейронной сети не только сам запрос и сам документ, но и используем так называемый запросный индекс для URL-адреса (не только показы, но и клики). Алгоритм используется для большего количества документов — порядка 200 000, которые прошли предварительные этапы ранжирования.
YATI. Имеет принципиально другую архитектуру, еще больше стримов, то есть используется анкор-лист документа, запросный индекс для URL-адреса по кликам. Присутствует большая полнота данных в учете — тексты до 10 предложений по заверениям авторов алгоритма учитываются целиком. К слову, 10 предложений — не так уж много. Если же текст больше, то он будет разбиваться на важные фрагменты и показываться нейронной сети. Какие документы важные, определяет отдельный алгоритм, важен ли этот фрагмент для ранжирования, определяет нейронка.
Поговорим о важных технических нюансах, из которых можно выжать практические рекомендации:
Переформулировки и «пред-обучение на клик». Яндекс берет порядка 1 миллиарда переформулировок: [первичная фраза] — нет клика — [новая фраза]. Модель, исходя из этих данных, предобучается предсказывать клики на документы по запросу. Это предобучение очень важно, так как для обучения таких нейронных сетей с открытыми слоями требуется большое количество данных, обучиться только на оценках толокеров и асессоров не получится.
Оценки толокеров. На втором этапе используются «более дешевые и простые оценки» толокеров (Яндекс.Толока). Как правило, они не имеют какой-то дополнительной расшифровки и дополнительных свойств.
Оценки асессоров. Для обучения используются экспертные (асессорские) оценки релевантности.
Что подается на вход:
текст запроса;
расширение запроса — синонимы, дополнительные слова;
«хорошие» фрагменты документа;
стримы для документа — анкор-лист, запросный индекс, где используются не показы, а клики.
То есть, объединяется совокупность всех поисковых запросов, по которым были осуществлены переходы на данный документ. В Яндекс Вебмастере или Яндекс Метрике мы можем выгрузить список поисковых запросов, по которым были переходы на данный URL-адрес, именно они воспринимаются «хорошими» для понимания, является ли документ хорошим по смыслу ответом. Если этот новый поисковый запрос по смыслу, предсказанному нейронной сетью, близок по смыслу к другим запросам, по которым были переходы, это повышает релевантность.
Ситуация с накруткой на конец 2020 года проблемная. Волна санкций за накрутку поведенческих факторов была 1 сентября, эту ситуацию мы уже подробно разбирали в наших предыдущих статьях и вебинарах. В настоящий момент многие проекты продолжают терять видимость вплоть до нуля. Здесь проанализирована достаточно интересная тематика продвижения и создания сайтов.
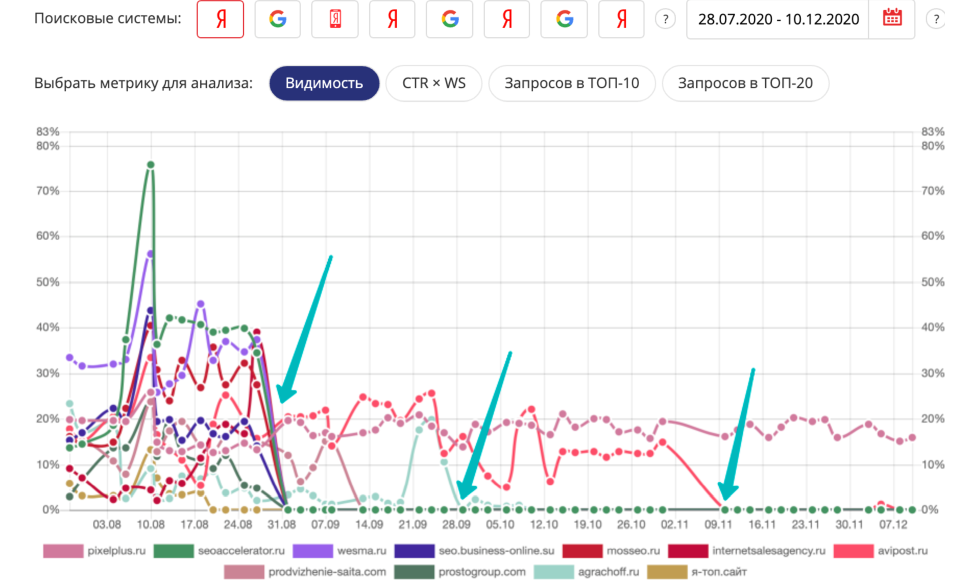
Мы видим, что большое количество сайтов ушло в небытие 1.09.2020. Но даже те, кто уходили до «0» в сентябре, они иногда подрастают, но потом опять падают. Некоторые выжили, но алгоритмы догнали их уже в ноябре. Ситуация развивается достаточно активно:
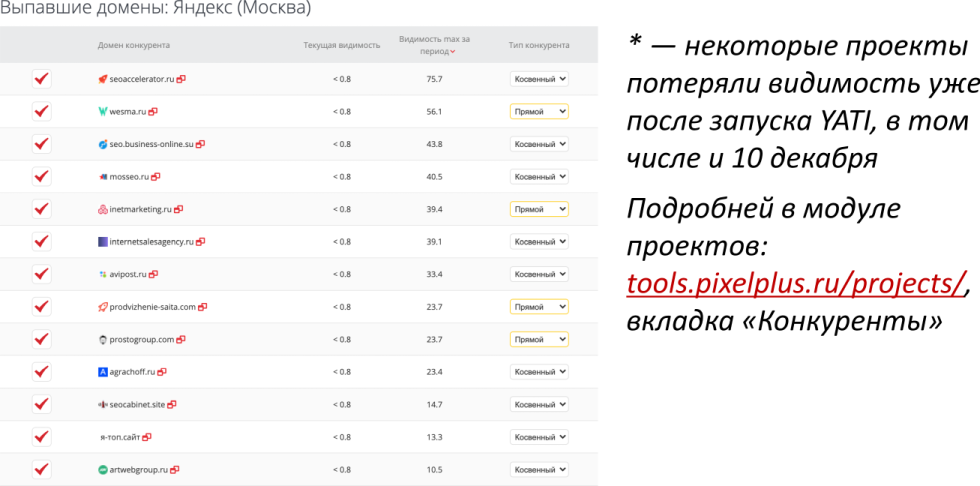
У нас есть вкладка «Конкуренты» в модуле проектов, которая позволяет смотреть, какие проекты имели хорошую видимость, а какие стремительно провалились. В выбранной тематике таких сайтов более десятка. Мы ни в коем случае не утверждаем, что все выбранные сайты накручивают ПФ, но так решил Яндекс.
Увы, ситуацию нельзя назвать равновесной, так как из одной отрубленной головы вырастает не три, к счастью, но от 1/4 до 1/2.
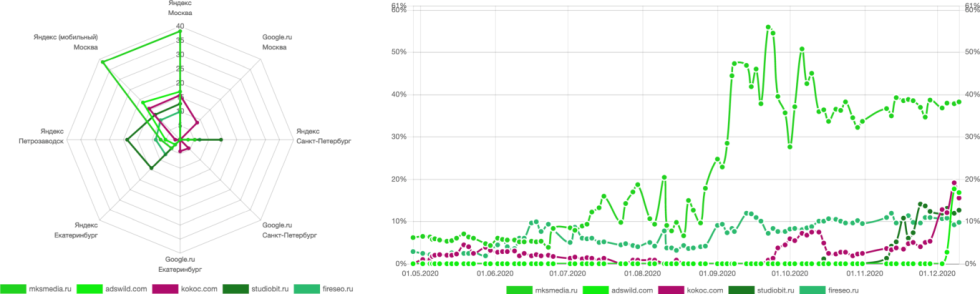
Мы видим высокую активность на этих сайтах, но как понять, что они накручены? С большой долей вероятности это такие факторы:
резкий рост;
асимметрия видимости в Яндекс и Google;
явный «фейк», на сайте представлены люди, которые не имеют никакого отношения к поисковой оптимизации.
Эти новые сайты вырастают, но их стараются чистить, поэтому ситуация с накруткой все-таки улучшается. Конечно, хотелось бы получить от самого Яндекса ответ на вопрос, как бороться с накруткой куков и левыми переходами из социальных сетей. Но, на самом деле, мы бы советовали поставить фильтрацию по правилам и поведению в Яндекс.Метрике. Количество накрученных кликов сильно уменьшится, да и обращать на это пристальное внимание, не стоит.
Отвечая на главный вопрос — сможет ли YATI победить накрутку, стоит прислушаться к словам разработчика нового алгоритма:

То есть потенциально у Яндекса есть возможность отказаться от активного учета кликовых факторов. Но очень важный нюанс состоит в том, что сама модель предобучается на предсказание кликов. Все было бы круто, если бы мы были уверены, что эти клики и сигналы не накручены. Мы видим, что Яндекс не может на 100% фильтровать эти клики, не можем знать до конца, как фильтрует Яндекс эти клики для обучения моделей, насколько тщательно это происходит, но задел для меньшего учета кликовых ПФ и победой над накрутчиками есть. Мы искренне желаем разработчикам Яндекса двигаться в этом направлении, команда «Пиксель Тулс» всегда за честную борьбу в рамках правового поля поисковой оптимизации.
Ок, Яндекс придумал нейронную сеть с открытыми слоями, с поиском смысла. Что делать с этой информацией SEO-специалистам, маркетологам и владельцам бизнеса? Исходя из утверждения, что YATI обеспечивает более 50% вклада в ранжирование, мы ожидаем, что:
«Смысл» окончательно победил возможности SEO-специалистов в области оптимизации текстов, то есть больше не нужно оптимизировать.
Все факторы вида «точное вхождение», «Title» и «добавить ключей» остались в прошлом.
Оценка этого вклада зависит от того, какие поисковые запросы берутся.
Изначально поисковая система Яндекс обучалась для улучшения ранжирования выдачи по редким запросам, по которым и так документов недостаточно. Поэтому можно сказать, что вклад в ранжирование более 50% актуален для вот этих редких запросов. Мы видим, что борьба смысла с вхождениями на текущий момент еще актуальна в результатах выдачи и «смысл» постепенно побеждает вхождения.
Чтобы максимально глубоко разобраться в теме, мы вместе с лабораторией «Пиксель Тулс» решили провести собственное исследование.
Мы сравнили значимость фактора «точное вхождение в текст по НЧ» для 2019 и 2020 годов, то есть после запуска YATI. Исследование было проведено 11 декабря, предыдущий срез был приблизительно в эти же числа прошлого года.

Мы видим, что кратный рост фактора для НЧ-запросов произошел. На выборке из 48 тысяч коммерческих поисковых запросов порог составляет 30% и более, видим кратный рост силы факторов для ТОП. На самом деле, точное вхождение в тексте по НЧ никуда не пропало, оно наоборот увеличило свою значимость на текущий момент. Это следует не из нашего мнения или какого-то логического рассуждения, на это указывают реальные результаты исследования.
Давайте посмотрим, что произошло с СЧ и ВЧ.
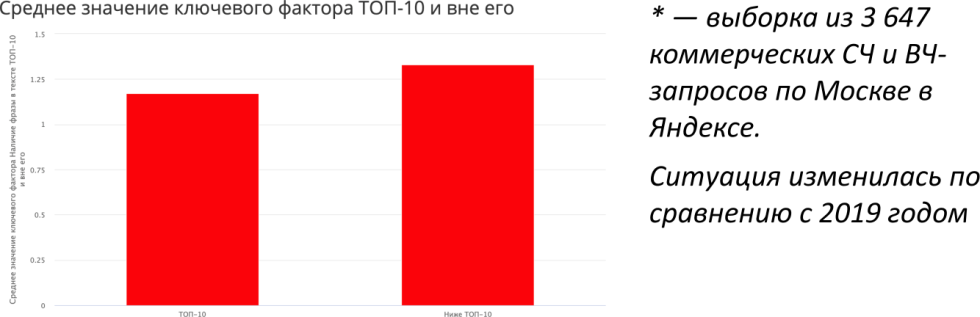
Выборка, конечно, не такая большая — порядка 4000 запросов по Москве. Здесь ситуация поменялась в сравнении с 2019 годом, явного влияния в ТОП-10 нет. На текущий момент видно, что вхождение ВЧ и СЧ запросов в документах ниже ТОП-10 несколько выше, чем у тех, кто попадает в ТОП. При этом среднее значение фактора в районе «1» — это значит, что одно вхождение есть и этого более чем достаточно, явной корреляции нет. А вот для НЧ видим, что на самом деле вхождение существенно повысило свою роль.
То есть мы смотрим, сработал ли вот этот смысл, когда Яндекс пытается угадать слово, близкое по смыслу, синонимы. На самом деле, здесь не сильно зависит от НЧ и СЧ, но есть определенная корреляция в ТОП-10.
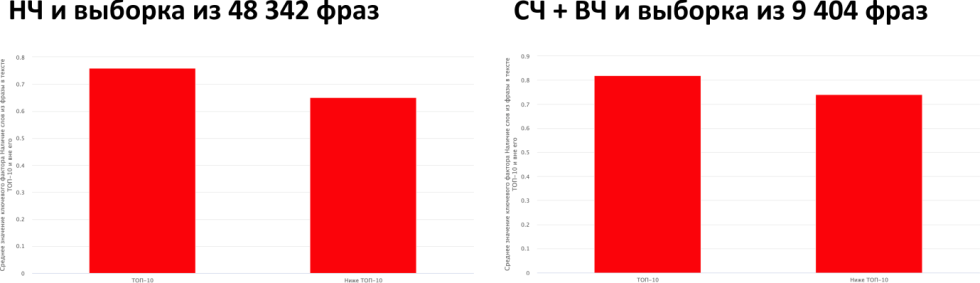
Документы, находящиеся в ТОП-10, чаще содержат все слова и запросы в сравнении с документами, которые находятся ниже. Мы видим, что среднее значение находится в районе 0,8. Это значит, что 80% слов из запроса содержится в документе. Грубо говоря, рекомендация добавлять все слова из запроса достаточно актуальная и живучая.
Посмотрим, что произошло с фактором вхождения всех слов в Title после запуска YATI.
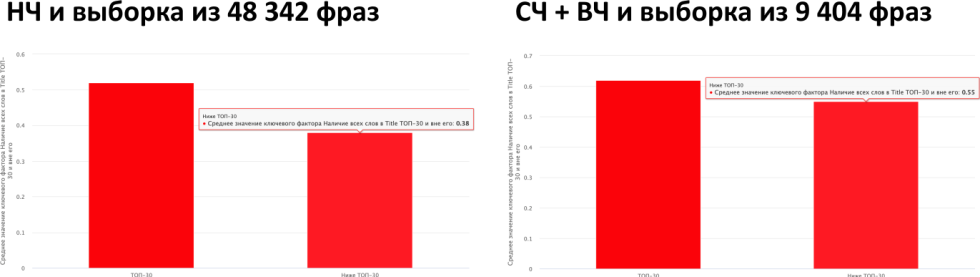
Мы видим, что в 2020 году рост среднего значения относительно 2019 изменился. В выдаче стали встречаться документы, у которых есть все слова из запроса в Title, при этом присутствует уменьшение корреляции с позицией. Можно сказать, что это бинарный фактор, который необходим для того, чтобы документ попал в выдачу, но он не влияет конкретно на позицию в выдаче. Ну и для НЧ-запросов он на удивление важнее, чем для СЧ и ВЧ.
Переходим к рекомендациям — семи важным работам, которые нужно делать SEO-специалисту для оптимизации под новые алгоритмы YATI, чтобы позиции росли.
Раньше эти рекомендации касались оптимизации под «Королёв» и «Палех». Нам нужно максимизировать количество слов из продвигаемого поискового запроса, которые встречаются в контексте. То есть мы задаем поисковый запрос «пластиковые окна» и должны максимизировать количество слов, которые встречаются в контексте с этой фразой, отдельно взятыми этими словами в поисковой системе. Мы предлагаем делать это с помощью инструмента «ТЗ для копирайтера», там используются:
прямые синонимы, которые давно учитываются;
слова из подсветки выдачи;
слова, задающие тематику — часто встречаются в документах, но не совпадают с поисковыми словами из запроса;
слова, которые встречаются у конкурентов, но их нет на продвигаемой странице: «Анализ ТОП по ключевым показателям».
Мы знаем, что алгоритм выделяет определенные важные зоны в тексте и подает их на вход нейронной сети, чтобы она оценила, близок этот фрагмент по смыслу к поисковому запросу или нет, помогает он пользователю или нет. Форматировать тексты нужно обязательно, а именно:
разбивать подзаголовками и заголовками, начиная примерно с 10-12 предложений;
выносить тематические и ключевые слова в заголовки и выделенные фрагменты.
То есть слова, задающие тематику, должны быть в тех фрагментах, которые с большой долей вероятности подадутся на вход нейронной сети — это заголовки и небольшие выделенные фрагменты.
Эта информация уже не раз озвучивалась в предыдущих рекомендациях, значимость этого фактора растет. Что нужно делать:
изучите поисковые запросы, по которым были зафиксированы переходы на URL, они должны быть релевантными;
Если вы видите, что переход на URL-адрес осуществляется по нерелевантным поисковым запросам, нужно что-то с этим делать — деоптимизировать страницу, убрать какие-то слова с точки зрения контекста;
поднимите релевантность по тем запросам, по которым уже были переходы, чтобы повысить позицию исходного поискового запроса. Это стандартная схема от НЧ для документа к СЧ/ВЧ.
Важные моменты здесь:
данные для хоста, как и прежде, сказываются на факторах для заданной страницы;
проверки из пункта №3 выше актуальны и в разрезе всего сайта, а не только заданного URL.
Это обязательно должны быть вложенные и синонимичные запросы, они помогают в продвижении по более общим и близким по смыслу высокочастотным запросам. Пример: [SEO продвижение сайта цена в Москве] поможет и для [продвижение сайтов] и для [SMM-продвижение]. Слова «продвижение», «SMM», «SEO» с точки зрения Яндекса — это довольно близкие термины, которые часто сравниваются друг с другом.
Наше видео по теме «Анализ ТОП и конкурентв для SEO: 7 шагов + шаблон + инструменты автоматизации» и шаблон. Что вы можете посмотреть:
показы конкурентов по запросам;
акценты на текстах: тематические слова, фразы, структура;
структура сайта и охват запросов из семантического ядра.
Если у конкурента какой-то поисковый запрос охвачен всецело (под него есть целый раздел, развернутая структура по тегам), то вам нужно повторить эту развернутую структуру, чтобы полноценно охватить. Анализ конкурентов — сквозная тема в любом SEO. Мы можем отказаться от изучения всех новостей про алгоритмы ранжирования Яндекс и Google вообще, будет достаточно грамотно пользоваться инструментом формирования ТЗ на копирайтинг и Анализ-ТОП по ключевым факторам.
Как мы поняли из результатов исследования, она никуда не ушла. YATI хоть и является прорывной технологией, Яндекс все же строится по принципу «добавить что-то сверху», а не «написать все с нуля». То есть никто не отменял алгоритмы Яндекса и не говорил, что будет писать кардинально новый алгоритм, в котором не будет TF-IDF, BM25, просто новые добавляются к старым.
Роль смысловой близости текста и запроса растет, если у поисковой системы нет или мало данных о поведении по данному запросу и мало документов, которые «хороши» по классическим текстовым факторам.
Максимальный прирост идет по неоднозначным редким поисковым запросам («длинным хвостам») — то, на что все алгоритмы и направлены. Здесь нет никаких революционных изменений с точки зрения поисковой оптимизации и на текущий момент не предвидится. Это исходит из того, что Яндекс плюс-минус доволен качеством выдачи, за исключением кейсов с накрутками.
На вход YATI подаются различные стримы: анкор-лист документа и запросный индекс по кликам.
В частности, это произошло в октябре. Мы видим, что в тематике «создание, продвижение сайтов» в один момент выросли несколько информационных проектов — Википедия, сайт Wiki.rukee.ru и YouTube.
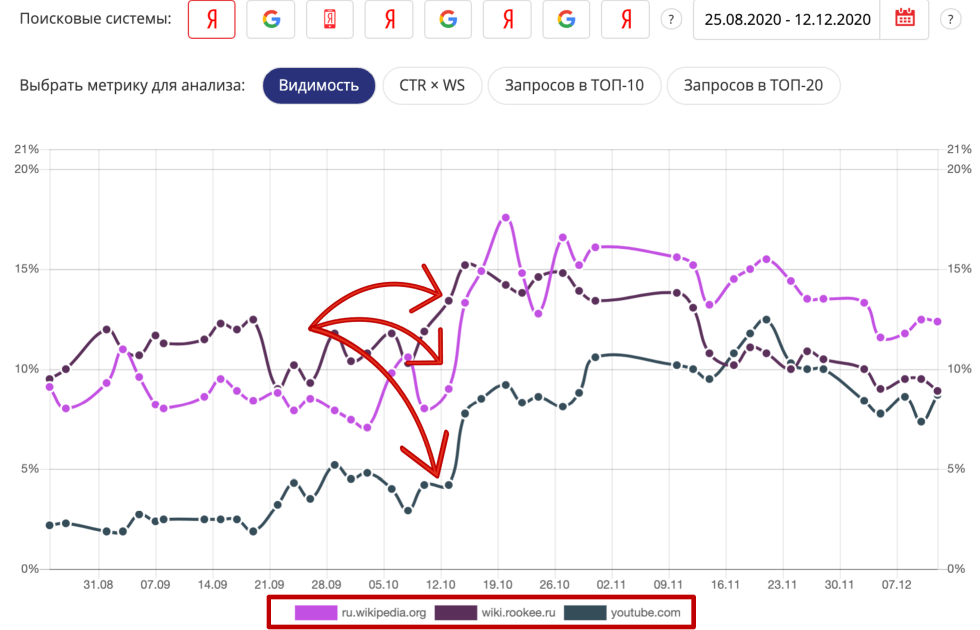
Гипотеза здесь состоит в том, что Яндекс лучше понял эти страницы, которые раньше не были оптимизированы под конкретные запросы. Очевидно, что в YouTube и Википедии никто не заморачивался с оптимизацией, сработал запросный индекс для хоста или для документов. Этот целенаправленный рост информационных проектов по такой смешанной тематике «создание и продвижение сайтов» может косвенно говорить о том, что именно в этой тематике алгоритм был запущен примерно 12 октября. Вы можете сделать анализ в рамках своей тематики — для этого откройте модуль ведения проектов «Пиксель Тулс», вкладка «Конкуренты».
Что еще нужно сделать, чтобы отработать новый алгоритм ранжирования? Первое — обновить распределение. Если вы давно делали группировку запросов и распределение (более 4-6 месяцев назад) — самое время ее переделать. Дело в том, что алгоритмы Королёв и YATI изменили состав кластеров, которые формируются при анализе ТОП. Часто это приводит к расширению.
Если раньше к одной и тоже странице цеплялись явно синонимичные запросы в кластере, то сейчас размеры кластеров вырастают. В каком-то смысле становится выгодным продвижение более прокачанных и всеобъемлющих, хабовых страниц, которые полноценно отвечают на все поисковые запросы. При этом к классическим запросам добавляются запросы, которые близки по смыслу, но не близки в разрезе морфологии.
Ряд запросов могли поменять свой тип, то есть стать целевыми или наоборот. Раз в три месяца рекомендуется «освежать» семантику и учитывать актуальный состав выдачи.
Чтобы закрепить пройденный материал, рекомендуем ответить на следующие вопросы:
Верно ли, что новый алгоритм Яндекса YATI делает классическую оптимизацию текста необязательной? Ведь теперь учитывается смысловая близость запроса и текста.
Верно ли, что теперь для построения итоговой формулы релевантности Яндекс использует нейронные сети?
Назовите не менее 3 основных работ для улучшения факторов, которые оцениваются при помощи технологии YATI.
Что такое стримы, какие данные они могут включать?
Чем YATI принципиально отличается от Палеха и Королёва?
Вебинар по анализу конкурентов в выдаче и шаблон анализа конкурентов.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Модуль проектов + поиск конкурентов, которые показали падение или рост.
Чтобы не пропускать новые материалы, подписывайтесь на наши группу ВКонтакте, чат Telegram и канал YouTube.