Новая функция в GEO-проектах покажет, на каких источниках из ответов нейросетей упоминается ваш бренд.
Продолжаем разбирать важные патенты Google, чтобы лучше понимать работу поисковой системы и учитывать особенности алгоритмов при разработке собственных SEO-стратегий.
Спасибо Биллу Славски, который регулярно отслеживает ключевые патенты Google.
Knowledge Graph (Граф знаний) — база знаний на основе семантических связей, которая оперирует понятиями / сущностями / терминами / имена. Цель заключается в повышении качества ответов на вопросы пользователей. База основана на данных различных источников, главные из них:
Wikipedia.
CIA World Factbook (Всемирная книга фактов ЦРУ).
Freebase (коллекция данных, собранных интернет-сообществом).
Сервисы Google (Maps, Play, YouTube и другие).
Самый простой пример логики использования Графа знаний в SERP:
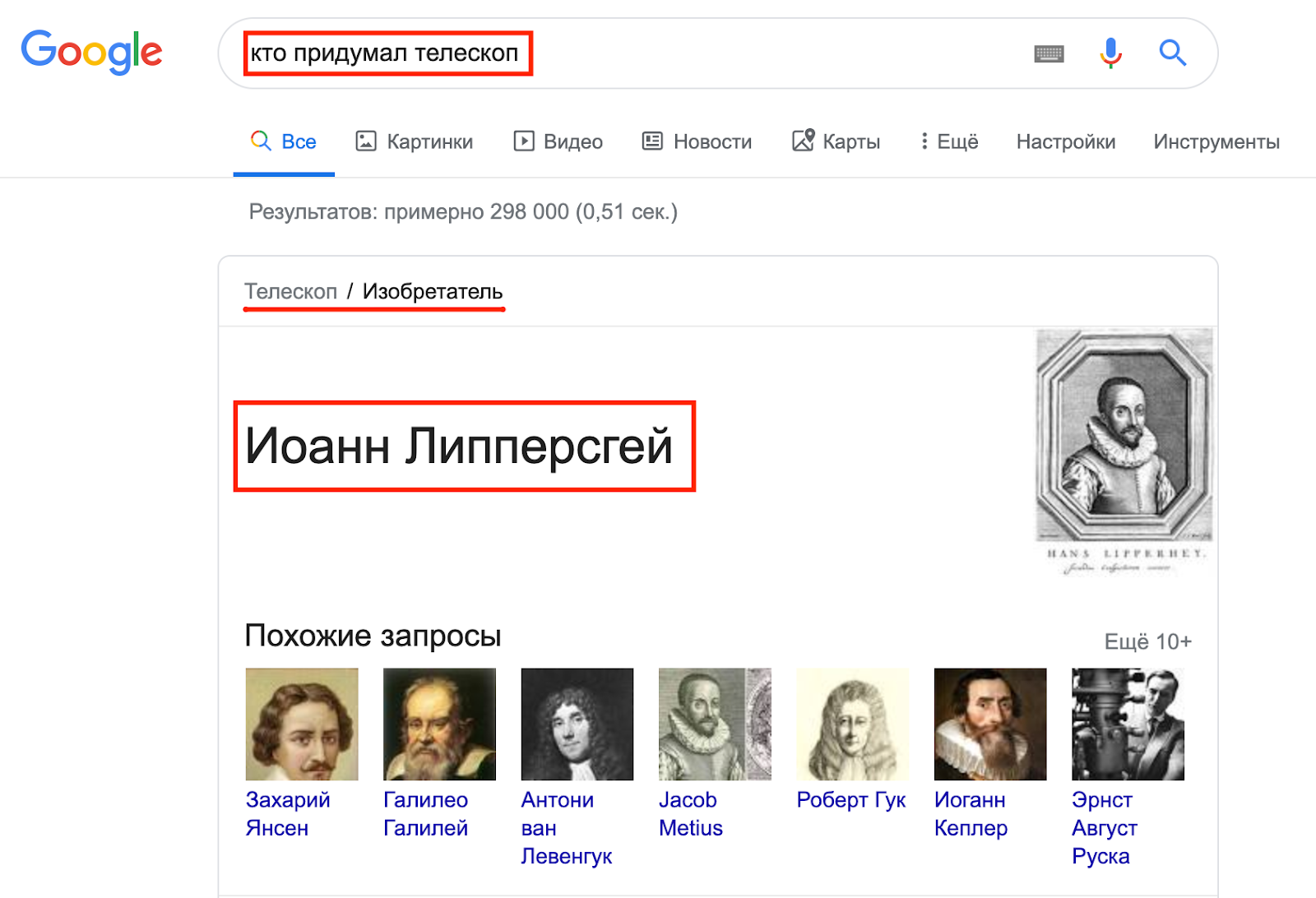
То есть, для запроса [кто придумал телескоп] используются примерно следующие связи:
телескоп > придумал (изобретатель) > кто (имя изобретателя).
Но патент, который мы рассмотрим ниже, затрагивает индивидуальный, то есть персонализированный под пользователя Граф знаний. Это не значит, что если мы уверены — телескоп изобрел Галилей, то Google подтасует результаты согласно нашим убеждениям, но при поиске развлечений на выходные в ход пойдёт всё, что о поисковику о вас известно :)
Глобально, суть патента в следующем — Google использует индивидуальный Граф знаний для ответа на запрос или несколько запросов и прогнозирования подходящих конкретному пользователю результатов. Граф знаний нужно понимать не как единую базу знаний, но как подвижную и гибкую систему на основе всех имеющихся у Google данных о пользователе.
Место индивидуального Графа знаний на схеме формирования ответов на запрос (в нижнем правом углу).
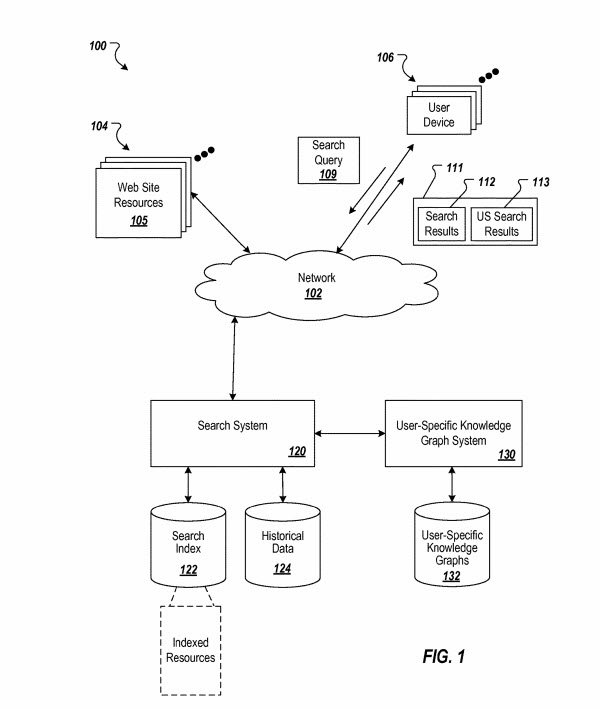
Оригинал патента лежит здесь:
Structured user graph to support querying and predictions
Inventors: Pranav Khaitan and Shobha Diwakar
Assignee: Google LLC
US Patent: 10,482,139
Granted: November 19, 2019
Filed: November 5, 2013
Методы, система и инструменты для получение индивидуального контента, который может быть связан с пользователем одной или нескольких компьютерных услуг (вероятно, имеется в виду различные сервисы Google или устройства, что станет понятно дальше). Обработка индивидуального контента с помощью нескольких анализаторов с целью выявления одной или нескольких сущностей и связей между сущностями. Формирование одного или нескольких индивидуальных Графов знаний, включающих в себя «узлы» и «ребра» (то есть объекты и связи с определенным весом) между ними для определения отношений между сущностями. В результате — сохранение одного или нескольких индивидуальный Графов знаний.
Получение данных о конкретных пользователях в структурированном виде.
Предоставление ответов на сложные вопросы или серию запросов пользователя.
Индивидуальный Граф знаний позволяет получить единое каноническое представление о пользователе на основе его активности, полученной из одного или нескольких сервисов.
Создание универсальных Графов знаний, не привязанных к конкретному пользователю.
Вот какие сервисы Google и другие источники могут учитываться при составлении User-Specific Knowledge Graph:
Поисковая система.
Электронная почта.
Чаты.
Сервис обмена документами.
Календарь.
Сервис обмена фото.
Сервис обмена видео.
Блоггинг и микроблоггинг.
Службы регистрации.
Рейтинги и отзывы.
Как же информационная безопасность? В патенте есть небольшая ремарка: «пользовательские данные обрабатывается таким образом, чтобы личную информация было невозможно определить». А также «геолокация обобщается, чтобы конкретное местоположение не было определено». Не очень надёжно, но тем не менее.
Ниже пример получения структурированных данных о пользователе и различных источников:
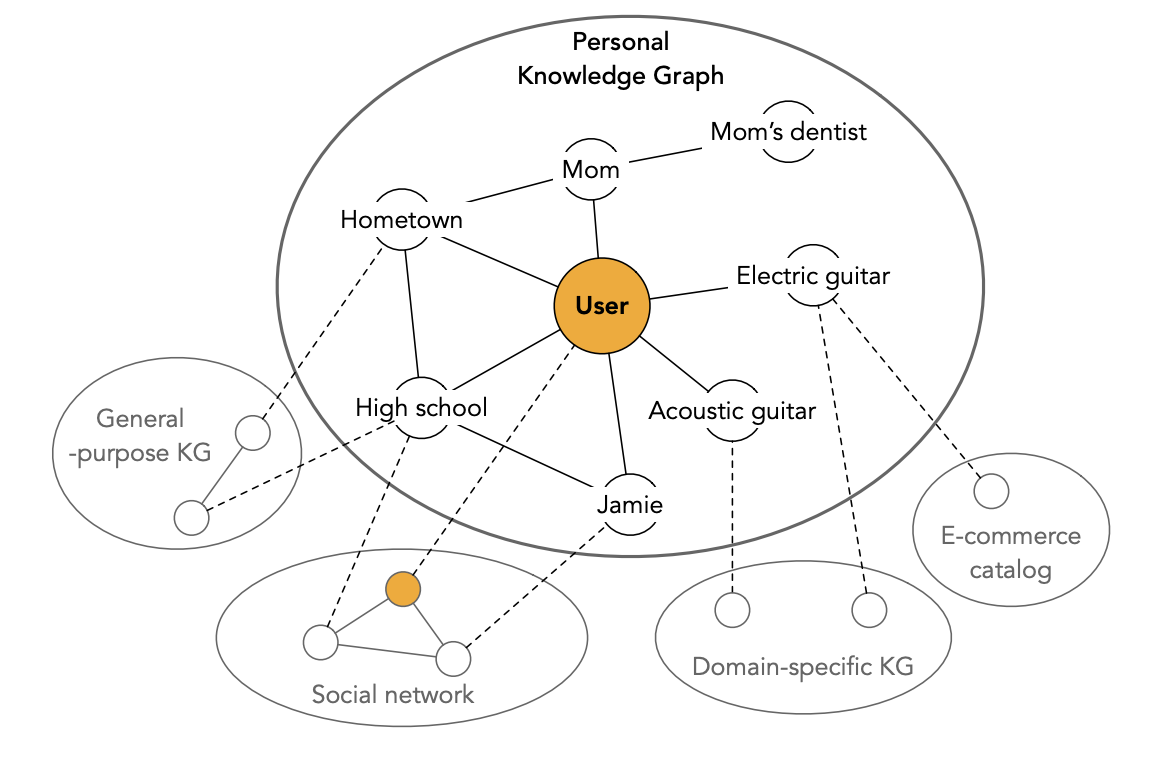
Обратите внимание, на иллюстрации есть связи, определяющие социальный Граф знаний, то есть родственные или другие взаимоотношения, которые также могут учитываться при обработке запросов.
Какие ещё данные Google получает о пользователях?
Активность в социальных сетях.
Профессия.
Предпочтения пользователя.
Текущее местоположение.
Посещаемые мероприятия.
Просмотренные фильмы.
Социальные связи в сетях и офлайн.
Лайки и дизлайки.
Итак, для ответов на запросы Google оперирует сущностями, узлами и связями между ними. Важно здесь — связи имеют коэффициенты, то есть вес и он может меняться.
Пример запроса из патента [playing tennis with my kids in mountain view], в переводе «играю в теннис со своими детьми в Маунтин-Вью». Ниже представлена схема, которая демонстрирует сущности и связи, используемые для формирования выдачи:
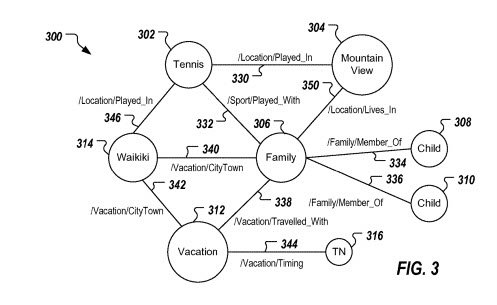
Мы видим узлы-сущности: «семья», «отдых», «теннис», «ребенок», «Маунтин-Вью» (город), «Waikiki» (отель) и связи-рёбра: «локация / где играют», «семья / член семьи», «спорт / играть с чем» и так далее.
Откуда они берутся? Например, пользователь выложил пост в социальной сети: «Мы отлично провели время сегодня, играя в теннис с детьми», а геолокация указывала на Маунтин-Вью, штат Калифорния.
И/или пользователю на почту пришло письмо из отеля: «Подтверждаем бронирование отеля в Waikiki. Желаем приятного отдыха вашей семье». В итоге к изначальным узлам из запроса добавляются дополнительные — название отеля, отпуск, дата и так далее.
Чем больше повторяющихся данных, тем сильнее вес сущностей и связей. Например, пользователь также запланировал тренировку на корте в календаре Google, искал спортивные клубы в поиске ранее, смотрел видеообзоры теннисных ракеток. В зависимости от наших активностей и информации со всех источников, к которым имеет доступ Google, узлы могут меняться местами, добавляться и исключаться.
Во-первых, понять отличие от простого персонализированного поиска — учитываются не только предыдущие поисковые сессии, но и другие источники и сервисы (судя по всему, от писем до лайков на YouTube).
Во-вторых, обратить внимание, что один и тот же запрос для различных пользователей может давать разный результат, но в то же время Граф знаний может из индивидуального превратиться в универсальный.
В-третьих, стараться проработать целевые страницы таким образом, чтобы охватить максимальное количество релевантных для конкретного пользователя фактов. Если мы не можем повлиять на выбор SERP Google в отношении конкретного пользователя, то способны:
Определить интент и проработать тексты словами задающими тематику, думая не только о вхождениях ключевых фраз, но о сущностях, логике, стуктуре и связности контента.
Определить геозависимость и локализацию и использовать топонимы не только для городов, но и улиц или станций метро.
Собрать подсказки Google и расширить СЯ (чем больше семантики вы охватите, тем выше шансы удовлетворить самые вариативные варианты запросов и интента).
Представлять бизнес в социальных сетях, Google Maps и Google My Business.
Google и вообще поисковые системы продолжают развивать персонализацию выдачи под конкретного пользователя. Стоит вспомнить, что активно этот подход ранее развивался и в Яндексе, хотя последние несколько лет тут нет публичных новостей и прорывов и вот Google нарушил молчание. Стоит отметить, что ранее Google не всегда лестно отзывался о персонализации.
1. Первое, что начал учитывать Яндекс — умение пользователя читать на иностранном языке и повышать или наоборот понижать в результатах документы на, скажем, английском языке.
2. Далее были добавлены факторы, учитывающие:
Какие сайты посещал пользователь.
Какие запросы были заданы в Яндекс за последние несколько минут, неделю и два месяца.
Введенный поисковый запрос, если он уже был задан.
Последний фактор, а именно, подстройка поисковых подсказок под текущий запрос пользователя, довольно активно применяется в Яндексе и сейчас, хотя Google «фишку» так и не скопировал.