10 причин низких позиций сайта по запросу в выдаче Яндекса и Google
Сегодня мы разберем два главных поинта — формирование поисковой выдачи, поговорим о фундаментальных причинах низких позиций, определим 10 основных причин недостатка релевантности, выясним, как понять, что у нас проблемы с тем или иным поинтом и как улучшить ситуацию.
Анализируем формирование поисковой выдачи
Для начала разберемся в том, что места поисковой выдачи выдаются не просто так. Каждый сайт занимает свою позицию, исходя из численного значения релевантности конкретного url-адреса по конкретному поисковому запросу в конкретном регионе, из которого поступил этот запрос.
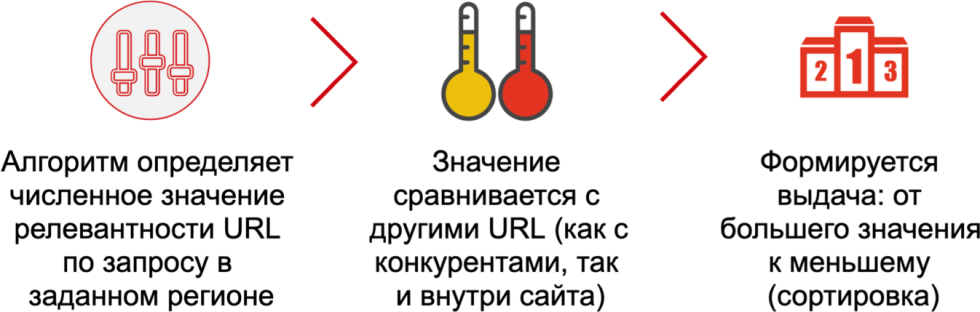
Алгоритм определяет это значение релевантности, это называется формула ранжирования. Это значение сравнивается с другими, в том числе и с конкурентами url в рамках вашего сайта, определяется, каким образом нужно построить какой сайт, на какое место поставить. То есть по большому счету в выдаче формируется сортировка от большего значения релевантности к меньшему, как если бы вы зашли в интернет-магазин и отсортировали все товары от минимальной цены до максимальной. Если вы задаете поисковый запрос, происходит то же самое, только в роли цены выступает численное значение релевантности. Это важная вводная, которую нас самом деле не все понимают, многие говорят, что алгоритмы поисковых систем устроены слишком сложно, не понятно, как они ранжируются. Да нет, они просто ранжируются по исходящему значению релевантности, а дальше давайте разбираться.
Исходя из этого, единственная причина, по которой сайт имеет плохие позиции — это недостаточное значение релевантности, этот момент требует закрепления и запоминания.
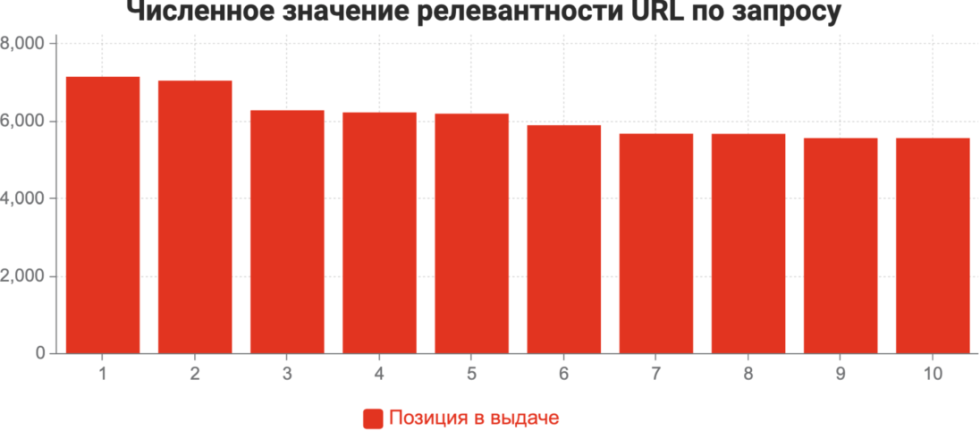
И вот мы видим, что здесь показатели релевантности находятся на отметке 6, 8 млн, витальный ответ часто имеет сильно большой отрыв, например, 10-11 миллионов. Если мы набираем «Пиксель Тулс», на первом месте будет сайт «Пиксель Тулс», витальный ответ, без которого выдача не может быть настоящей. Ну, в общем, есть типичное убывание: первое место отделяется от второго чуть больше, чем второе от третьего и так далее, вначале большие, потом они сокращаются. Но на самом деле, в общем разрывы мизерные, такие, как на представленном слайде.
Выявляем 2 фундаментальных причины низких позиций сайта
Почему релевантности недостаточно? Либо это плохие значения каких-либо факторов, которыми оперируют поисковые системы, и мы не добираем значение, или сама релевантность снижается за счет санкций. На данном этапе все просто. Как работает Пост-фильтр, тестирование на переоптимизацию, что происходит? На самом деле надо понять начальный механизм.
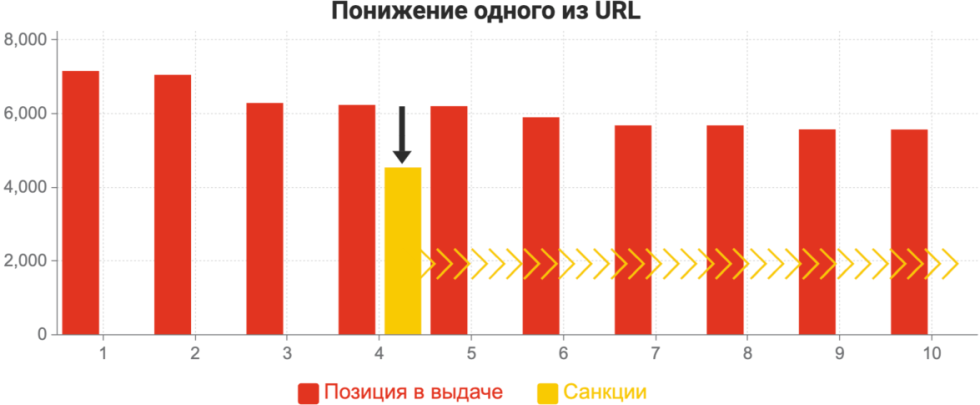
Сайт занимает какую-то позицию, предположим, это четвертое место, значение релевантности, к примеру, 6,2 миллионов. Он получает пенальти, его численное значение релевантности уменьшается, то есть из красного столбика, который был на четвертой позиции, мы получаем желтенький. То есть вычитается что-то, цена уменьшается, дисконт еще говорят. Дисконт в этом понимании – скидка на общественное значение релевантности. В результате вы откатываетесь, по новому значению релевантности нового желтого столбика, куда-то назад. При этом вы может попасть на двадцатое место, иногда, на первое. Иногда бывает так, что документ, находится под какими-то санкциями, если он является витальным ответом на запрос, (он даже может находиться под фильтром переоптимизации, это нормально), и быть на первом месте. Способов диагностики такого конкретного случая достаточно мало, но в целом, в этом нет никакой суперэкзотики.
Многие пишут: «У меня сайт в топе, но переоптимизация диагностирует, что фильтр есть на девятом месте». Да, такое вполне возможно, у вас все нормально по текстовым факторам, вы еще получаете санкции, но не очень сильные, и вы остаетесь. То есть санкции вот такого документного вида не обязательно должны быть выбивающими из ТОП-100.
Вот это новое значение четвертого сайта, который был бы на 4-ом месте без применения санкций, оказывается, предположим, 24-ым. Есть определенный способ это проверить, это делает инструмент «Переоптимизация», проверяя все возможные пути.
Перечень базовых проверок
Мы переходим к анализу причин позиций, связанных с низкими значениями релевантности, если удовлетворены три достаточно простых условия:

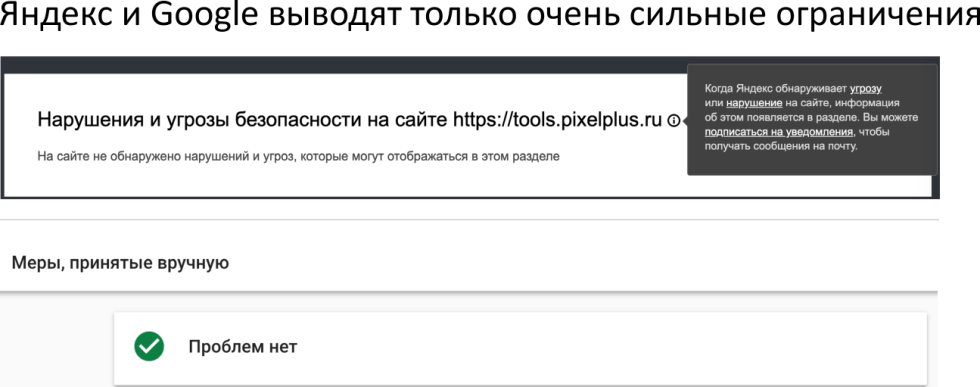
Надо обязательно проверять, был ли продвигаемый url-адрес проиндексирован, не был исключен в апдейт. Такое бывает, что поисковые системы исключают какие-то продвигаемые url-адреса из выдачи в момент апдейта. В панели мастеров нет уведомления о хостовых санкциях, когда мы говорим о Яндексе, в панели помещаются все хостовых санкции за исключением аффилированности, которую Яндекс продолжает скрывать. Но в целом, это довольно редкий кейс — один или меньше одного процента, в результате которого сайт может иметь плохие позиции. И последнее — убедитесь в том, что сайт открывается, доступен для индексации, нет никаких уведомлений о вирусах.
Как это все проверить? Все довольно просто.
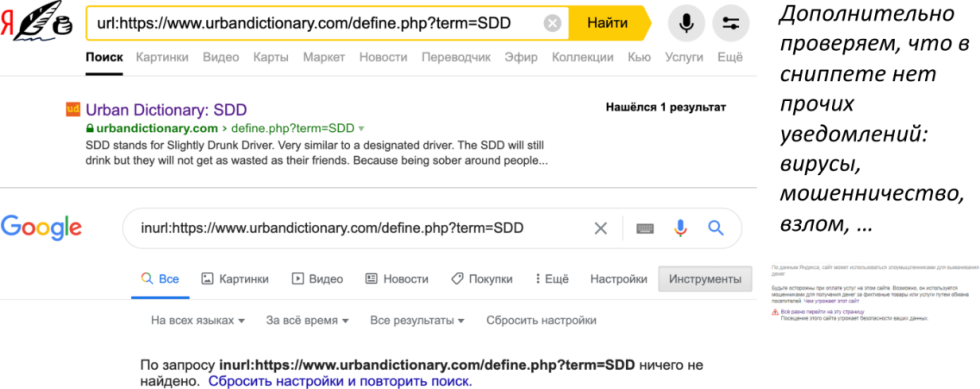
Первое, оператор url в Яндексе, inurl в Гугл или оператор site, мы дополнительно и быстро проверяем, есть ли документ в индексе, есть ли на нем пометки, которые говорят, что он несет угрожающий характер, является мошенническим, взломан и т.д. Для кейса, представленного на слайде, мы видим, что один и тот же документ может иметь хорошие позиции в Яндексе — он в индексе, в Гугле — он не в индексе, соответственно его позиции плохие. Дальше идти смысла нет, причина диагностирована.
Отсутствие хостовых санкций — второй маленький чек-поинт перед тем, как мы делаем анализ. Все просто, открываем наличие мер каких-либо принятых вручную и обязательно смотрите в динамике, чтобы у сайта не было какого-то резкого скачка вниз с точки зрения трафика.
Полный список санкций — https://pixelplus.ru/samostoyatelno/stati/prodvizhenie-saytov/sanktsii-poiskovykh-sistem.html
Сводка Яндекса — https://yandex.ru/support/webmaster/yandex-indexing/webmaster-advice.html
У него был трафик, он резко его потерял, весь, по всем документам, скорее всего, это были какие-то санкции, если у вас не было редизайна, переезда или какого-то другого события. Это можно проследить, даже если бы не было уведомления.
Ну и доступность к индексации, здесь есть инструменты для проверки именно с теми трактовками и теми правилами, которые видят поисковые системы.
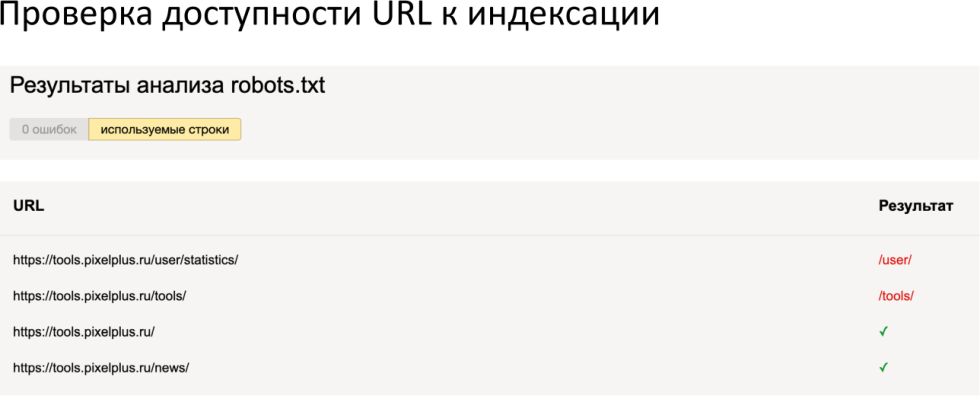
Сервис проверки: http://webmaster.yandex.ru/tools/robotstxt
Здесь достаточно интересно, что иногда бывает, что Гугл, к примеру, в инструменте пишет, что доступно, а робот пишет, что недоступно, правила могут интерпретироваться по-разному. Более того, есть такая библиотека, которая обрабатывает robot.txt так же, как Гугл.
10 причин недостатка релевантности
Если были соблюдены предыдущие условия и сайт прошел базовую проверку, то мы переходим к 10 причинам недостатка релевантности. Если же все или хотя бы один из поинтов не выполнен, то есть вы не проверили, что у вас нет хостовых санкций, что документ в индексе и нормально индексируется или есть грешок с индексацией, то можно идти дальше. Три промежуточных поинта, которые не были внесены в список 10 причин (просто мастхэв), они встречаются не более, чем в 5% случаев.
Давайте перейдем к десяти основным причинам недостатка релевантности, поговорим о том, как определить, что причина заключается в этом, и как улучшить каждый из этих факторов.
1. Региональная привязка
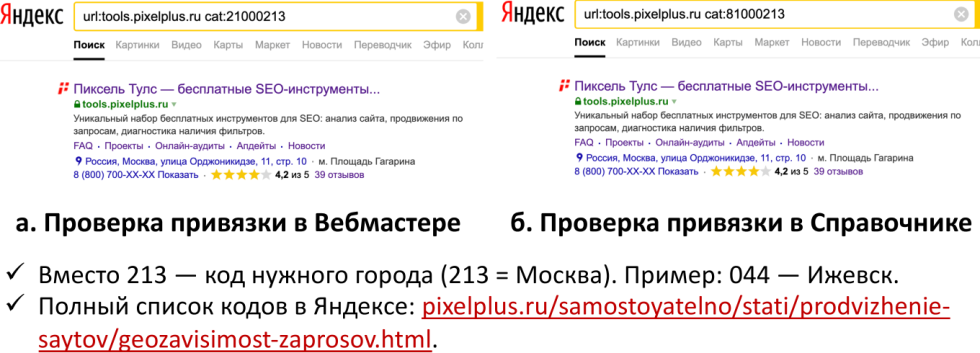
Для геозависимых запросов важно совпадение региона пользователя и региональной привязки конкретного url-адреса.
Полный список кодов в Яндексе — https://pixelplus.ru/samostoyatelno/stati/prodvizhenie-saytov/geozavisimost-zaprosov.html
Что это значит? Это значит, что данный url-адрес должен быть или желательно, как минимум, привязан к панели вебмастера и должен быть зарегистрирован на адресе организации, если мы говорим обо всех геозависимых, коммерческих запросах и т.д. Вы можете проверять это с помощью панели, мы рекомендуем именно такой способ, потому что он проявляет привязку конкретного url-адреса, и вы можете вместо кода 213 (это Москва), использовать Ижевск, Вологду, Санкт-Петербург, Минск, что угодно. Полный список городов представлен по ссылочке здесь — заходите, пользуйтесь, вбивайте.
Даже если одна из основных проверок, панель вебмастера и справочник отсутствует, то, в первую очередь, нужно заморочиться на тему региональной фильтрации и региональных вариаций факторов ранжирования. Региональные вариации представляют собой огромное количество факторов ранжирования. Смысл в том, что к большому количеству факторов применяются региональные вариации. Если упростить, то высчитывается количество Page Jump — страниц, потом высчитывается Page Jump-страницы с учетом ссылок только из того региона, из которого пользователь.
2. Возраст документа
Вторая по значимости причина недостатка релевантности — возраст документа. Причем, маленький возраст — это не суперсамостоятельная причина, просто это приводит к определенному набору следствий — отсутствие нормальных значений по ряду факторов.
Инструмент «Пиксель Тулс» — https://tools.pixelplus.ru/tools/vozrast
К примеру, если возраст очень маленький, то, многовероятно, у вас будут низкие или просто не вычисленные значения каких-либо поведенческих факторов, они будут заменяться средними. Грубый пример: допустим, вы заводите объявление в Яндекс Директ и вам надо это объявление Яндекс Директу как-то ранжировать в выдаче, понять, какой у него CTR (коэффициент кликабельности). Как известно, чем больше CTR, тем выше объявление, то же самое и в выдаче. Но CTR не известен, поэтому используется дефолт, то есть соединенный CTR, который прогнозируется, исходя из определенных каких-то вещей.
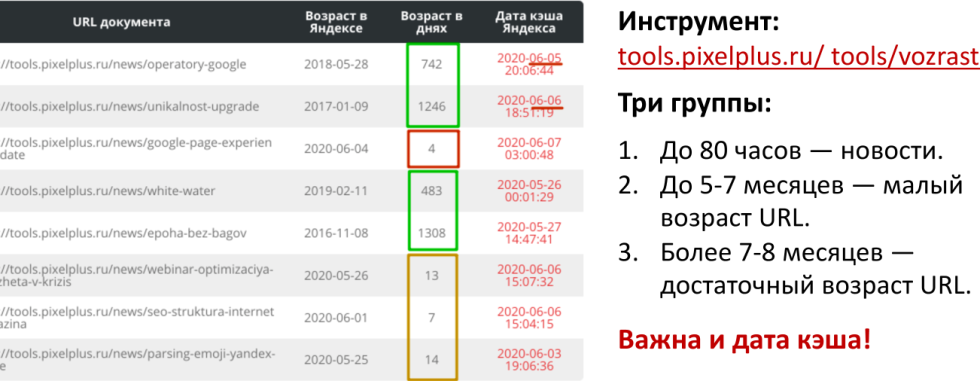
В «Пиксель Тулс» есть инструмент для проверки возраста документа, здесь можно выделит три основных группы:
-
До 80 часов — новости. Они, кстати, ранжируются по своей особой формуле, поэтому они часто попадают в топ. Потом проходит три дня, документ пропадает, попадает в основной индекс, выпадает значительно ниже. Это связано с тем, что он как-то ухудшился, а с тем, что новый документ имеет некий boost ранжирования. Например, свежее видео на YouTube канале или в Facebook «Пиксель Тулс» имеет определенный приоритет, так как это свежий контент.
-
До 5-7 месяцев — малый возраст url.
-
Более 7-8 месяцев — достаточный возраст url.
Например, Яндекс дает бонусы не только тем url, возраст которых старше 7-8 месяцев, но и плоть до нескольких лет. То есть более возрастные url-адреса имеют небольшой плюс. Важна еще и дата КЭШа, которая проверяется в отдельной колоночке в Яндексе, она не должна быть очень старой. На самом деле, документы, которые вообще никак не обновляются, редко посещаются поисковыми роботами. Если для вас это настолько важный документ, что вы вручную начали диагностировать причину низких позиций на него, то скорее всего старая дата КЭШа (несколько месяцев, лет относительно текущей даты) — плохой признак. Дату КЭШа следует непременно обновить, сделайте себе такую пометочку.
3. Нужный тип сайта выдачи
Нужный тип сайта выдачи — частая проблема, с которой сталкиваются при продвижении какого-то конкретного запроса.

Инструмент — https://tools.pixelplus.ru/tools/complex-queries-analyser
Это проверяется с помощью инструмента комплексного анализа запросов и анализа типов сайта выдачи, когда мы можем быстро посмотреть, что требуется. Один из кейсов, который мы видим здесь, запрос «продукты», большое количество информационных сайтов, мы можем их продвигать. Но в каком-то случае информационных сайтов «0», как это видно по запросу «мебель». Если у вас информационный сайт по этому запросу, скорее всего, вы не продвинетесь, потому что таких типов выдачи сайтов нет.
Как это работает? Поисковая система достаточно хорошо определяет, какие потребности у пользователей, и первая фильтрация по типу сайта часто не проходит. То есть если у запроса достаточно хорошая частота, то ваше продвижение в ТОП на этом этапе заканчивается. Это работает для запросов с нормальной частотой, то есть, если запрос новый или у него низкая частота, то эта логика не применяется, поисковая система в данном случае имеет гораздо меньшую выдачу. Основная борьба инженеров вообще ведется за улучшение ранжирования запросов, по которым частоты нет.
4. Интент и тип документа
До этого мы работали на уровне сайте, теперь пришло время углубиться на глубину документа, чтобы понять, сочетается ли наш тип документа с потребностью пользователя.

Инструмент — https://tools.pixelplus.ru/tools/complex-queries-analyser
С помощью инструмента можно посмотреть уже не тип сайта в выдаче, интент и пользователя по запросу, мы раскладываем уже по интентам, и основные параметры для коммерческих сайтов. Самый важный параметр — коммерциализация выдачи, она должна быть достаточно большой. Это значит, что количество коммерческих результатов выдачи должно быть, как правило, в районе 30% и более. Если показатель выше 30% — это «фиеста», если ниже — придется столкнуться с определенными сложностями.
При этом полезно учитывать не только интент, но и слова, задающие тематику. Мы можем просто по определенному набору слов, который часто встречается в результатах выдачи, определить потребность, при этом, не заглядывая в выдачу, это очень полезно, когда запросов много. При этом мы просто смотрим частотные слова выдачи и сразу говорим, подходит или не подходит. Ну и конечно, если запросов мало или он один, вы можете просто набираете его, идете в выдачу и оцениваете, какой тип документов там.
Это важное совпадение — региона, типа сайта, типа документа с тем, что вообще требуется пользователю. Но на самом деле сайтов у поисковой системы по всем поисковым запросам, как мелкой рыбешки в океане. Их настолько много, что она может выбирать, какую конкретную съесть. В этот момент времени может что-то пойти не так, то есть мы можем не добрать значение релевантности, исходя из показателей внутренней, внешней оптимизации поведенческих факторов. Это основные причины, о которых мы будем дальне говорить.
5. Внутренняя оптимизация
Пятая причина, которая влияет на низкие значения релевантности — внутренняя оптимизация, причем не глобально, а конкретно — Title, H1 и метатеги. На самом деле, очень большая часть итогового численного значения релевантности в формуле ранжирования определяется исходя из двух составляющих, а третий, мета содержимое, говорит о том, насколько он хороший CTR имеет документ выдачи.

Эта тема уже была достаточно подробно рассмотрена на одном из вебинаров, пересмотреть который можно по ссылке, там мы говорили о Title, обсуждали кейсы, конкретные примеры. Понятно, что это довольно важное ранжирование не только с точки зрения CTR, но и с точки зрения общего вклада в итоговое значение релевантности.
Поэтому Title учитывается не только в факторах, там есть и другое:
-
факторы, которые, к примеру, приписывают Title к тексту;
-
есть факторы, которые рассчитывают значение BM25 в случае, если Title был в роли поискового запроса.
То есть важно, чтобы Title был будто бы поисковым запросом, при этом ранжируется текст. Грубо говоря, определяется, насколько релевантен Title с текстом, это тоже весомы параметр. То есть очень важно уделить ему внимание. По сравнению с обычным текстом, заголовок Н1 имеет приоритет, порой отображается в выдаче, то же самое касается и Description. Он не участвует в ранжировании, то есть прямое включение туда ключей не важно, но важно, чтобы он отражал суть страницы, отображался на выдаче. За этим надо следить, чтобы он привлекал, завлекал.
На всякий случай, напоминаем критерии для тега Title, который лучше всего заскринить или записать.

6. Текстовая оптимизация
Здесь невозможно раскрыть тему полностью быстро, так как моментов и инструментов много. Мы остановимся на двух основных, которые используются, и основных факторах, которые действительно важны.
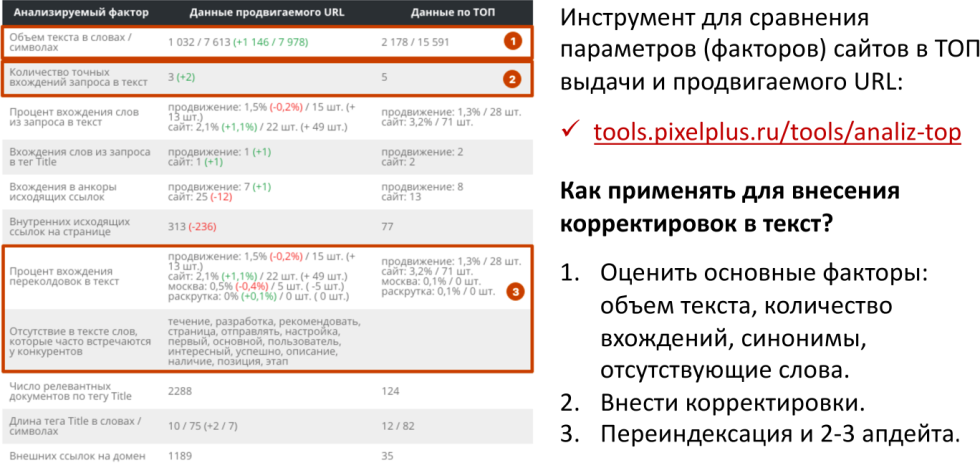
Инструмент — https://tools.pixelplus.ru/tools/analiz-top
У нас есть инструмент «Анализ ТОП», который делает довольно простую вещь. Он берет все документы и тексты, которые ранжируются в выдаче, и сравнивает их и ваш документ по определенному набору факторов. На что стоит обратить внимание:
-
объем текста;
-
количество вхождений;
-
синонимы;
-
отсутствующие слова в вашем тексте.
Все эти факторы выводятся, подсвечивается, какое значение на текущий момент у вас, отображаются данные продвигаемого url, данные по ТОП-10, чего не хватает и т.д.
Новый инструмент — «ТЗ на копирайтинг в помощь»
Новый инструмент направлен он на то, чтобы писать грамотные тексты.
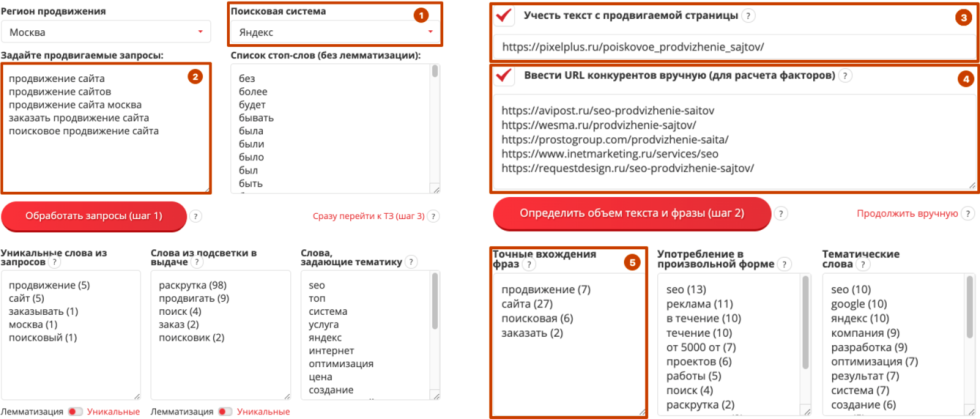
Инструмент — https://tools.pixelplus.ru/tools/copywriters-advanced
Почему он важен и крут именно в текстовой оптимизации, когда у вас уже есть документ и у него плохие позиции:
-
вы просто вводите список поисковых запросов (задаете все продвигаемые);
-
в поле номер «1» вы вводите поисковую систему (он работает и с Яндексом и с Гугл, как и анализ ТОП);
-
дальше вы говорите, что хотите учесть тот текст, который уже располагается на вашей странице;
-
вводите продвигаемый url-адрес;
-
вводите вручную список конкурентов либо просто нажимаете «обработать запросы»;
-
инструмент обработает и найдет список конкурентов, которые имеют самые хорошие позиции именно по списку поисковых запросов, и проведет текстовый анализ.
Что это значит? Будет определен объем вашего текста, средний объем конкурентов, скажет, чего не хватает, сколько не хватает, укажет, каких вхождений не хватает. Кстати, точное вхождение фраз (поле №5), оно заполняется, исходя из документов выдачи, и вы может понять, каких вхождений не хватает. То есть, в среднем, если слово «продвижение» встречается в выдаче на сайтах конкурентах, которые ранжируются, например, 20 раз, но у нас 13, то не хватает, соответственно, 7. То есть вам придется только дописать, немного откорректировать, дооптимизировать. То же самое со словами, которые можно в произвольной форме употреблять. Инструмент новый, нам крайне важен фидбек, чтобы мы могли его доработать и максимально усовершенствовать.
Что делать, если запросов тысячи?
Если запросов действительно много, с точки зрения текстовой оптимизации, отслеживать, вводить каждый поисковый запрос вручную сложно. Для этого вам нужно вести проект в «Модулях проектов», ввести для каждого поискового запроса, какая страница продвигается, значение факторов при этом проверяется автоматически, возможна фильтрация, есть выгрузка, вы можете выгрузить текущий объем текста, текущий Title, текущий тег H1 напрямую в Excel. К примеру, это часто используют как некоторые слепки, хотя они тоже хранятся, вы можете выгрузить любую дату.
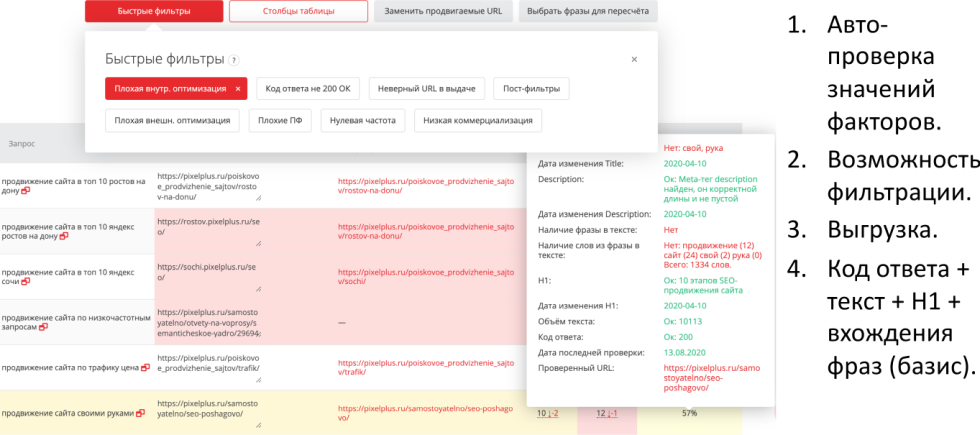
В частности, по запросу «продвижение сайта своими руками» видно, что в Title отсутствуют слова «свой, «рука», которые встречаются в поисковом запросе, здесь приведены к нормальному виду с точки зрения русского языка. Их надо добавить, в результате, очевидно, ранжирование улучшится. И есть быстрый фильтр, с помощью которого можно посмотреть все запросы, по которым плохая внутренняя оптимизация.
На самом деле мы сейчас сделали агрегацию по TO DO. Рекомендации по каждому запросу это, конечно, важно и очень ценно, но мы должны понимать, что для каждого url-адреса есть несколько поисковых запросов, которые не него продвигаются. И конечно, хотелось бы видеть рекомендации по текстовой оптимизации тега Title и так далее, исходя их всех запросов, которые на него продвигаются.
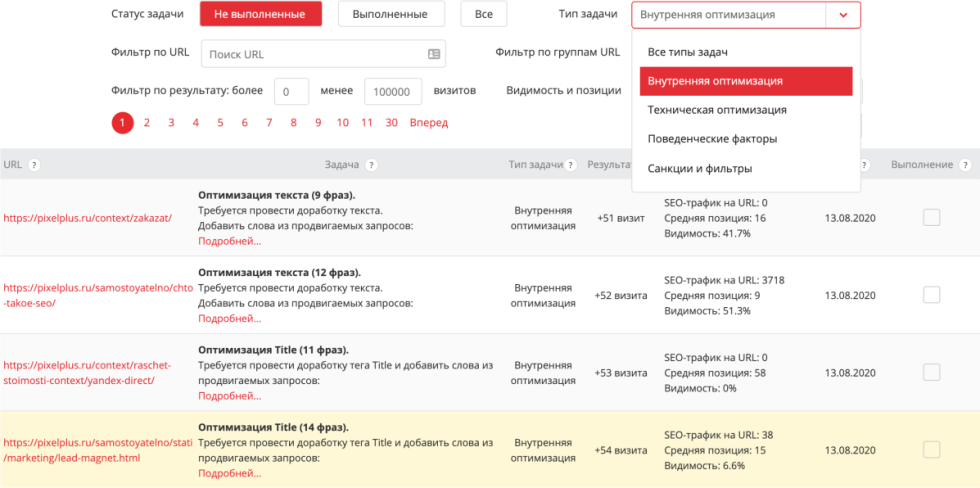
Инструмент — https://tools.pixelplus.ru/projects/5/todo
Мы это сделали и добавили определенный прогноз, какой объем трафика это может привлечь, исходя из текущего значения видимости, и того профита, который он обычно дает. То есть это наша оценка того, какой профит может дать доработка Title, и вы, конечно, можете начинать с тех задач, которые дают максимальный результат. Получить рекомендации можно по любому вашему проекту, главное, чтобы в вашем файле было указано корректное распределение на продвигаемые страницы, которые вы хотите видеть. Они изначально определяются, исходя из релевантных позиций в выдаче, но иногда это не совпадает. Этот вопрос подробно рассмотрен на нашем вебинаре, посвященному проектированию оптимизированной структуры.
7. Запросозависимые поведенческие факторы
Судя из названия, факторы зависят от запроса, их вычисляют, исходя из поведения пользователей. Простое определение поведенческих факторов — это факторы, которых бы не было, если бы не было пользователей.
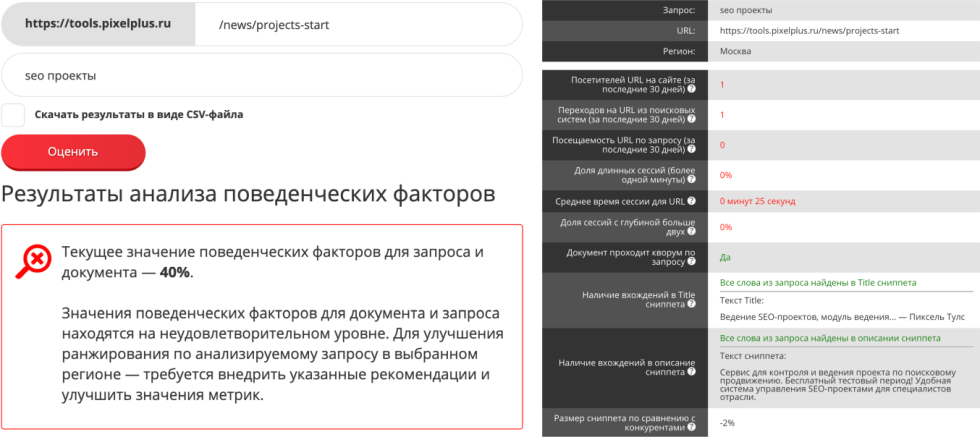
Инструменты — https://tools.pixelplus.ru/tools/pf и https://tools.pixelplus.ru/tools/pf-google
Является ли наличие калькулятора, номера «8-800 …, фильтрации на сайте, удобной формы заказа поведенческими факторами? Нет, не является, так как они присутствуют независимо от того, есть пользователи на странице или нет.
В то же время есть очевидные факторы, которые зависят от наличия пользователей:
-
среднее время, проводимое пользователями на странице;
-
количество сессий, на которых пользователи просмотрели две страницы и т.д.
Таким образом, без пользователей таких показателей просто бы не было. У вас есть возможность все эти факторы оценить, сделать это легко. Введите поисковый запрос, введите конкретную продвигаемую страницу, для которой будет оцениваться поведенческий фактор.
Что здесь оценивается:
-
запрос;
-
url;
-
регион;
-
количество посетителей, которые были на данном url-адресе по данным запросам;
-
какой процент пользователей закончили просмотром двух страниц длительностью более 1 минуты.
Есть определенные нормы, которые высчитаны, исходя из некоторого порогового значения, начиная с которого документ, как правило, не испытывает проблем в ранжировании. Понятно, что эта норма зависит от запроса, потребностей пользователей, горячая или холодная тематика, но, в целом, это удобная и понятная норма. Если эта норма превышена, то есть у нас много пользователей задерживается на странице, то значение факторов зелененькое, если мало — красное, за этим нужно следить.
Надо понимать, какая потребность у вашего пользователя, который пришел по конкретному поисковому запросу и решать ее. То есть, в первую очередь, если у пользователя набор каких-то потребностей, например, поиск мебели, ваша задача:
-
предоставить удобный поиск мебели;
-
организовать быструю загрузку;
-
добавить интерактивные элементы (калькулятор, фильтрацию, сортировку);
-
информационные, хабовые страницы;
-
дополнительные материалы, видео.
Грубо говоря о вовлечении пользователя, ваша задача — удержать, завлечь аудиторию. Возможно, это будет видео, где вы рассказываете, что ваша мебель самая крутая, подробно расписываете ее достоинства.
Дополнительная штука — возможность оценить CTR по запросу. Она работает только, когда у вас достаточная статистика, поэтому мы работаем только с ТОП-500 поисковых запросов в Яндекс-вебмастере.
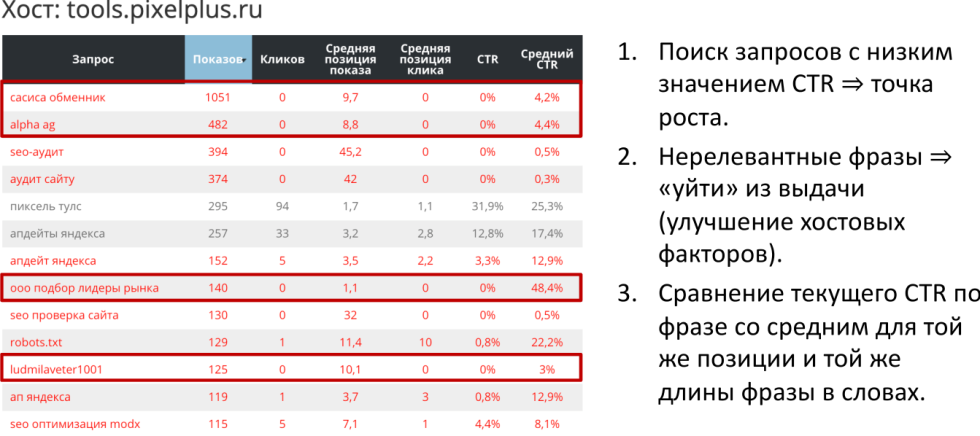
Инструмент — https://tools.pixelplus.ru/tools/zaprosy-webmaster
Это соседний инструмент оценки поведенческих факторов, он называется «Запрос из Яндекс.Вебмастер». Он достаточно быстро работает, выгружает список поисковых запросов, по которым у вас много показов. Дальше он определяет, какое количество кликов, какая средняя позиция клика, средняя позиция показа, это все данные из Яндекс.Вебмастера. А вот дальше уже сравнивает CTR, который выдал Яндекс.Вебмастер с той средней кликабельностью, которая характерна для данных поисковых запросов на данной позиции. То есть, если вы имеете тысячу показов и при этом эти показы, пускай, осуществляются в районе 10 места, то в среднем CTR должен быть 3-4% предположим.
Если у вас CTR = 0, то это плохой признак, но с этим можно работать, например:
-
переоптимизировать так, чтобы завлечь пользователя из выдачи уже, Title, метатега или Description на свой сайт;
-
решение может быть обратным — ограничение показа сайта по этим не очень подходящим запросам, потому что эти показы приводят к глобальному ухудшению поведенческих факторов на выдаче и т.д.
Решение в целом зависит от вас, главное найти правильные и перспективные точки роста. Конечно, запросов бывает много, справиться с ними поможет модуль ведения проектов, конкретно, инструмент TO DO. Он умеет делать рекомендации, исходя не только из Title и внутренней оптимизации, но и учитывает поведенческие факторы.
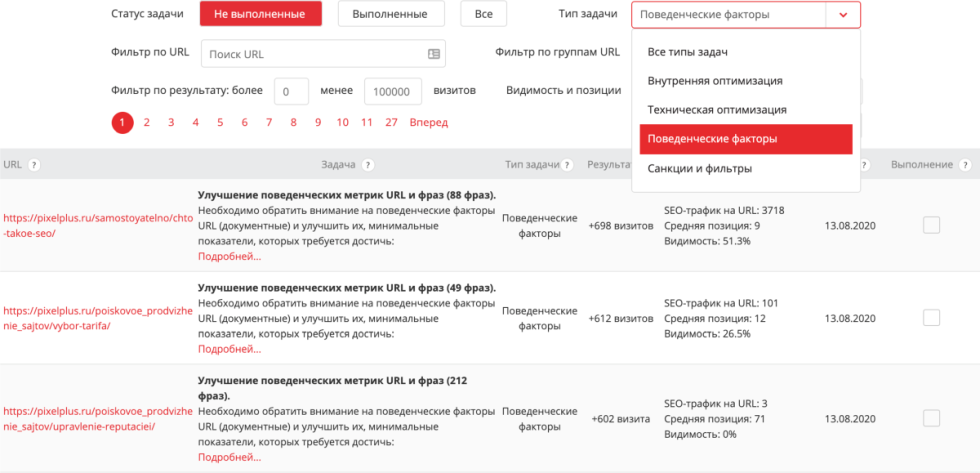
TO DO: https://tools.pixelplus.ru/projects/2312/todo, где вместо 2312 — ID вашего проекта.
Он может сказать, что у данного url-адреса есть список поисковых запросов, по которым плохие значения поведенческих факторов. Исходя из этого, вы можете посмотреть, сколько таких фразе всего, куда ведут эти фразы и какой потенциал роста здесь может быть, если вы будете каким-то образом улучшать взаимодействие. Например, если это просто статья, то достаточно сделать ее более качественной и структурированной.
К тому же после прочтения важной интересной статьи, вам необходимо задержать пользователя, не дать ему уйти. С этой целью на сайты часто внедряется бесконечный скролл. Посетитель долистал до конца статьи, решил свою потребность, тут же ему предлагаются релевантные статьи, похожие материалы. Рекомендательная система хорошо развивается, хорошо бы применять ее в своей практике.
8. Внешние факторы (ссылки)
Ссылки важны, их значимость сильно зависит от поисковой системы. Как показывают наши исследования, есть статистическая значимость, как минимум, трех факторов, которые дают значимый результат на текущий момент:
-
ссылки на url с вхождением в анкоры слов из запроса, если они фильтруются;
-
наличие и количество ссылок на url-адрес со всеми словами анкора;
-
общехостовая прокачка, когда мы, неважно на какую страницу, главное, чтобы на сайт вели ссылки.

Конечно, выводы зависят от поисковой системы. Мы проводили подробное исследование в 2019 году, в результате поняли, что в Яндексе присутствует корреляция.

Ее можно назвать средней, но она есть во всех четырех факторах, которые мы оцениваем в панели вебмастера. Если мы говорим о Гугл, то два сильных фактора — ссылок на url с вхождениями слов из запросов и ссылок на url со всеми словами запроса.
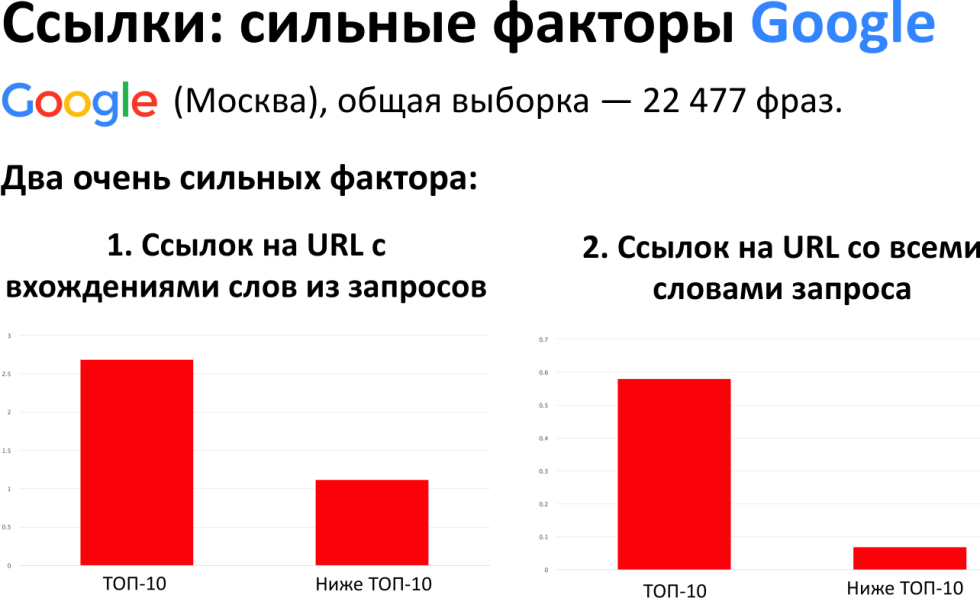
Исходя из этого, есть смысл оценивать эти факторы. Рекомендации по этим факторам скоро появятся во вкладке TO DO в модуле ведения проектов, они будут агрегированы по url-адресам. Единственное что, надо будет дополнительно делегировать панель Яндекс.Вебмастер, чтобы оттуда ссылки показать.
9. Коммерческие факторы
Это некоторая добавка к ранжированию. Есть большое количество коммерческих факторов, поисковых систем, которые оперируют внешними, внутренними, поведенческими факторами и отдельной группкой коммерческих, оценивающих, насколько правильный, грамотный бизнес стоит за сайтом.
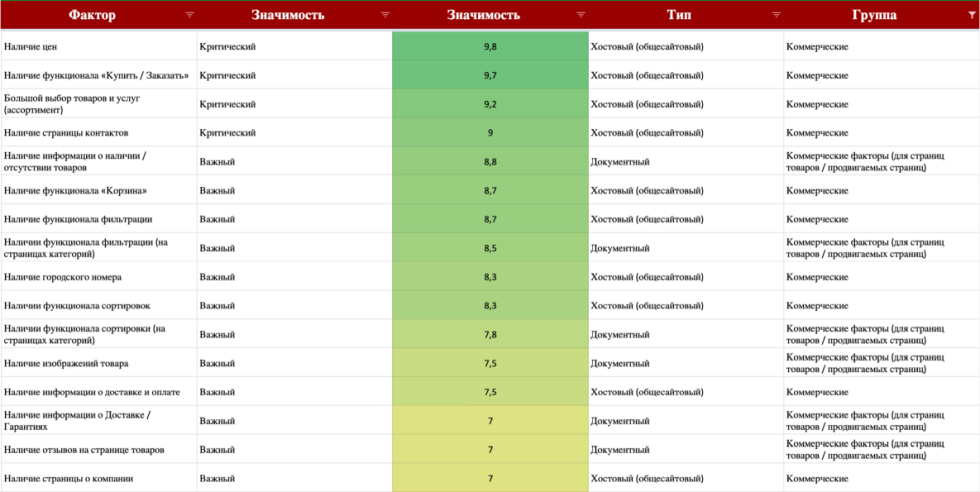
Полный рейтинг факторов ранжирования можно скачать у наших коллег их Пиксель Плюс по ссылочке. Сюда входят такие базовые вещи, как:
-
наличие цен;
-
наличие функционала «купить», «корзина»;
-
большой ассортимент;
-
наличие страницы контактов;
-
информация об отсутствии товаров и так далее.
Их очень много, по сути дела, вам требуется идти по очереди, постепенно прорабатывая каждый из них, проверять, насколько качественно у вас сделан тот или иной момент.
Часто под коммерческими факторами подразумевают в широком смысле проработку страницы сайта для повышения конверсии и для улучшения поведенческих метрик. Это не совсем корректно. На самом деле в Яндексе есть определенная группа факторов, которые действительно являются коммерческими, она была специально придумана для оценки качества бизнеса. Но в широком смысле слова вполне нормально подходит, что мы вообще работаем над повышением конверсионности трафика и поведенческих факторов.

Проработка коммерческих факторов положительно сказывается на доверии пользователей, так как продажи равно доверие. Если человек совершает у вас покупку, значит, он вам доверяет, и наоборот — отсутствие факта покупки говорит об отсутствии доверия. Важно, не путать коммерческие и поведенческие факторы.
10. Адаптив и тех. параметры
Заключительная причина, которая влияет на недостаток релевантности — адаптив сайта, то есть нормальная адаптивная версия сайта, и технические параметры.

В этой группе мы осмысленно объединили сразу несколько разношерстных причин только потому, что они встречаются чуть реже. На самом деле технические показатели сайта могут существенно влиять на ранжирование при переходе через некоторые пороговые значения. Что это значит? Одна обидная ссылка, мусорная страница или недооптимизированный адаптив, как правило, сказывается на ранжировании не существенно. Но накопление этих причин, как снежный ком — сотни или тысячи битых ссылок, множество мусорных страниц, кстати, это нередкий кейс, снижают показатели ранжирования сильно, и дело тут совсем не в перфекционизме.
Здесь все довольно просто:
-
неудовлетворительные показатели Mobile-Friendly test, который имеет каждая поисковая система;
-
большое количество ссылок на несуществующие страницы;
-
низкая скорость загрузки, хотя она напрямую и не влияет на ранжирование.
В случае с низкой скоростью, речь идет о пороговом значении, когда пользователи начинают покидать ваш сайт. С аптаймом сервера дела обстоят так же: 99,999 — это одна история, 99,998 — другая, 99 — третья. На самом деле, один процент не работы сайта может быть определенным порогом. Размер исходного кода, его исходный размер может быть замусорен, но если код насколько большой, что поисковая система не может его прогрузить, это уже порог, ниже которого нельзя опускаться.
Ну и массовая проверка, мы предлагаем массовые проверки, потому что сайтов много, в каждом из них много страниц, и есть определенные пороги.
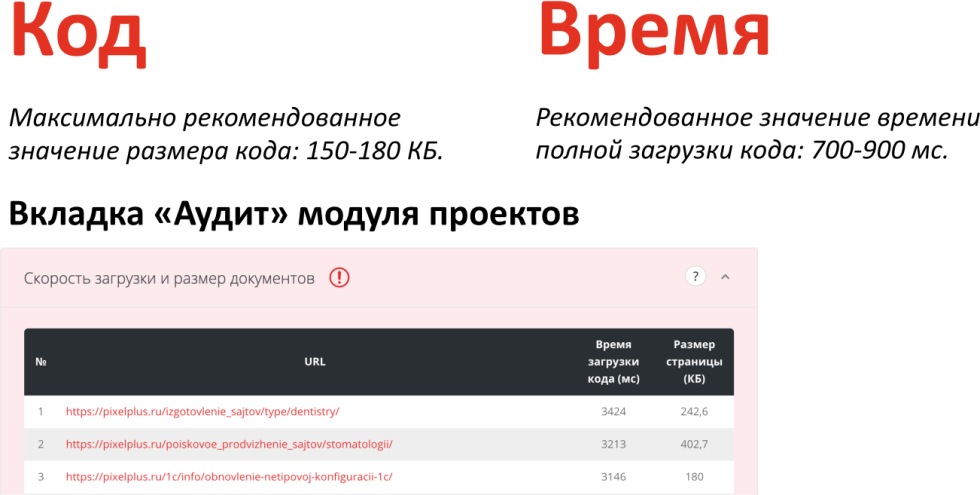
Максимально рекомендованное значение кода — 150-180 Кб, при этом, 180 — это уже достаточно много, 200 — тем более, здесь надо работать, скорее всего, с исходным кодом. Что касается времени полной загрузки именно кода — 700-900 мс. При этом, есть порог, опускаясь ниже которого сайт может считаться нерабочим, хотя это и не воспринимается остро поисковой системой.
95% всех кейсов, с которыми мы встречаемся, попадают в разобранные 10 причин низких позиций сайта в выдаче, не считая каких-то санкций.
Запись вебинара
Чтобы не пропускать новые материалы, подписывайтесь на наши группу ВКонтакте, чат Telegram и канал YouTube.

Рейтинг статьи:
По оценкам 38 пользователей

Другие материалы