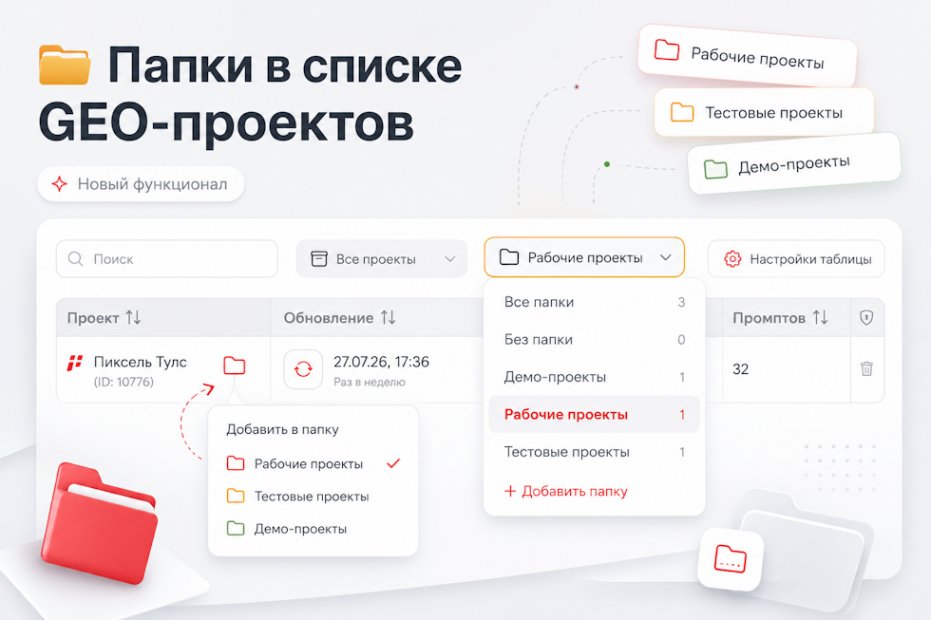
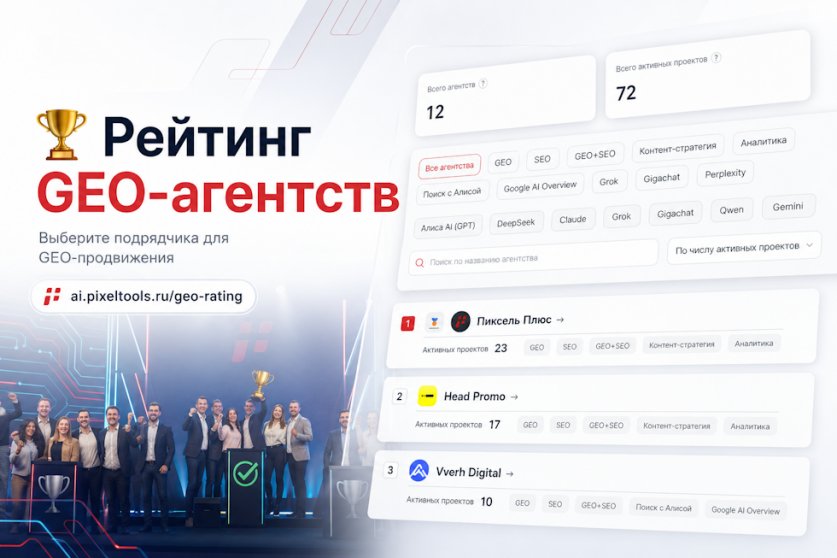
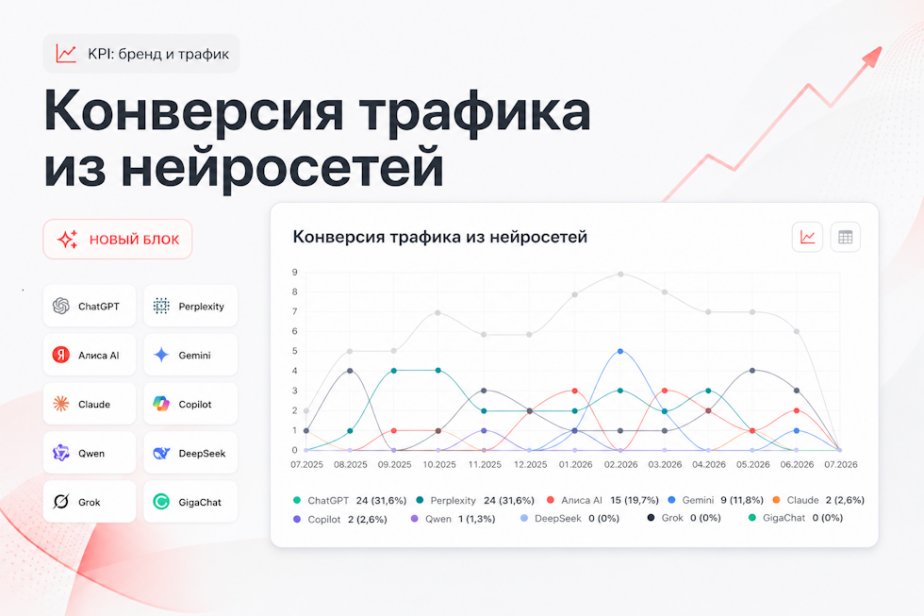
Новая функция в GEO-проектах покажет, на каких источниках из ответов нейросетей упоминается ваш бренд.
SEO-специалистам учить язык программирования вовсе не обязательно, но понимание принципов сканирования и рендеринга поможет превратить JS из помехи в союзника. Давайте разбираться, что к чему!
Речь пойдёт о технической оптимизации. Абсолютное большинство сайтов используют JS для улучшения пользовательского опыта, сбора статистики, интерактивности, загрузки контента, меню, кнопок и других элементов. Наша цель, как SEO-специалистов, облегчить процесс сканирования контента и по возможности избегать проблем, которые часто возникают при обработке страниц, использующих JavaScript.
Руководство частично основано на материалах от Ahrefs, Onely, Google Developers, за что им большое спасибо.
Поисковые системы пытаются получить тот же контент, что видят в браузере пользователи. В Google за процесс рендеринга и сканирования отвечает сервис обработки веб-страниц Web Rendering Service (WRS, часть системы индексации Caffeine). Вот упрощенная схема процесса:
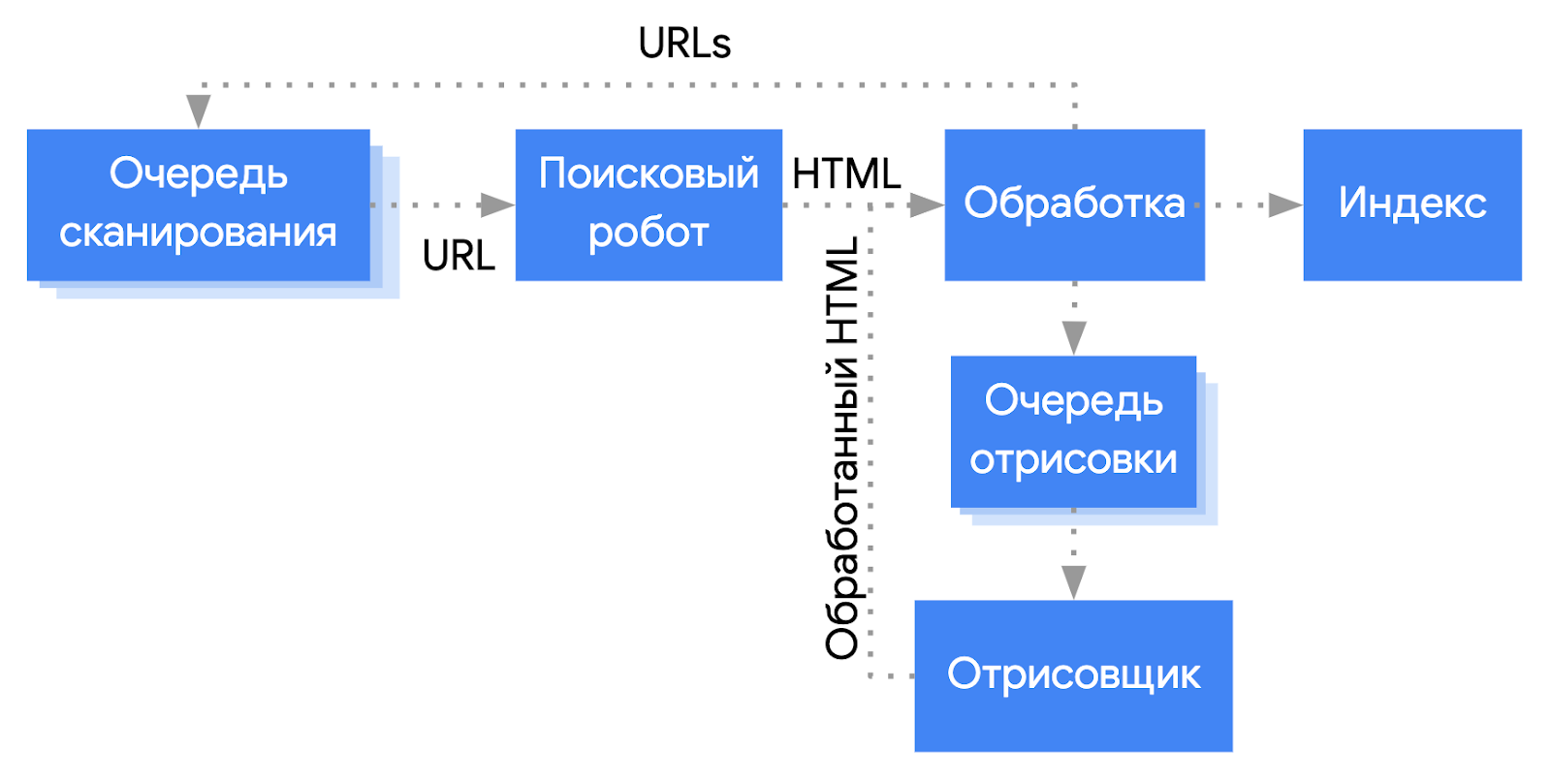
Обратите внимание, на схеме Google получает конечный HTML для обработки, но на деле сканирует и кэшируют почти все дополнительные ресурсы, необходимые для формирования страницы (JS-файлы, CSS, синхронные и асинхронные запросы XHR, точки приёма API и так далее). Почему «почти» все? Некоторые из ресурсов Googlebot и WRS могут игнорировать, как недостаточно важные для отображения контента.

Разберём процесс на примере отдельного URL.
Робот Googlebot отправляет серверу GET-запрос, в ответ получает HTTP-заголовки и содержимое страницы. Если в заголовке или мета-теге robots нет запрета на сканирование, то URL ставится в очередь на отображение. Подробнее о способах закрытия от индексации мы рассказывали в отдельном руководстве.
Важно учитывать, что в условиях mobile-first-индексации в большинстве случаев запрос поступает от мобильного user-agent Google. Проверить, какой робот сканирует ваш сайт можно в Search Console (раздел «Проверка URL»).
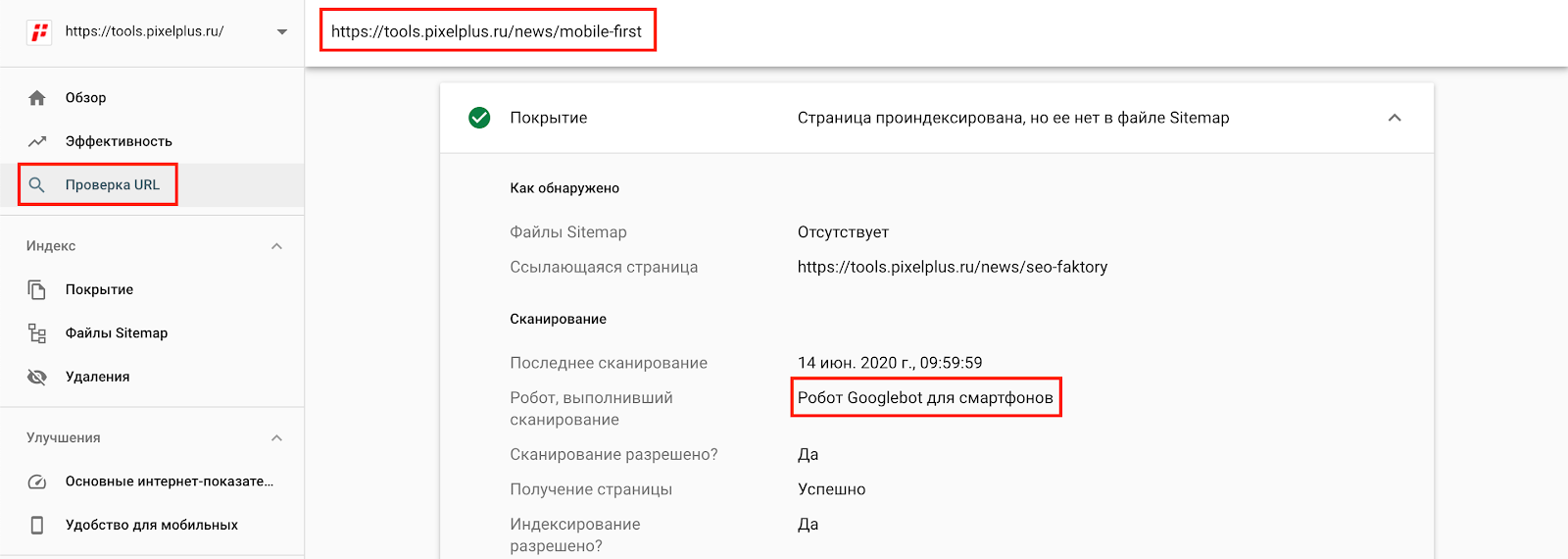
Нужно иметь в виду, что в HTTP-заголовках страницы можно настроить правила для отдельных user-agents, например, запретив для них индексацию или показывая отличный от других контент. Ниже пример запрета перехода по ссылкам для Googlebot и индексации для всех остальных.
HTTP/1.1 200 OK
Date: Tue, 25 May 2020 21:42:43 GMT
(…)
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
(…)
Здесь важно учитывать некоторые нюансы.
Частью обработки страницы является обнаружение и сканирование ссылок на другие URL и файлы, необходимые для построения HTML-документа. Каждая из ссылок попадает в очередь на сканирование и обладает различным приоритетом. Для подгрузки CSS- и JS-файлов используется тег <link> для внутренних и внешних ссылок — тег <a> с атрибутом href. Почему напоминаем о таких очевидных вещах? Взгляните на примеры реализации ссылок.
Хороший вариант:
<a href="/page">просто и правильно</a>
<a href="/page" onclick="goTo(‘page’)">тоже хорошо</a>
Плохой вариант, если вы, конечно, хотите, чтобы ссылки были понятны поиску:
<a onclick="goTo(‘page’)">не пойдёт, нет href</a>
<a href="javascript:goTo(‘page’)">нет ссылки</a>
<a href="javascript:void(0)">нет ссылки</a>
<span onclick="goTo(‘page’)">неподходящий тег</span>
<option value="page">неподходящий тег</option>
<a href="#">нет ссылки</a>
Важно помнить, что ссылки, подгружаемые с помощью JavaScript, не будут обнаружены до окончания процесса рендеринга. Это значительно замедляет процесс сканирования сайта, ведь Google приходится постоянно корректировать структуру и относительную важность страниц по мере рендеринга и обнаружения новых ссылок, реализованных с помощью JS.
Все загружаемые файлы, включая HTML, JS и CSS активно кэшируются Google, при этом ваши настройки тайминга будут игнорироваться, а новую копию Google загрузит по своему усмотрению. Это может привести к использованию уже устаревших ресурсов JavaScript или CSS. Возможное решение — использование «цифровых отпечатков контента» в названии файлов, например, вида: main.2bb85551.js.
Благодаря отпечаткам, при каждом обновлении файла будет создаваться его новая копия и Google сможет использовать актуальную версию для обработки страницы.
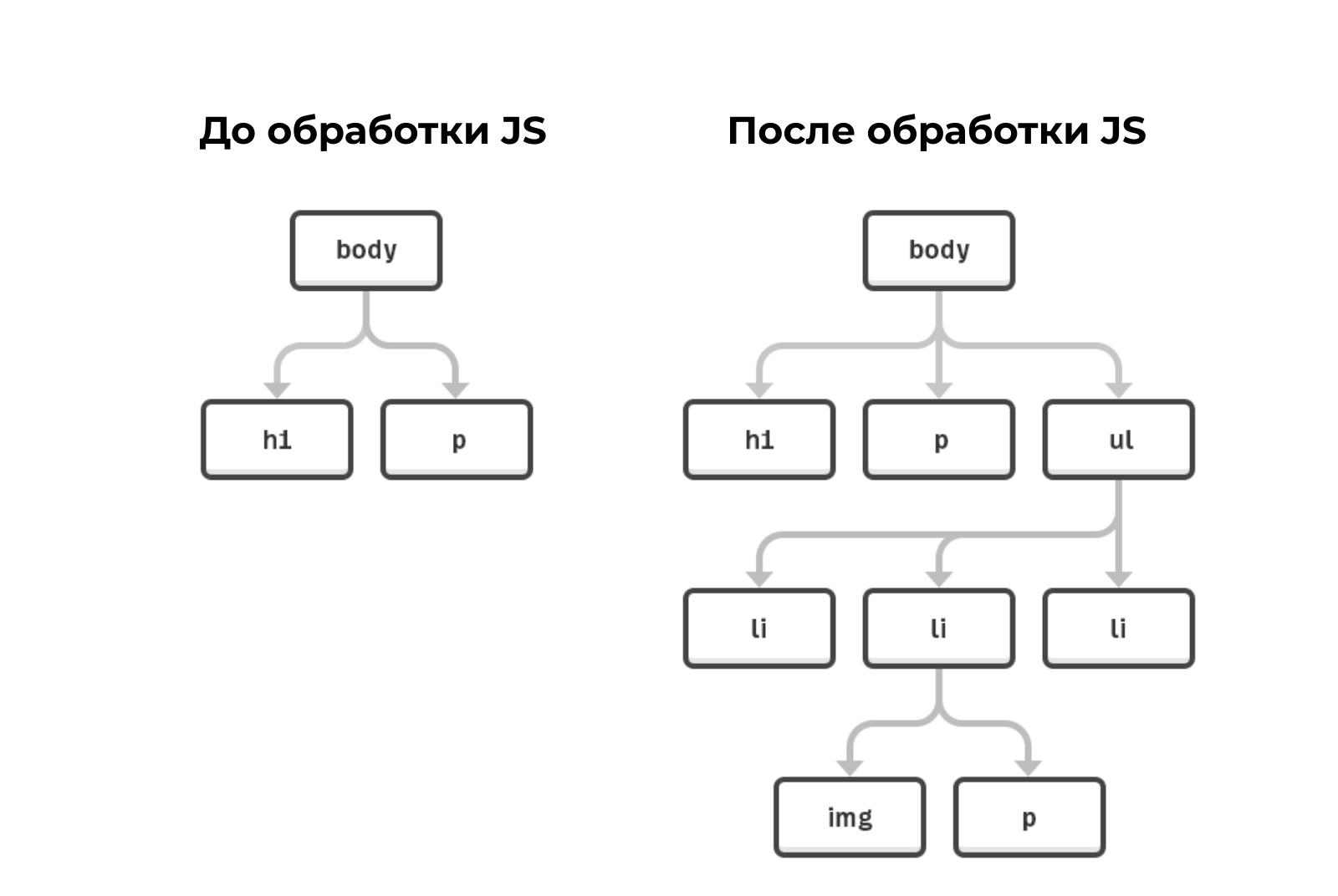
Важно знать, что JS может стать причиной появления дубликатов, если уникальный контент подгружается динамически и возникли проблемы с его отображением или загрузка занимает слишком много времени. Google может увидеть только дубликаты шаблонов. Актуально для SPA-проектов, использующих использующих фреймворки Angular, React, Vue.
Решение — SSR (server-side rendering), то есть рендеринг на стороне сервера. В таком случае Googlebot получит заранее отрисованный контент в исходном коде документа и проблем с его сканированием/индексацией не возникнет.
Также некоторые сайты могут использовать JavaScript для обработки ошибок и будут передавать код статуса 200 OK вместо соответствующего кода ошибки. Есть вероятность, что такие страницы ошибок будут индексироваться и показываться в результатах поиска.
Одно из опасений SEO-специалистов, что при двухэтапном рендеринге (сначала HTML — потом отрисовка с помощью JS) процесс сканирования может занимать много времени. На самом деле, медиана ожидания для рендеринга сканируемого HTML-документа, как правило, не превышает 5 секунд.
Показатель не стоит путать с популярным SEO-мифом о том, что рендерер Google ждёт полной отрисовки страниц всего 3-5 секунд. На деле, как уверяет Джон Мюллер, тайм-аут может быть выше, а благодаря активному кэшированию ресурсов страницам не придётся каждый раз загружать CSS- и JS-файлы.
Миф появился благодаря инструменту URL Inspection Tool от Google, в котором ресурсы необходимые для отображения страницы извлекаются в реальном времени, нет системы кэширования и требуется разумный лимит.
Тем не менее, чем быстрее отрисовывается страница, тем лучше. Процесс рендеринга тратит много ресурсов, а Google старается их экономить.
Процесс отрисовки это загрузка страницы в том же виде, который доступен в браузере пользователя. Со всеми элементами, реализованными с помощью JavaScript, если предыдущие правила соблюдены (нет запрета к сканированию, а файлы скриптов доступны и актуальны).
Googlebot работает на движке Chromium 74-й версии, поэтому поддерживает все возможности современных браузеров, но краулер не умеет выполнять пользовательские сценарии вроде кликов, заполнения форм и прочих взаимодействий с элементами на странице, поэтому всё, что должно попасть в индекс, обязано быть доступно сразу в DOM документа. Если что-то подгружается с сервера по клику, то оно не будет просканировано поисковым роботом.
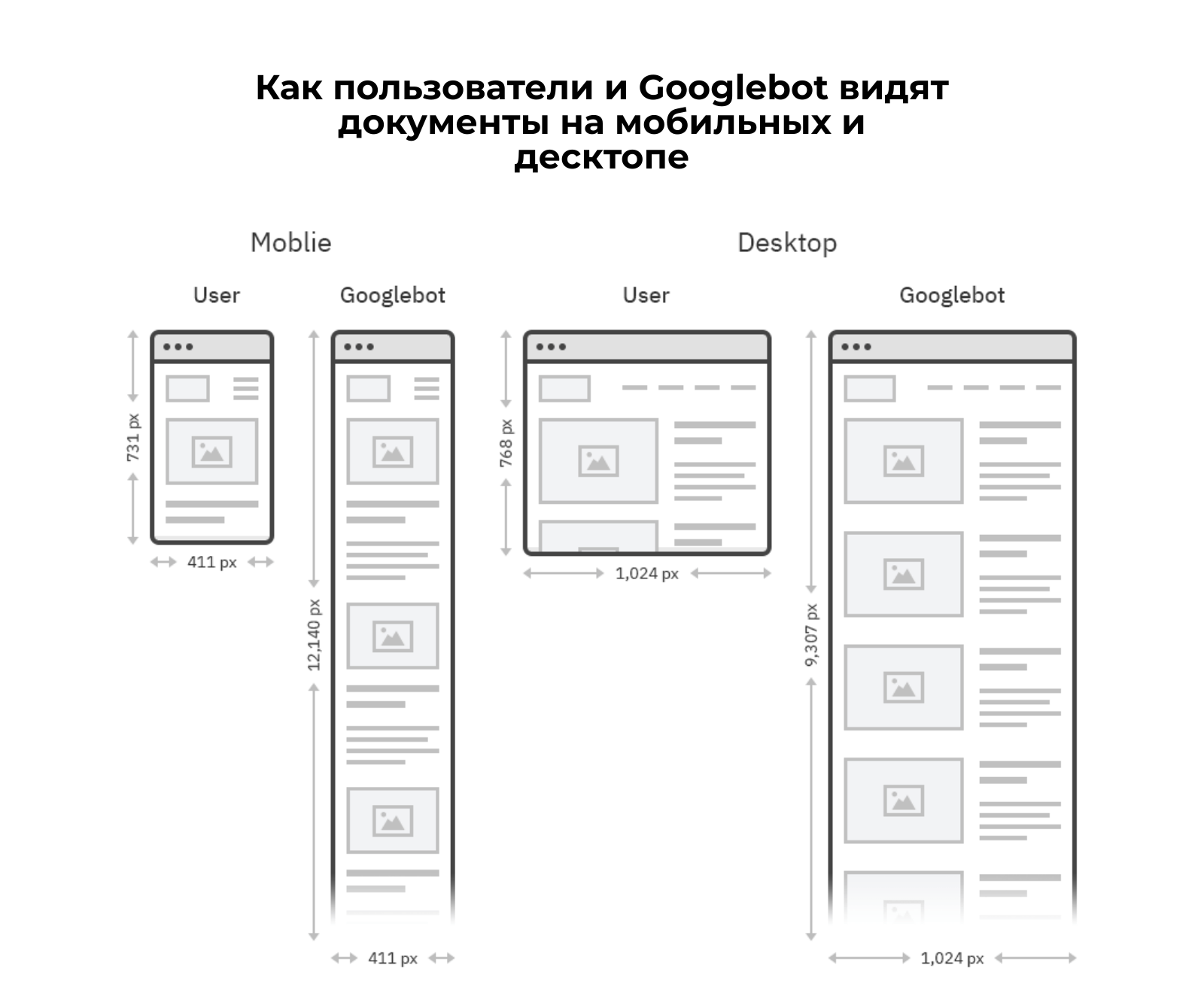
Googlebot не умеет скроллить страницу, поэтому загружаемый визуальный размер документа отличается от привычного пользователю. Для мобильных устройств страница загружается с шириной 411px и высотой 12140px, для десктопа — 1024x9307px.
Если предыдущие этапы пройдены успешно Google сможет проиндексировать контент. Самый простой способ проверить (помимо уже упомянутого URL Inspection Tool в Search Console) — ввести в поисковике часть контента, который загружается с помощью JS и, используя оператор «site:», указать анализируемый домен.
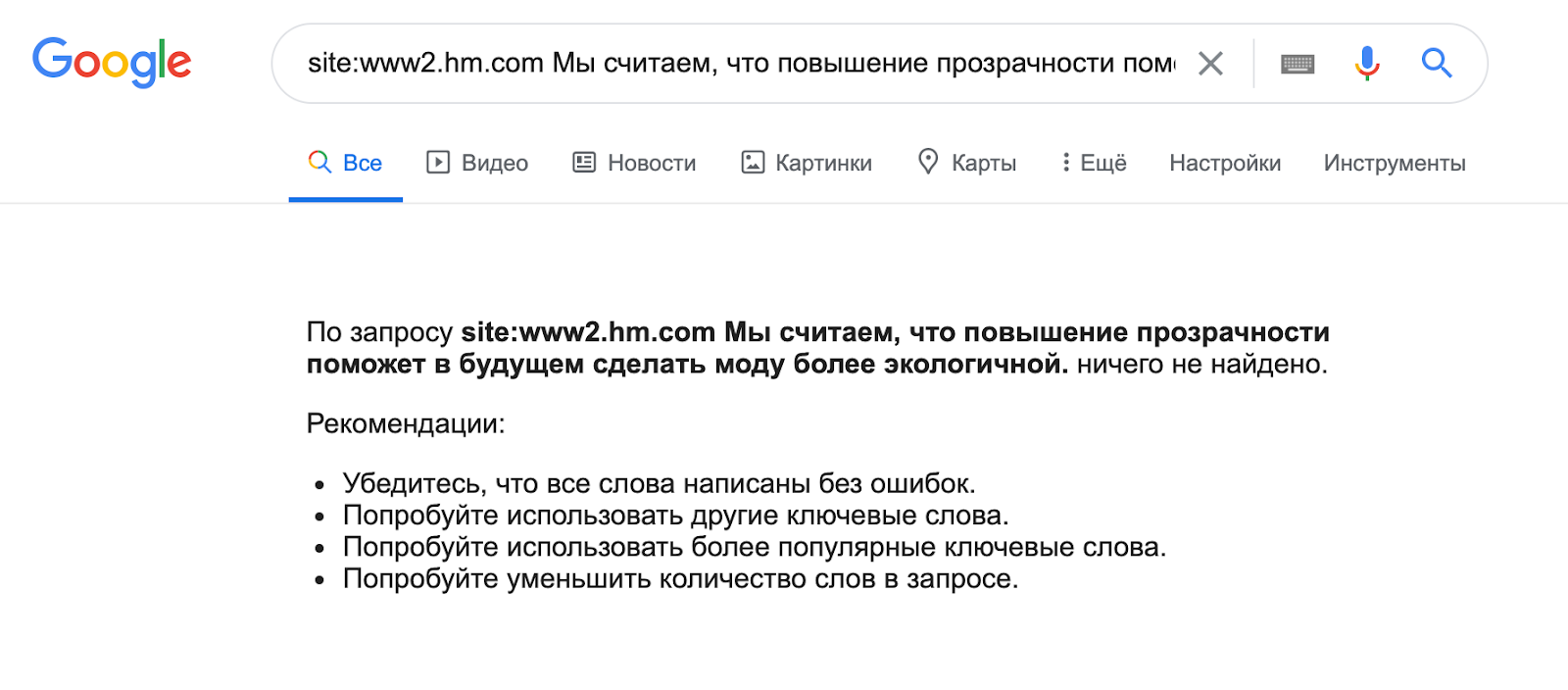
Например, на сайте бренда H&M часть контента подгружается по клику с помощью JS.
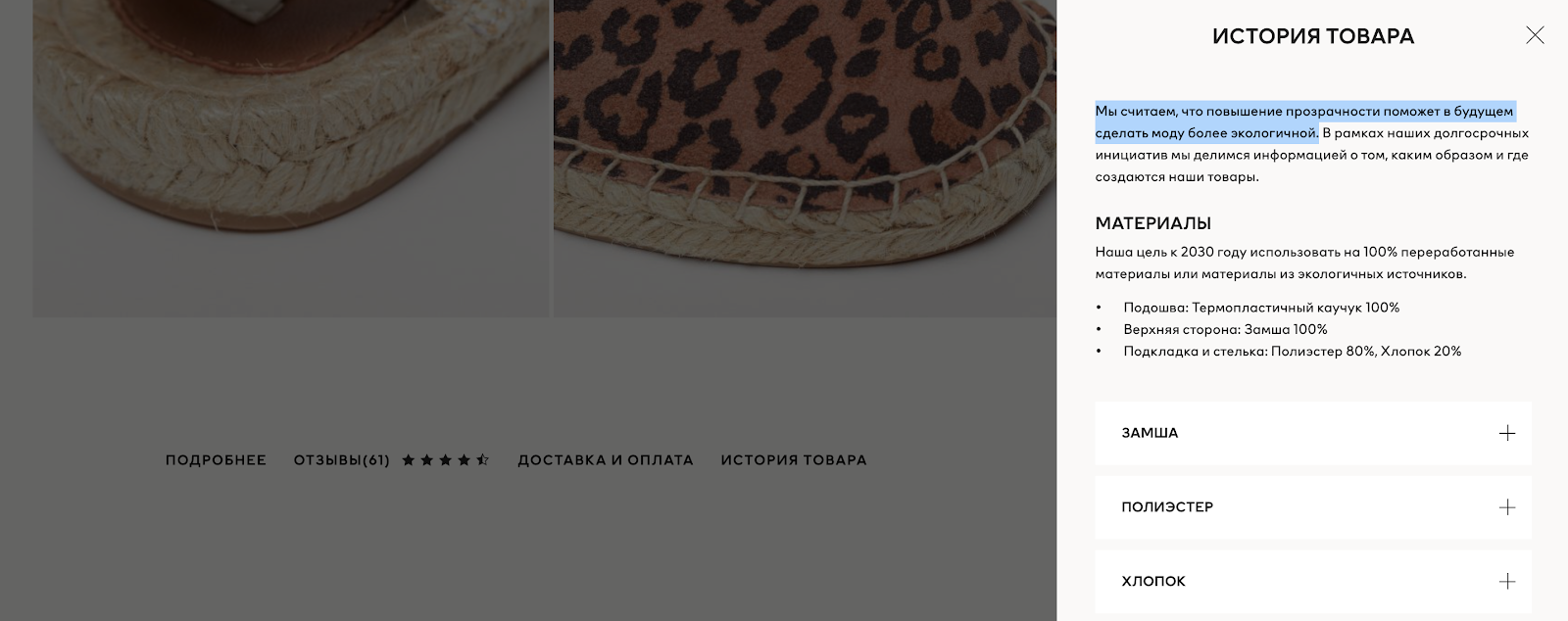
Попробуем проверить попадает ли этот текст в индекс? Увы:
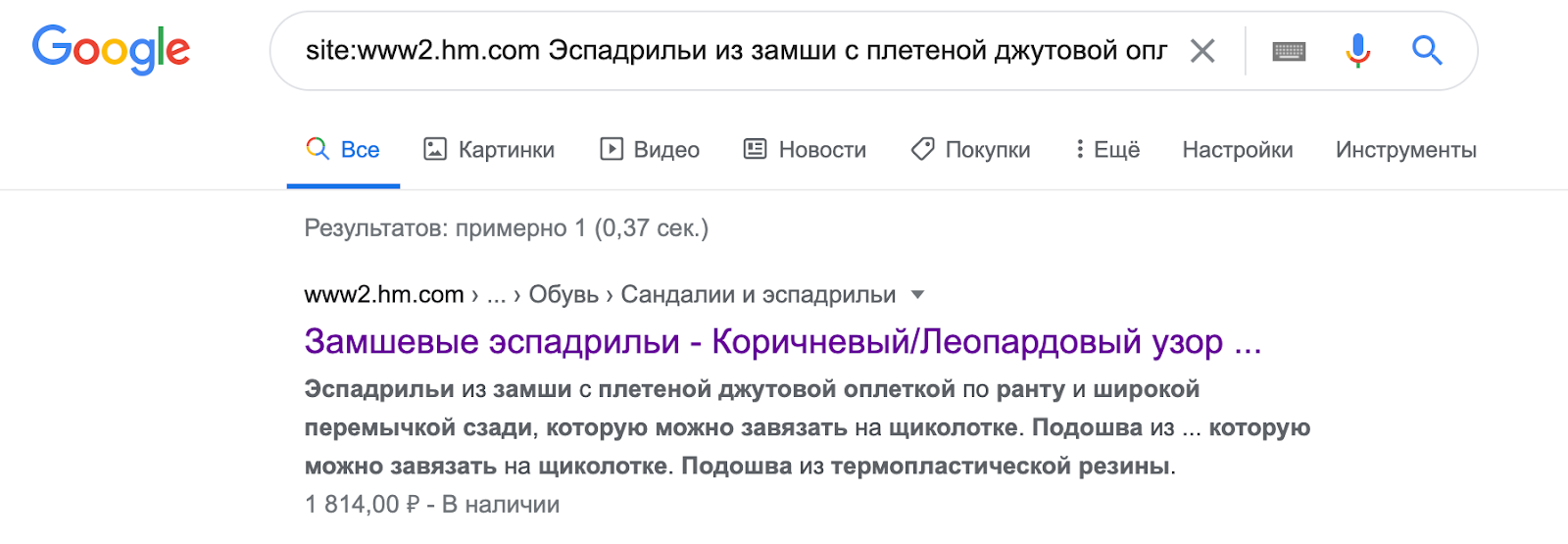
В тоже время контент реализованный в рамках HTML и найденный в исходном коде документа, без труда индексируется:

Какой процент контента на JS в итоге не индексируется? У onely.com есть суровые данные для нескольких крупных сайтов известных брендов.
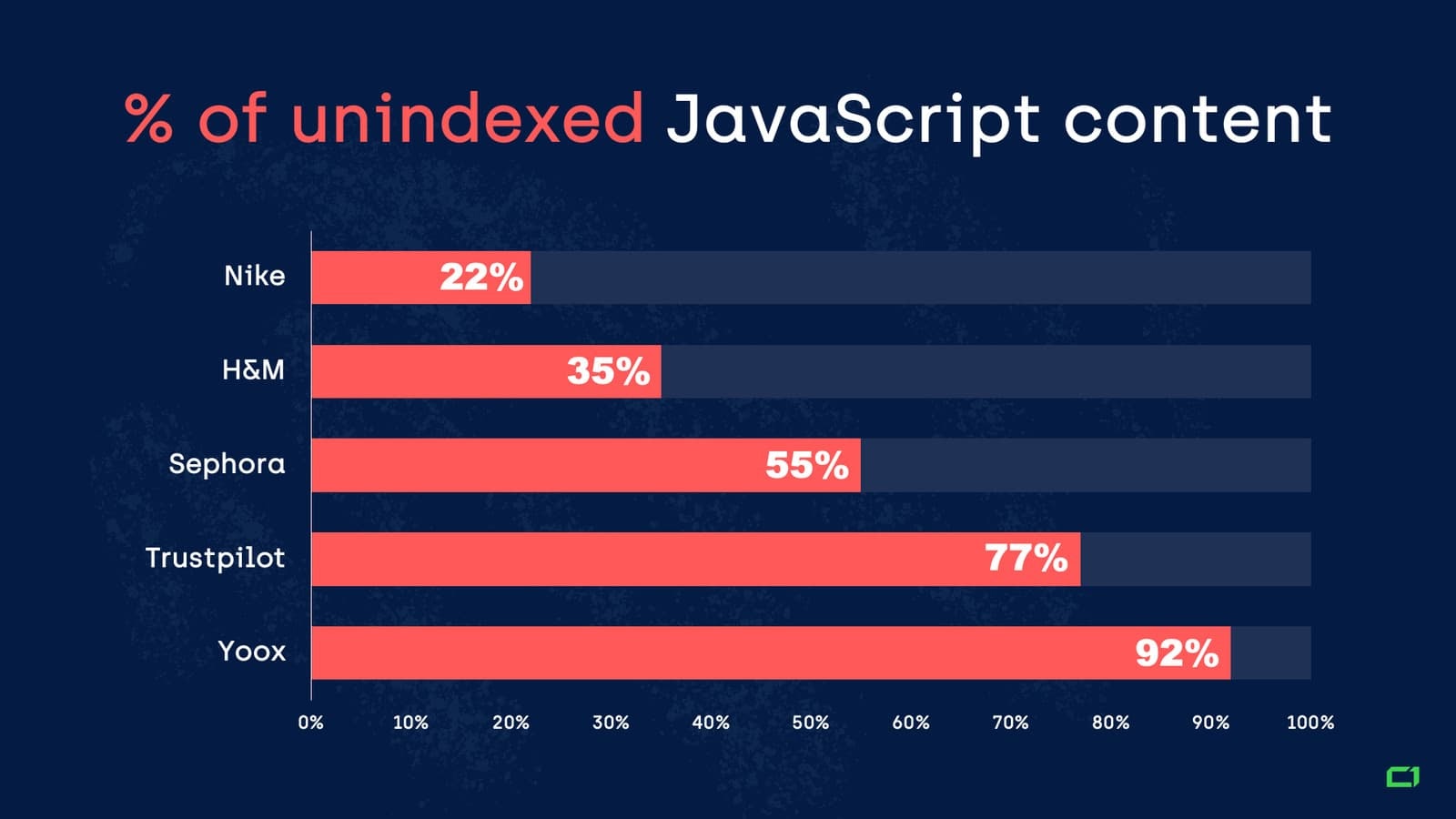
Такой разброс говорит о возможности, как минимум, облегчить доступ Googlebot и WRS к сканированию и рендерингу наших проектов. Несколько советов и рекомендаций.
Рендеринг (отрисовка) контента на стороне сервера. В этом случае, Googlebot получает уже готовый код документа. Это значительно повышается скорость First Paint и First Contentful Paint, что важно в условиях нового фактора ранжирования Google Page Experience.
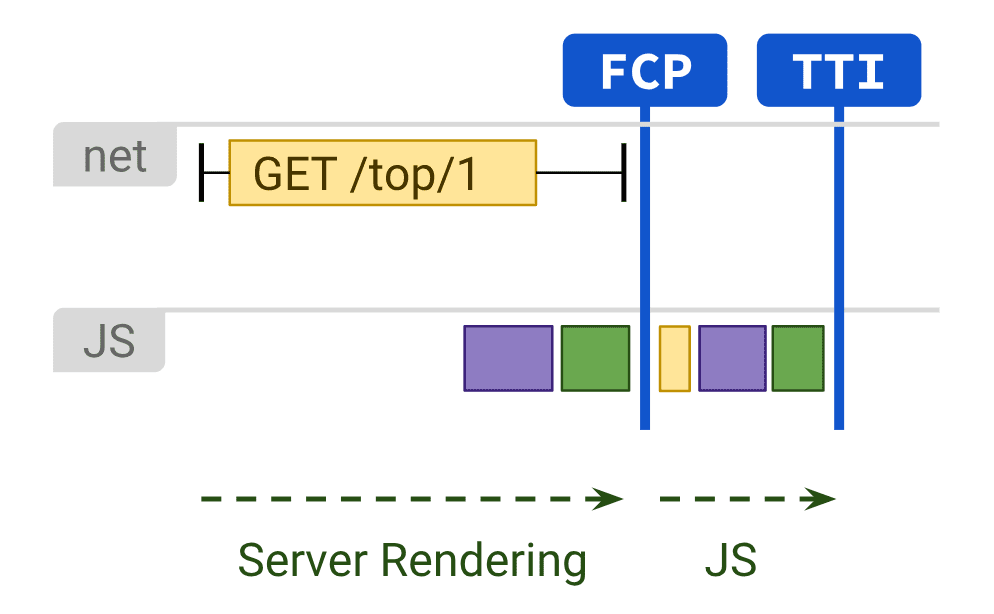
Но есть и недостаток — генерация страниц на сервере требует времени, что может привести к задержке TTFB (время до получения первого байта).
Стоит учитывать возможность и гибридного подхода — SSR для одних страниц и, например, динамический рендеринг для других. Так делает, например, Netflix.
Ещё одно жизнеспособное решение, официально поддерживаемое Google и позволяющие отправлять краулеру статическую версию сайта, а пользователям версию страницы с JS.
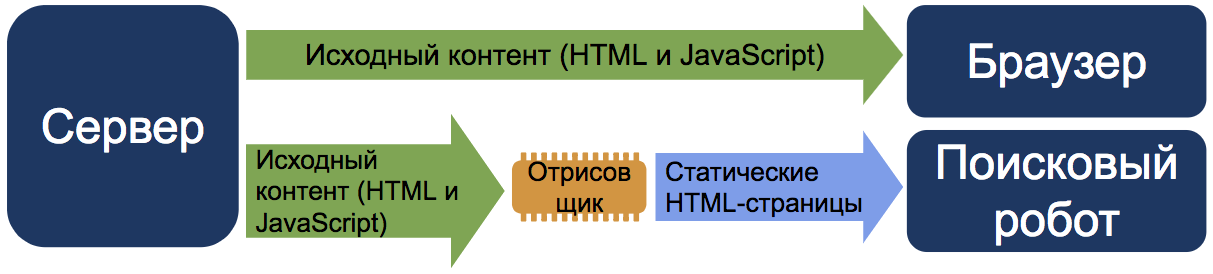
Такой способ не воспринимается как клоакинг, если контент фактически не отличается.
Динамический и серверный рендеринг важны для продвижения под Яндекс. Как увидим ниже, поисковик пока не особенно умеет в JavaScript-индексацию.
Вот список популярных JS-фреймворков + HTML5 и возможность индексации реализованного с помощью них контента различными поисковыми системами.
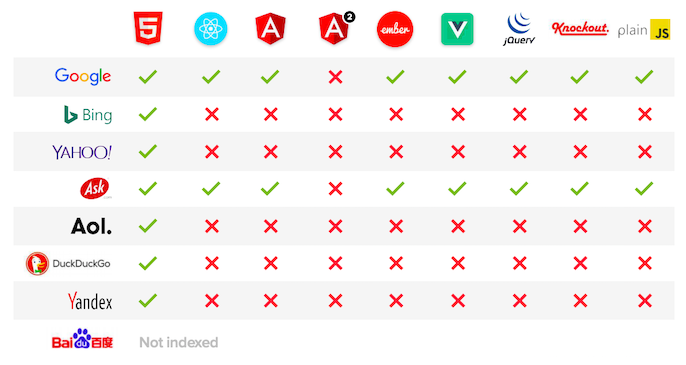
Здесь следует добавить, что робот Яндекса всё-таки может проиндексировать AJAX-версию контента, но только если есть его HTML-копия.
Очевидно, у краулеров должен быть доступ к файлам, влияющим на отображение страницы. Убедитесь, что они открыты для сканирования. Самый просто способ — добавить соответствующие директивы в robots.txt. Например, для Googlebot:
User-Agent: Googlebot
Allow: .js
Allow: .css
Подробнее о продвинутом использовании robots.txt можно узнать в нашем руководстве.
Постраничная навигация часто реализуется с помощью JS, но мы уже знаем, что Googlebot не умеет кликать на элементы интерфейса, поэтому необходимо настроить нумерацию с помощью ссылок <a href="">. Подробно о пагинации мы также рассказывали.
При взаимодействии с контентом, реализованным с помощью AJAX, Vue, Angular определенные состояния страницы могут изменять URL-адрес, добавляя в него hash-символ «#». Googlebot не сможет их распознать:

Для решения проблемы с хешами используется History API, появившийся вместе с HTML5. Метод позволяет привести URL к стандартному виду, но здесь придётся подробнее разобраться с темой и правильно настроить конфигурацию сервера. В основном это снова актуально для SPA-проектов (англ. single page application — одностраничное приложение), где контент подгружается полностью динамически.
Отложенная загрузка улучшает юзабилити сайта, подгружая медиа элементы только тогда, когда они понадобятся пользователю (например, при скролле). Но если функционал настроен неправильно, Googlebot может просто не увидеть необходимый нам контент. Если используете Lazy Loading, убедитесь, что всё загрузка реализовано в соответствии с требованиями Google.
С одной стороны система рендеринга в Google (Web Rendering Service) значительно шагнула вперёд, используя последнюю версию Chrome на движке 74-й версии, что упрощает обработку сайтов с использованием JS, с другой — краулер не умеет кликать, скроллить или иначе взаимодействовать с контентом, а значит высока вероятность, что он пропустит часть важного для SEO контента.
Если у вас нет возможности или специалиста, способного выполнять все рекомендации Google по разработке, руководствуйтесь следующим правилом: всё, что хотим видеть в индексе, должно быть доступно в исходном коде документа (теги, ссылки, тексты, изображения, навигация, меню и любые другие элементы On-page). Это максимально актуально и для Яндекса.
Всем удачно проиндексироваться и пусть в поиске будет только желаемый контент!