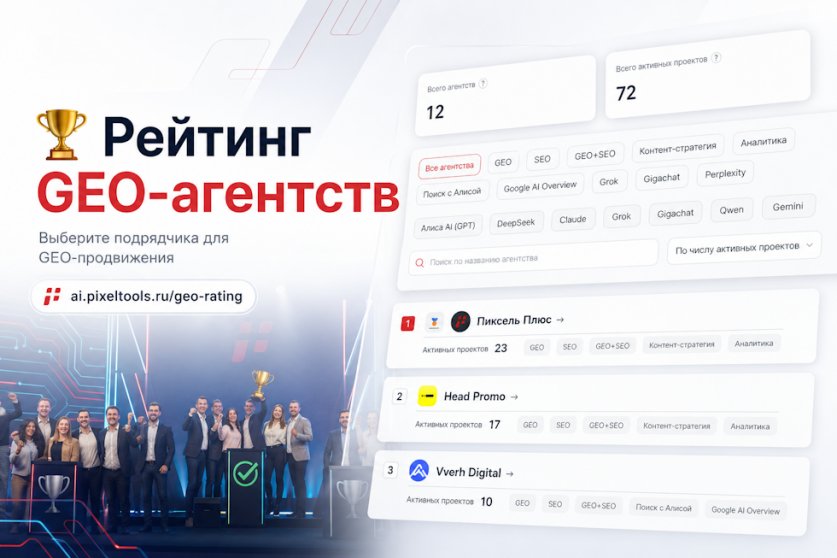
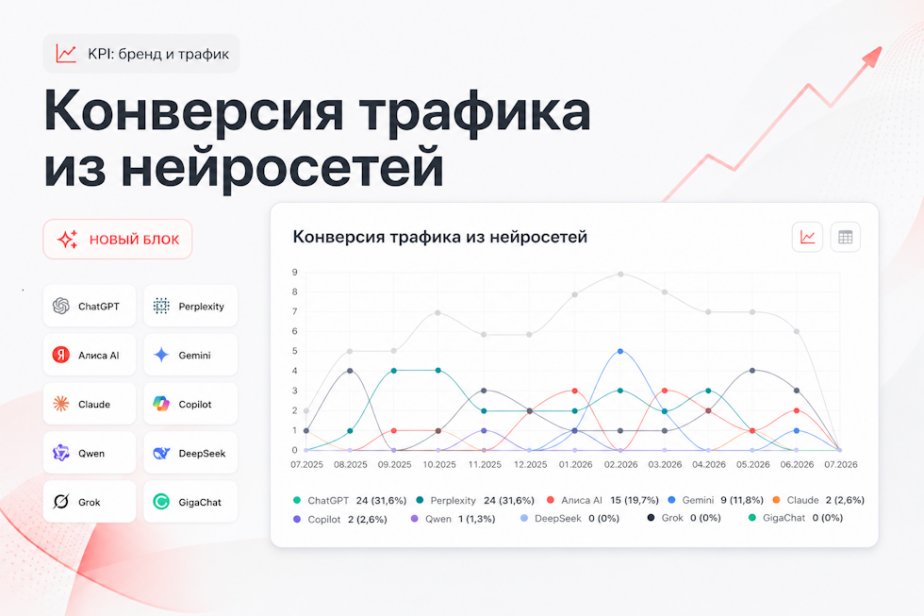
Пиксель Тулс опубликовал первый рейтинг факторов ранжирования в GEO. Девять экспертов оценили 43 фактора, которые влияют на видимость бренда в AI-ответах.
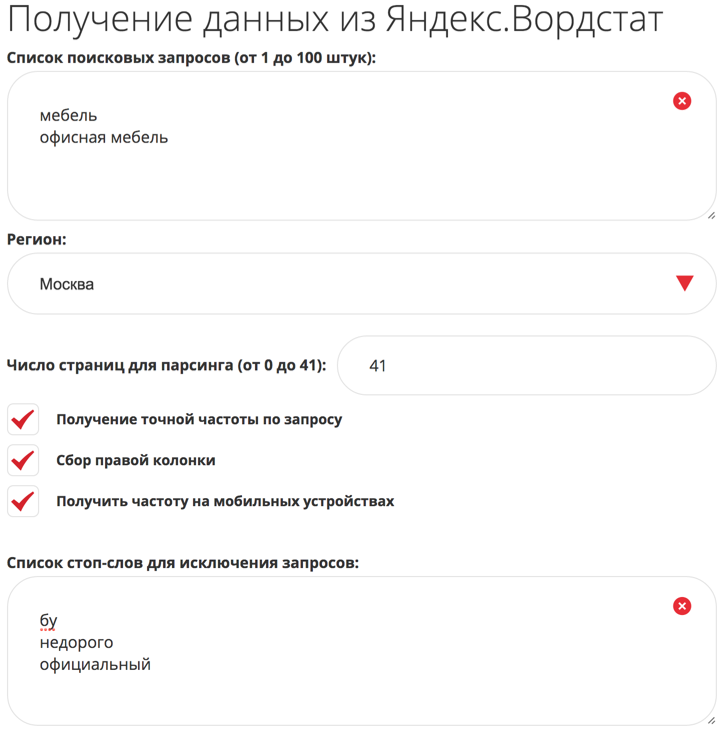
Команда проекта запустила новый экспертный инструмент: «Получение данных из Яндекс.Вордстат». Логика его работы — достаточно простая, доступно множество настроек, что позволяет собрать большое семантическое ядро для проекта в пару кликов, задав:
Регион сбора частот / фраз.
Глубину парсинга Wordstat в страницах.
Получение точной и общей частоты по запросам.
Сбор правой колонки (запросы, похожие на «фраза»).
Получение частот на мобильных устройствах.
Список стоп-слов (для исключения нецелевых запросов по маске).
Удаление НЧ-фраз (если требуется, отсечка — по частоте).
Дополнительная обработка: спецсимволы, запросы с нулевой точной или общей частотой, очень длинные/короткие фразы, условные дубли.
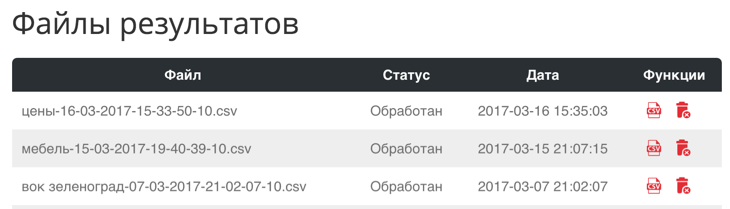
Итоговый файл будет сформирован в облаке (никаких КАПЧ (!) и банов по IP) за несколько минут, а скаченный CSV будет содержать и дополнительные колонки, удобные для дальнейшей работы с семантикой:
Отношение частот (Точная / Общая).
Доля мобильного спроса.
Колонка Wordstat: Левая / Правая.
Число слов в запросе.
Тип фразы (кириллическая, на латинице, с числами, смешанная и т.д.).
Один лимит «Пиксель Тулс» расходуется на парсинг двух страниц с запросами и/или двух точных частот. Истории проверок (парсинга) хранятся в облаке.
Данный инструмент очень хорошо гармонирует с другими источниками семантики:

Удачи в быстром сборе семантического ядра для проектов!