Россия, Москва, посленовогодний постапокалипсис, 9 января 2017 года.
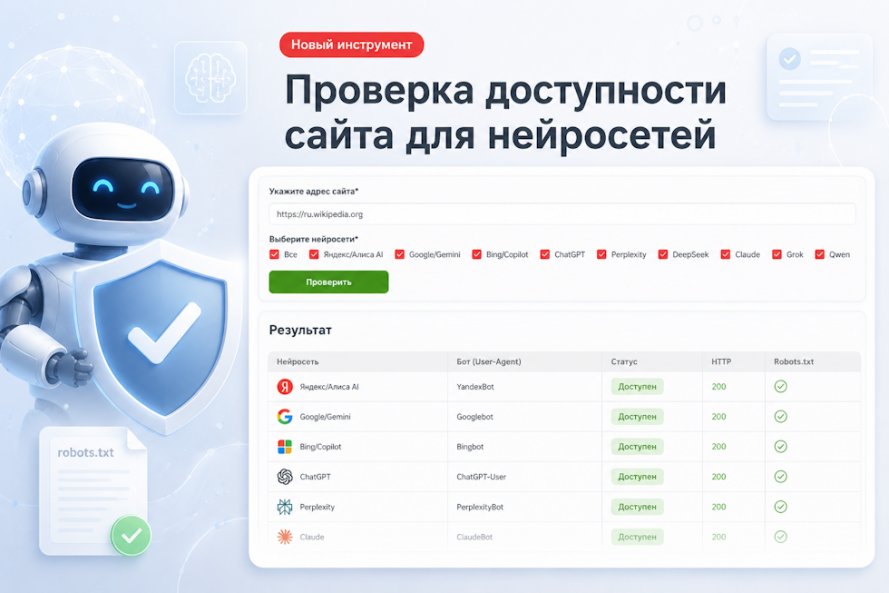
Команда проекта прокачала инструмент «Проверка текста на уникальность». Теперь с его помощью можно численно определять сайты-первоисточники по фрагменту текста (рекомендуется) или URL и выгружать для рерайта/анализа неуникальные фрагменты текста.
Как это работает?
Достаточно просто:
- Вводите текст, скажем, с вашего сайта.
- Система определяет список сайтов/URL на которых найден данный текст (его фрагменты).
- Выводит список первоисточников (сайтов, который являются автором контента по мнению поисковой системы Яндекс).
- Рядом с каждым URL указывается процент фрагментов текста, по которым он признан первоисточником.
- Дополнительно: выводится список неуникальных фрагментов (полезен в том случае, если вы проверяете текст, который нигде не был размещен, скажем, только написан после ТЗ на копирайтинг).
- Всё данные можно выгрузить в CSV.
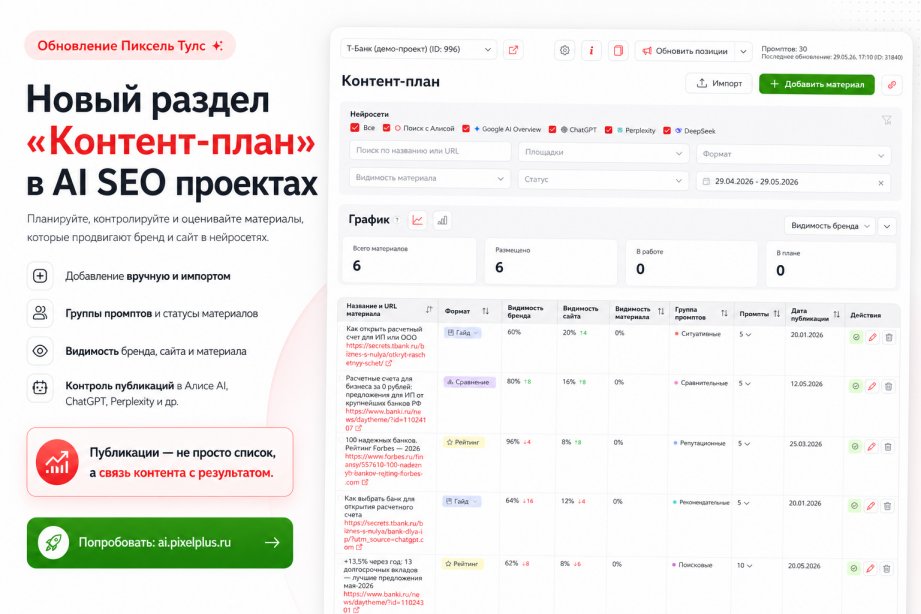
Пара иллюстраций
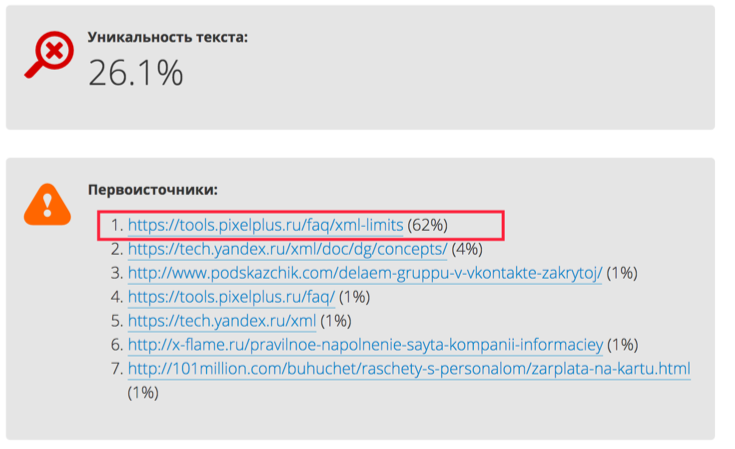
1. Взят текст со страницы. По факту — текст неуникальный, он уже проиндексирован поисковой системой. Но мы хотим понять, является ли наш сайт первоисточником по нему или конкуренты, которые украли текст, смогли присвоить его (частая история)?
Проверяем — выдыхаем. Лишь по 9% фрагментов текста наш URL не выдается как первоисточник в Яндексе. Не страшно:
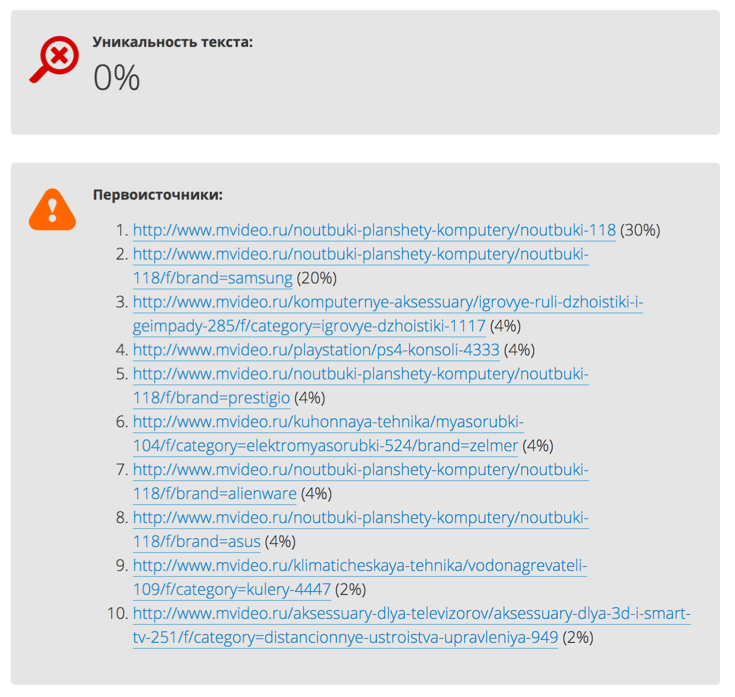
2. Взят текст из рубрики каталога. По факту, авторство/уникальность текста внутри домена — «размазана» по нескольким страницам. Не самый хороший признак. Но, других доменов среди первоисточник нет — хорошо.
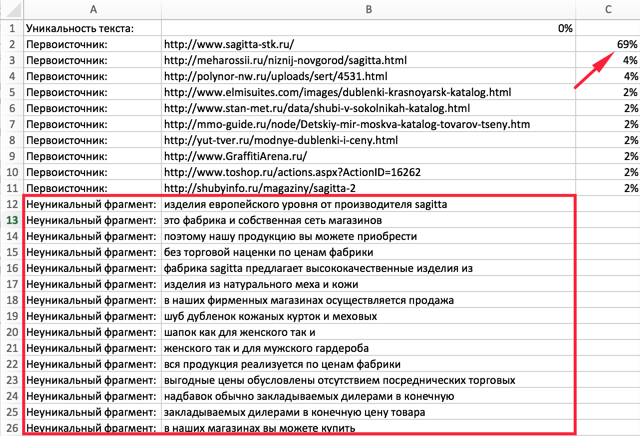
3. Бывает, что текст был впервые размещён на одном сайте, но, потом он стал неуникальным и авторство потерялось. Это уже фирменная беда. Теперь её можно быстро диагностировать с помощью бесплатного инструмента «Пиксель Тулс».
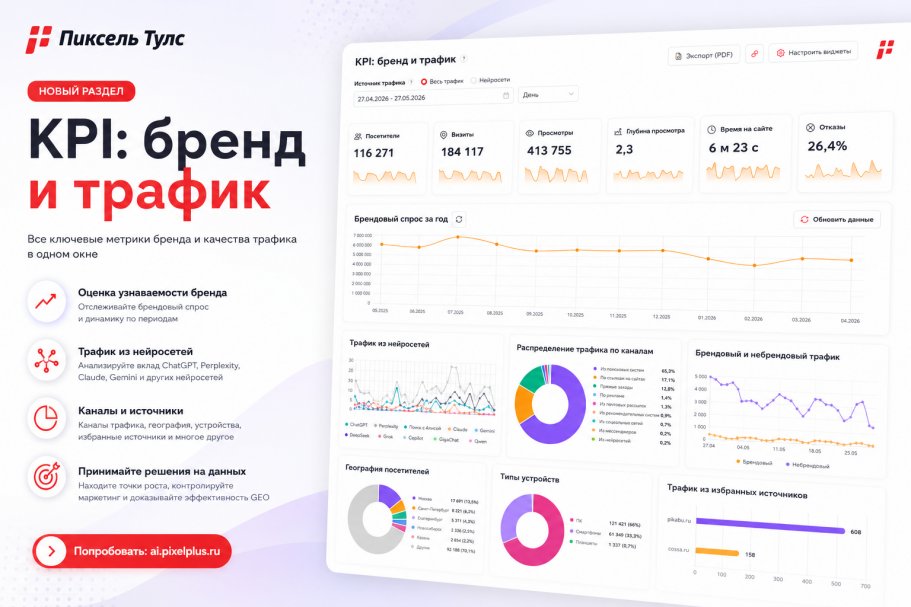
Выгрузка в CSV и исключение доменов из анализа
При привычке — можно выгрузить данные анализа уникальности в CSV, а также исключить с помощью настроек несколько доменов из анализа.
Проверяйте уникальность и определяйте первоисточник правильно!