Распределение запросов на сайте в SEO: ошибки, методы и советы
Сегодня мы поговорим о методах кластеризации и существующих между ними отличиях. Узнаем, что делать, если кластеризация по ТОПу не работает (а на самом деле она довольно часто не работает или дает некорректные результаты, и требуется использовать какие-то другие инструменты). Обсудим частые ошибки в работе SEO-специалистов, которые допускаются при кластеризации запросов. В завершение вас ждут советы и рекомендации по теме.
Методы кластеризации поисковых запросов и их отличия
Помимо кластеризации запросов по результатам выдачи, есть и другие подходы. Первое, что использовалось — ручное, логическое разбиение и понимание того, что хочет пользователь, который набрал этот поисковый запрос, на какую конкретно страницу на сайте он хочет попасть.

Потом появилась некая автоматизация этого подхода, когда специалисты смогли уже не руками смотреть на интенты поисковых запросов, каким-то образом пытаясь угадать, что имел в виду пользователь, набравший этот поисковый запрос. Они смогли задать вопросы: каким образом поисковая система (Яндекс, Google и еще какая-то) формирует выдачу в конкретном регионе? Каким образом у нас построены результаты? Есть ли среди этих результатов по нескольким запросам одинаковые URL-адреса? И тогда, если таких URL-адресов несколько (то, что делает метод группировки из поисковых запросов кластеризация Пиксель Тулс), то мы будем ассоциировать это в некоторые кластеры, группы.
На самом деле существуют и другие подходы. Люди обучают нейронные сети, разрабатывают формулы, которые позволяют получать кластеры, опираясь на семантическую близость запросов. В частности, есть такой термин, как вес слова. Берутся наиболее «тяжелые» слова, наиболее редкие в семантике, и кластеры часто формируются исходя из них. Можно «погуглить» этот вопрос. Это отдельный и независимый подход, он на самом деле достаточно неплохо работает, имеет свои плюсы и свои минусы.
Плюсы и минусы разных подходов
-
Логическое разбиение. Мы смотрим на запросы и предполагаем, что искал пользователь.
-
Кластеризация по ТОПу.
-
Работа со сложными формулами нейронной сети и семантической близостью.

Вручную разбивать долго, и высока вероятность ошибки. Ошибки могут быть логические (мы смотрим на поисковый запрос при работе с какой-то тематикой, и нам кажется, что пользователь точно хотел купить какой-то товар, хотя на самом деле пользователь имел в виду что-то другое). Это свойство SEO-специалистов, особенно начинающих. Они пытаются «притянуть» все поисковые запросы либо запросы заказчиков.
Например, заказчик может сказать: «Я хочу в топ по запросу «краски». Но он не понимает, что именно хотят пользователи, набирающие этот поисковый запрос. Если он продает краску для волос, то вероятность того, что пользователь, набравший запрос «краски», что-то купит у него, минимальная. Это может произойти, потому что: во-первых, крайне маловероятно, что он попадет в топ, во-вторых, даже если он попадет в топ выдачи, то, возможно, окажется, что пользователь искал песни группы «Краски», строительные краски или краски для рисования. То есть это абсолютно разные потребности.
Что касается кластеризации по ТОПу: во-первых, это быстро, во-вторых, низкая вероятность ошибки. На практике, если метод кластеризации говорит, что надо продвигать в рамках одной группы, с большой долей вероятности это действительно так. Требуются определенные навыки и критическое мышление, чтобы работать с этим инструментом.
Что касается работы с ручными подобранными формулами, семантической близостью – это сложно на входе. То есть эту формулу достаточно сложно получить, оформить и каким-то образом адаптировать для вашего проекта. Необходимо все время подстраиваться под алгоритм ранжирования, но возможна высокая точность. Есть алгоритмы, у которых в итоге получается достаточно высокая точность кластеризации.
Кластеризация по выдаче (топу)
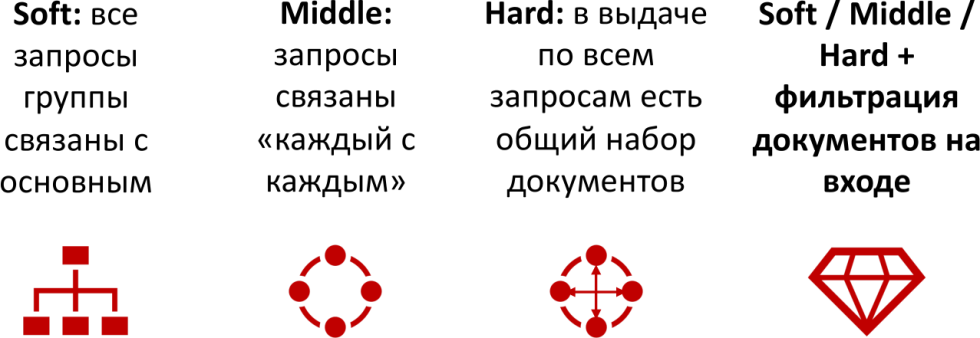
Кластеризация по ТОПу – это классический и наиболее признанный сейчас подход, который используют все. Она тоже бывает разная. Soft, middle, hard кластеризация – это три метода, в которых запросы считаются связанными друг с другом по-разному.
И еще есть комбинация: этот подход плюс фильтрация документов на входе – то, что используем мы в Пиксель Тулс, когда не просто получаем результаты выдачи и дальше сравниваем, совпадают они или вообще не совпадают, для того, чтобы поисковые запросы объединять в один кластер. Мы изначально выкидываем какой-то набор документов, исходя из того, что, скорее всего, поисковая система их либо подмешала, и они в какой-то момент времени пропадут, либо они совпадут с нашей потребностью по интенту.
К примеру, мы отсеиваем новостные примеси, примеси по спектру, Википедию и так далее. То есть такого плана документы или сайты документов, которые будут вносить больше шума, потому что вряд ли вы продвигаете вторую Википедию.
Давайте разберем три метода: soft, middle и hard, потому что наш опыт говорит, что SEO-специалисты не очень понимают, что это такое.
-
Soft означает, что есть какой-то самый популярный основной поисковый запрос, и дальше смотрится, чтобы каждый из поисковых запросов был связан с этим основным.
То есть сами по себе запросы между собой могут быть никак не связаны, и содержание выдачи по ним абсолютно неважно какое.
-
Middle – это запросы, связанные «каждый с каждым». Первый запрос связан со вторым, второй с третьим, третий с четвертым и так далее. Они образуют некое облако, но не обязательно, что все они связаны между собой. То есть необязательно, что в выдаче есть одинаковое количество документов по каждому поисковому запросу, если сравнивать его соседей.
-
Hard – это когда каждый поисковый запрос должен содержать какое-то одинаковое количество документов с каждым другим поисковым запросом. В этом случае формируются маленькие группы, но они, как правило, наиболее точные.
То есть подходы разные. В случае с «Пиксель Тулс» мы используем hard, плюс фильтрацию документов на входе.
Что такое «сила» или «степень» группировки?
«Сила» или «степень» группировки – это минимальное количество общих URL-адресов, которое должно быть по двум запросам в выдаче, чтобы они были связаны в группу. У нас есть инструмент анализа топ-10. В нем можно просто задать два поисковых запроса (например, «мебель купить Москва» и «мебель купить»), подсветить одинаковым цветом, какие у нас одинаковые URL-адреса, а какие разные, просто визуально, чтобы понять, в группу кластеризации они должны попасть или нет.

Многие SEO-специалисты до сих пор по старинке делают что-то подобное и пытаются вручную оценивать состав выдачи. Мы видим, что по этим двум поисковым запросам первый результат у нас совпадает, второй результат по запросу «мебель купить Москва» у нас находится на третьем месте в соседней выдаче, третий результат у нас тоже присутствует на седьмом месте, пятый результат – на восьмом месте и так далее.
То есть мы видим, что процент пересечений и количество запросов, которые на самом деле одинаковые по двум поисковым запросам, довольно велики, и это значит, что эти запросы должны продвигаться в рамках одного кластера.
Безусловно, такая пушка или лайфхак, когда мы просто фильтруем документы, даем до 5000 запросов на вход и получаем на выходе не только группы, но и то, каким образом поисковая система на текущий момент считает этот запрос, куда его нужно вести. То есть какой наиболее релевантный URL есть у вас на сайте на текущий момент, для того чтобы его продвигать. Плюс текущая позиция и так далее.

По сути дела, на выходе получается такой файл, где у нас есть поисковый запрос, есть общая частота, есть точная частота, есть группы, есть релевантный URL-адрес, есть количество главных и есть текущая позиция. С этим можно идти в модуль ведения проектов и загружать туда эту семантику.
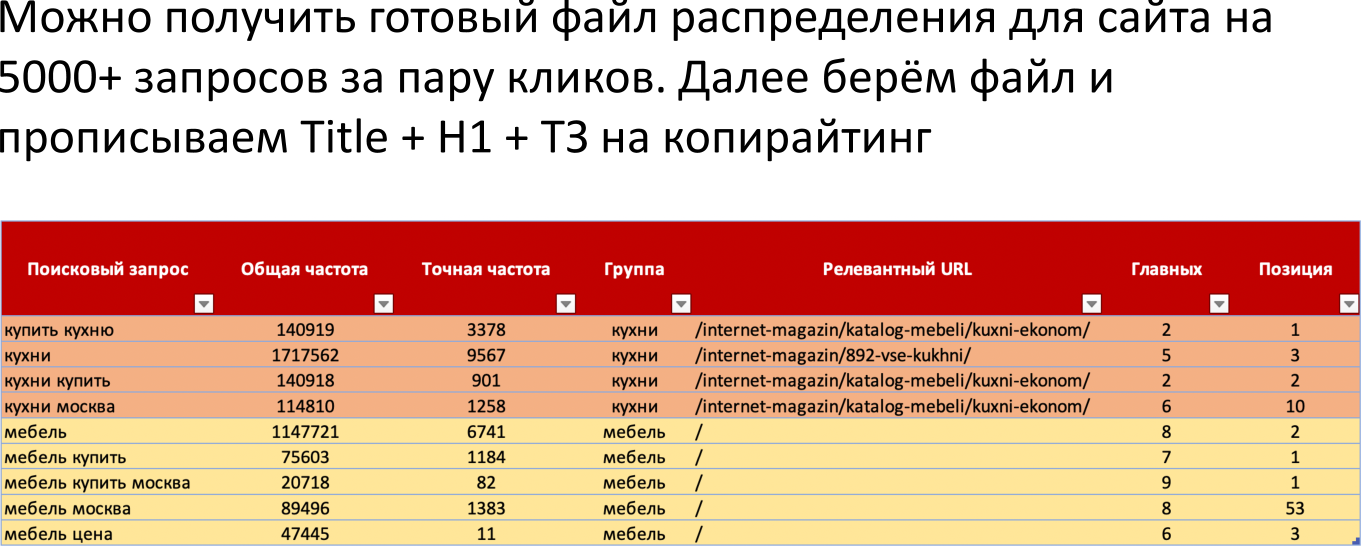
При этом мы видим определенную проблему. По идее, кластер должен быть один (группа «кухни»), но релевантный URL-адрес разный. То есть по одному из запросов («кухни») у нас не тот же URL-адрес в выдаче, что и по запросу «кухни купить».
Здесь появляется та самая проблема, о которой хотелось бы поговорить и которую многие SEO-специалисты не понимают. SEO-специалист, который может сделать грамотное распределение, составить адекватную структуру для сайта – это уже middle уровень. Если вы усвоите сегодняшнюю тему, то объективно вы будете соответствовать этому уровню. Это базовые знания, но в реальности с ними мало кто знаком.
Когда кластеризация по ТОПу не работает, и что делать в этом случае SEO-специалисту?
Даже в текущем примере кластеризация по ТОПу работает неидеально. Мы видим, что у нас здесь разные релевантные. С этим надо что-то делать.
Может ли группировка по ТОПу обманывать?
Когда группировка по ТОПу может обманывать и давать не совсем корректный результат? На самом деле ситуаций достаточно много, как минимум пять:
-
Вы неверно выявили и поставили пороги. То есть вы сказали, что нам достаточно одного одинакового адреса в выдаче по двум разным запросам, и у вас получилось, что какой-то случайный документ, например, Википедия, присутствует в топе по 300 запросам. У вас, соответственно, сформируется огромный кластер в 300 запросов, и вы думаете, что вы сейчас создадите один документ и продвинете 300 запросов. Это первая проблема.
-
Новая тематика, которая только недавно появилась. Выдачу сильно штормит, все время появляются какие-то новые статьи, новостные результаты с разных ресурсов. В этом случае, скорее всего, кластеризация по ТОПу сильно не поможет, потому что состав выдачи сильно меняется. И не факт, что он вообще релевантен потребностям пользователей. То есть интент всегда первичен.
-
У вас много микро и низкочастотных запросов и, вообще, запросов длиной 6 слов и более. В этом случае, скорее всего, у поисковой системы недостаточно данных о поведении пользователя на выдаче, качество выдачи тоже, скорее всего, низкое. Если вы кластеризуете такие вот низкочастотные «хвосты», то вам имеет смысл обращать внимание и на потребность пользователя. Иначе кластеризация будет работать для вас неидеально.
-
Довольно редкий, но интересный кейс, когда в выдаче много результатов с одного сайта. Многие кластеризаторы начинают в этот момент врать. Например, если мы собираем тематику по кредитам, и у нас содержится слово «кредит Альфа-банк» (условно), и вы хотите в топ по этому запросу, то результатов с Альфа-банка может быть достаточно для того, чтобы склеивать большое количество запросов, разных по потребности, в один кластер просто потому, что в выдаче содержится детальный ответ и несколько результатов с одного сайта. Когда такое встречается, требуется дополнительная рекластеризация, пересмотр кластеров.
-
Большое количество «примесей». В том случае, если вы не фильтруете результаты на входе, то, скорее всего, получите слишком много мелких групп (когда запросы можно было бы объединить, если бы вы почистили выдачу, и у вас было бы больше одинаковых URL-адресов в выдаче).

Вот как минимум пять кейсов, в рамках которых неидеально работает группировка по ТОПу. Поэтому, когда говорят, что сделали по группировке и дальше будут действовать исходя из нее, на самом деле это не совсем так.
Что делать в этих случаях?
-
Включать голову. Понятно, что это крайние случаи, когда группировка может сильно врать. Но даже в случае, если у вас устоявшаяся тематика, требуется включать голову и оценивать интент пользователя. Оценивать, что он хочет получить в ответ. Помните, что Пиксель Тулс дает некую технологию, а конечное решение о том, какой конкретно URL-адрес продвигать, принимать вам.
-
Менять метод и «силу». Рекомендуем «прогонять» семантику с несколькими порогами. То есть эта «сила» может быть 2, 3, 4. То есть количество одинаковых URL-адресов по разным документам, которое должно быть минимальным в топе, для того чтобы мы эти запросы сформировали в кластер. Либо даже в ряде случаев «прогонять» в другой поисковой системе.

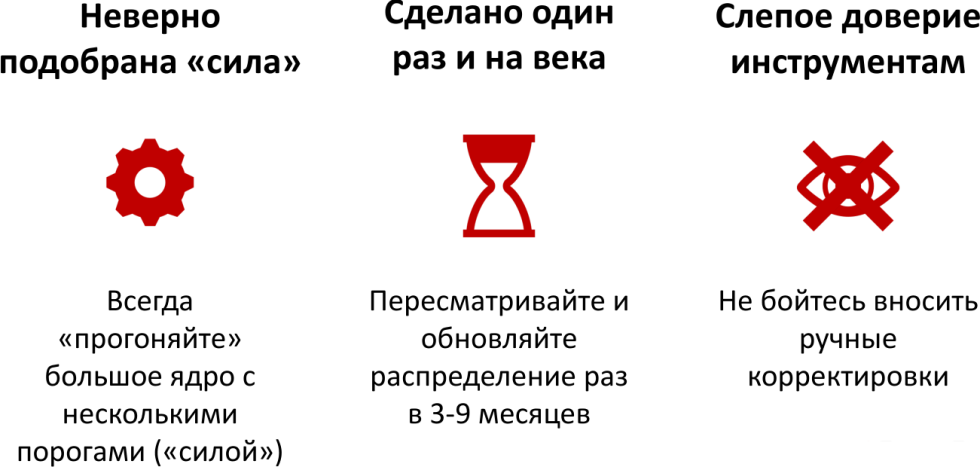
Частые ошибки в работе с кластеризаторами по ТОПу
-
Неверно подобрана «сила». Подгоняйте ее, пробуйте разные пороги. Мы кэшируем выдачу, которую получили, и вы можете переформировать выдачу по той же самой тематике достаточно быстро, буквально в течение нескольких минут.
-
Сделано один раз и «на века». Очень частая история, когда сделали семантику, сделали кластеризацию и дальше все время так будем делать. Важно пересматривать семантику, удалять запросы, которые либо не идут в топ, либо потеряли какую-либо популярность, и добавлять новые запросы, которые появляются в каждой тематике.
-
Слепое доверие инструментам. Инструмент не может знать лучше специалиста. Специалист должен менять релевантную, если ему кажется, что что-то не так.
Советы и рекомендации по распределению запросов
Всегда актуальное распределение
У нас есть вкладка «Распределение» в модуле ведения проектов. Распределение должно быть всегда актуально, продвигаемый URL-адрес должен быть выбран тот, который действительно продвигается и который вы хотите видеть в топе.
На скриншоте представлена ошибка. Мы видим, что по запросу «update яндекс выдачи» или «анализ апдейт яндекс» указана как продвигаемая главная страница Пиксель Тулс. Причем позиции достаточно неплохие, мы по всем этим запросам в топе. Но в результате файл распределения неактуален, система думает, что вы продвигаете главную страницу. Большое количество рекомендаций, которые будут касаться оптимизации главной страницы, либо будут касаться того потенциала, который есть у главной страницы или у этого тематического блока, не будут врать.
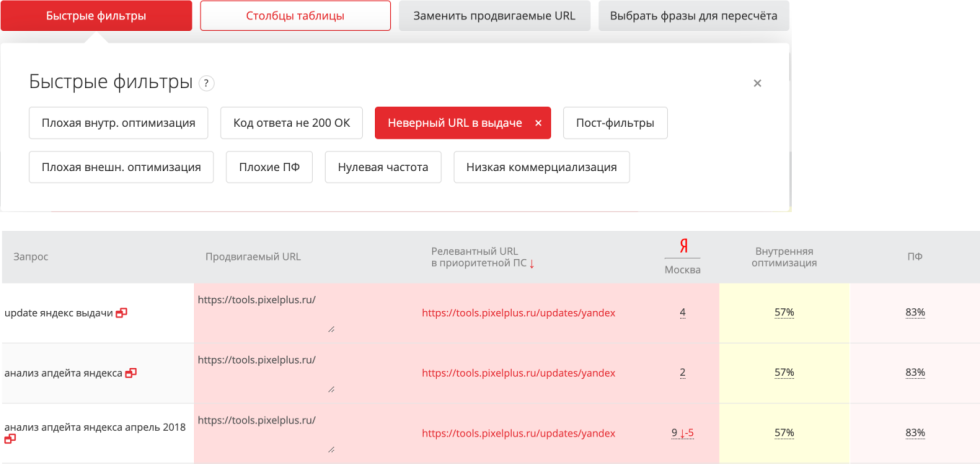
Это большая проблема. К сожалению, большинство проектов, которые обращаются к нам за помощью, не выполнили вот этот базовый шаг. Почему это действительно важно?
Актуальное распределение позволяет:
-
Автоматически оценивать качество оптимизации, находить ошибки в текстах, ПФ, ссылочной стратегии.
-
Корректно находить точки роста поискового трафика, приоритизировать URL-адреса, по которым вы хотите продвигаться, проверять гипотезы.
-
Проводить эффективную пост-апдейтную аналитику, поскольку вам важно всегда находить, какие URL-адреса просели, а какие показали рост.

Верный интент, а не только группа
Частая ошибка, когда люди доверяют группе. Инструмент что-то сказал, и мы верим этому инструменту. Есть такой инструмент у нас – проверка интентов, либо в рамках комплексной проверки работы с запросами у нас есть возможность посмотреть слова, которые часто встречаются в выдаче. Можно смотреть просто ее состав, потому что мы считаем, что поисковые системы Яндекс и Google адаптируют состав выдачи под то, что хочет видеть пользователь, и поведенческий фактор им в этом помогает. Если пользователь пытается переформулировать поисковый запрос, никуда не нажимает или уходит в Google, то очевидно, что ему что-то не понравилось. Он хочет другую выдачу, и Яндекс перемешивает эту выдачу.
Мы считаем, что если частота у поискового запроса адекватная, это не микро- или низкочастотный запрос, то выдача тоже адекватная.
Важнее, первичнее интент, то есть какой тип страницы хочет увидеть пользователь.
Если даже вы определили запросы в одну группу, очень важно дальше не ошибиться, с каким именно URL-адресом вы будете дальше продвигать. То есть вы знаете, что запрос в рамках одного URL-адреса будет продвигаться, но вопрос – какого? И очень важно понять, какой тип страниц доминирует в выдаче: инфостраница, листинг, карточка или какой-то другой тип страницы. Здесь гораздо важнее не ошибиться. Эта ошибка именно на определение типа страницы. Она более болезненная и гораздо больше наносит урона, когда вы продвигаете сайт.
Оценка и по Яндексу и по Google
У нас есть такая возможность, и мы рекомендуем хотя бы примерно «прогнать» семантику по Яндексу и по Google и посмотреть, в чем отличие. Потому что потом вы будете задаваться вопросом: «У меня хорошие позиции в Яндекс, но очень плохие в Google, что делать?» Или наоборот. И мы будем рассказывать про отличия в ранжировании поисковых систем Яндекс и Google.
На самом деле эти поисковые системы немного по-разному оценивают потребности пользователей. Рекомендуется даже (для России, Украины, Белоруссии, других западных регионов) обращать внимание на количество главных, то есть то, что мы парсим тоже в инструменте. В ряде случаев вам придется отказаться от каких-то групп запросов, по которым много главных страниц в выдаче.
То есть у вас есть семантика, предположим, 3 млн. поисковых запросов. Вы провели кластеризацию и поняли, что у вас есть 25 или 250 разных кластеров, которые не «усиживаются» в рамках одного документа и по которым количество главных страниц в выдаче 7-8 и более.
Это значит, что вам из всех 25 кластеров, которые должны вести на главную, придется выбрать какой-то один, который вы будете продвигать на своей главной странице. От остальных, скорее всего, нужно будет отказаться или дальше как-то переделывать: создавать отдельный сайт под это направление, поддомен, в том числе региональный поддомен.
То есть, если вы видите, что в вашей семантике, в целом, есть большое количество кластеров, которые подразумевают большое количество главных страниц, вам надо обратить на это внимание и переделать, возможно, ваше итоговое распределение: либо отказаться от каких-то запросов, либо добавить поддомены на сайт, либо вообще разделить семантику на несколько проектов.

Текущие позиции очень важны!
Мы провели кластеризацию поисковых запросов, и у нас есть 4 поисковых запроса: «купить кухню», «кухни», «кухни купить», «кухни Москва». Сервис говорит, что это одна группа, и ее обязательно надо продвигать в рамках одного URL-адреса. При этом мы видим, что релевантный URL у нас на сайте разный по этим поисковым запросам, и позиции этого сайта все в топе. Вопрос: надо переделывать всю оптимизацию? Кстати, так реально делают SEO-специалисты: вот сервис сказал, что надо в рамках одной группы, будем переделывать.
Нет, запрос «кухни» у вас в топ-3 по Яндексу по Москве. Отцепите этот запрос от кластера, то есть поменяйте просто файл и загрузите его отдельно как ВЧ. На самом деле это в ряде случаев помогает: во-первых, определиться с тем URL-адресом, который нам в реальности надо продвигать, а во-вторых, несколько разгрузить большие группы.
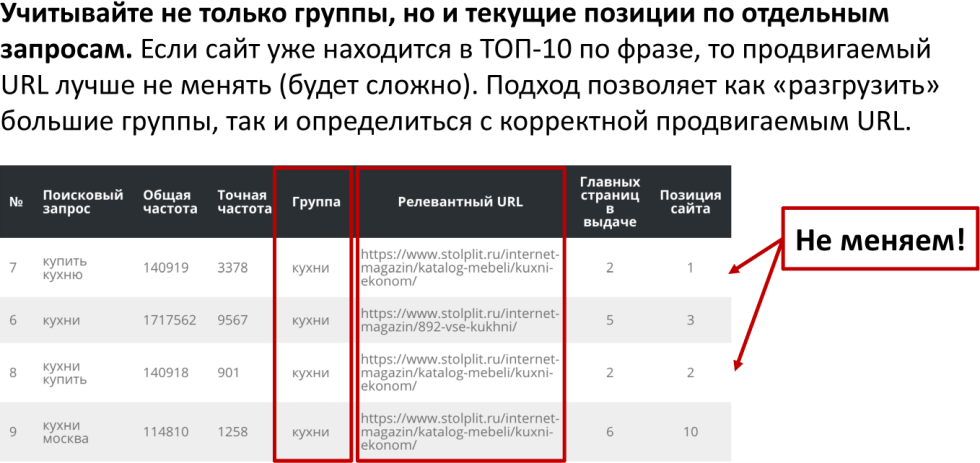
Если мы посмотрим всю семантику коммерческих СЧ запросов типа «купить кухни», «кухни Москва» и так далее, то их будет много. Несколько десятков поисковых запросов, скорее всего, попадет в одну группу. И их действительно надо продвигать на одной странице. Так вот, разгрузить эти большие группы, помочь вам дальше с ними работать может этот прием. Когда вы текущие позиции не трогаете, поисковый запрос ранжируется в топе, и пусть он дальше там ранжируется.
Сначала шаблоны, потом руки
Помните, что сначала шаблоны (типовые страницы) и только потом руки. По запросу «кресла site:stolplit.ru» есть несколько десятков тысяч этих кресел. Очевидно, что даже после кластеризации поисковых запросов вам нужно в первую очередь вносить изменения в шаблонную оптимизацию и думать, каким образом вам шаблоном удовлетворить потребность пользователя, а не руками.
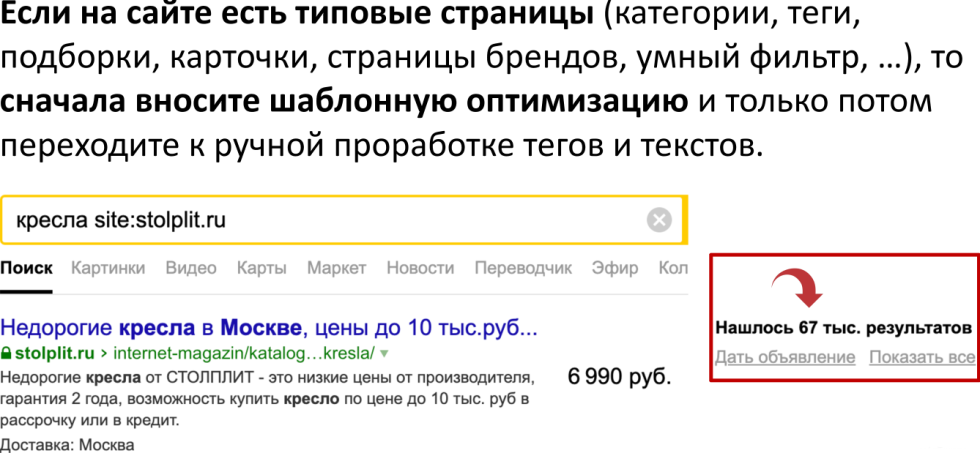
Вручную мы действуем только в тот момент, когда шаблоны у нас хорошие, когда мы понимаем, что они отрабатывают достаточно хорошо, когда показатели видимости по категории у нас хотя бы 5-7%. То есть мы видим, что охватываем хотя бы 5-7% потенциального трафика. Скорее всего, шаблон здесь нормально отрабатывает, мы дальше двигаемся уже к ручной проработке.
Это все советы и приемы на сегодня. Для нас важно получать от вас небольшой фидбэк. Обязательно пройдите небольшой опрос – 8 вопросов с вариантами ответов.
Вопросы для сертификации:
-
В каких случаях метод кластеризации по ТОПу не работает (не дает корректный результат)?
-
Чем метод кластеризации soft отличается от middle?
-
Требуется ли учитывать текущие позиции сайта и релевантные URL в выдаче по отдельным фразам при кластеризации или следует распределять запросы строго в один кластер?
Мы даем технологию. Ваша задача – действовать, брать и делать. Действуйте быстро, будьте первыми, осваивайте новые возможности Пиксель Тулс, которые мы предоставляем. Мы всегда рады поделиться теми знаниями, которые у нас есть.
Ответы на вопросы
Есть ли смысл анализировать запросы, если их больше 1-3 миллионов?
Ответ: С нашим инструментарием, наверное, будет сложно на входе. Там нужно вначале каким-то образом разбить по тематикам и произвести чистку. Более того, всегда надо думать о том, что делать дальше. То есть мы работаем с 1 миллионом поисковых запросов. Какая конечная цель? Какие метрики мы хотим отслеживать?
Сложно работать с 40 тысячами поисковых запросов, а тут их миллион.
Ответ: Да, действительно, сегментировать 1 миллион достаточно сложно. Здесь какие-то десктопные решения, которые тоже работают с вашей оперативной памятью. Они могут «подтупливать», поэтому изначально рекомендуется действовать исходя из тематики. Грубо говоря, мы берем большой пирог – 1 млн. поисковых запросов – разрезаем его на 10 частей по тематикам. Дальше мы уже нарезаем его более мелко, какими-то кластерами, и так далее.
Если это тоже сложно, то определяйте и кластеризуйте их либо по наборам частот, либо по потребностям пользователей, то есть это типы страниц выдачи. Если это карточный спрос, то его отдельно, листинги отдельно и так далее. Дальше уже работайте с этими листингами.
Без конкретных примеров не очень понятно, чем отличается soft от middle и hard.
Ответ: Middle – это история, которая говорит нам о том, что поисковые запросы должны быть связаны «каждый с каждым». Первый со вторым должны иметь какой-то одинаковый набор документов. Второй – с третьим. Третий – с четвертым. Но при этом первый с третьим, допустим, не имеют друг с другом одинаковых документов в выдаче. Таким образом у вас формируется довольно большой кластер, который как бы по цепочке зацепляет поисковые запросы.
Soft говорит о том, что у нас есть некий локомотивный запрос, и к нему привязываются все остальные запросы.
Hard говорит о том, что каждый поисковый запрос обязательно имеет с другим поисковым запросом общие документы.
Как группировать ключи для информационных сайтов? Насколько большим должно быть количество ключей на статью?
Ответ: Для информационных сайтов мы рекомендуем использовать либо soft-кластеризацию, либо middle. Это те подходы, которые дают лучший результат. Почему? Запросов много, очевидно, что вы не будете прорабатывать их вручную. Даже если 10 запросов у вас появится – это сотни тысяч документов. Вам нужно сделать меньшее количество документов на большее количество запросов.
В ряде случаев это оправдано, потому что при работе с информационными сайтами требования к текстовой оптимизации совсем другие. Часто в выдаче важно, чтобы свежесть была и так далее. То есть вы берете довольно большой кластер, используете soft и middle, это может быть несколько десятков или сотен поисковых запросов, после чего формируете некоторые топовые поисковые запросы. Это может быть топ-5 поисковых запросов по частоте, которые вы даете редактору или копирайтеру для того, чтобы они максимально приближенно к этому виду встречались в статье.
Дальше от всех остальных поисковых запросов есть так называемые «хвосты» – дополнительные слова, которые содержатся в поисковых запросах и которые также может употреблять копирайтер или редактор.
Вы создаете оптимальную структуру, выделяете маркерные ключи и контролируете их. Остальные новые запросы будут «притягиваться», если вы с маркерами нормально поработали. Прав ли я?
Ответ: В целом, вы больше правы, чем нет. Если вы изначально проработали грамотно семантику, то действительно эти маркерные поисковые запросы будут создавать общий каркас, а дальше вы будете «притягивать» какие-то новые потребности к этим страницам и типам страниц, которые есть.
Но, к сожалению, так бывает очень редко. Как правило, оптимизированная структура в момент создания сайта – это один из 500 или 1000 кейсов, даже еще реже. Как правило, происходит по-другому: пришел сайт, и нам нужно что-то с этим делать.
Мы должны определить, каких типов страниц не хватает. В этом случае мы заново проводим всю эту работу, часто бывает, что в рамках текущей структуры, но требуется досоздать разделы, подразделы или создать новые типы страниц, в частности, маркерные, теговые страницы и так далее.
Чем лучше ваш кластеризатор по сравнению с другими?
Ответ: Наш кластеризатор лучше тем, что он, во-первых, находится в рамках комплексных инструментов, и вы можете сделать не только кластеризацию, но и проанализировать выдачу по другим параметрам: https://tools.pixelplus.ru/tools/complex-queries-analyser. Во-вторых, он отсеивает спектральные примеси и дополнительные примеси, которые часто анализируют другие кластеризаторы и дают из-за этого менее качественные группы.
Мы увидели, что кластеры распределены неправильно. Что дальше? Особенно интересно на вашем примере с апдейтами Яндекса.
Ответ: В этом случае нужно переделать структуру, «загнать» правильную и переделать оптимизацию. К сожалению, часто действуют вообще по-другому. Мы сделали какую-то оптимизацию, какую-то семантику по тому распределению, которое было. Потом мы поняли, что у нас видимость сайта по набору поисковых запросов 2% или 0,5 %. Мы подумали и поняли, что распределение было сделано неправильно. То есть вообще вся работа, которая была сделана до этого, вся насмарку. Поэтому только переделывать.
Какая оптимальная «сила» для среднего сайта?
Ответ: Если отвечать прямо в лоб, то 3. Большинство оптимизаторов используют 3-4. Дефолтное значение в наших инструментах тоже 3.
Инструменты и вспомогательные ссылки
Запись вебинара
Чтобы не пропускать новые материалы, подписывайтесь на наши группу ВКонтакте, чат Telegram и канал YouTube.
Вопросы и ответы
Как узнать самые популярные запросы в поисковиках?
Для этого нужно собрать семантическое ядро — ключевые слова, которые характеризуют сайт, и их статистику. Чем выше частотность ключевого слова, тем оно популярнее. Статистику можно собрать через Яндекс.Wordstat, это бесплатный, но не очень удобный сервис. Проще и быстрее парсить частотность через наш инструмент «Получение данных из Яндекс.Вордстат».
Какие бывают виды поисковых запросов?
Запросы классифицируются по частотности (ВЧ, СЧ, НЧ), уровню конкуренции (высоко- и низкоконкурентные), геозависимости (геозависимые и геонезависимые), потребности пользователя — интенту (навигационные, транзакционные, мультимедийные и др.) По ссылке читайте подробную статью о классификации поисковых запросов.
Как уточнять поисковые запросы?
Чтобы получать более точные результаты в Яндексе или Google, можно использовать в запросах операторы — специальные символы или слова. Полный список поисковых операторов Google — по ссылке. В Яндекс.Wordstat и в нашем инструменте «Получение данных из Яндекс.Вордстат» тоже можно использовать операторы для уточнения запроса.
Как правильно подобрать поисковые запросы?
Поисковые запросы должны описывать содержимое сайта (например, товары), соответствовать интенту (например, «купить товар»), иметь ненулевую частотность. Чтобы автоматически подбирать запросы, отслеживать позиции, оценивать конкуренцию, получать рекомендации по оптимизации, заведите проект в нашем Модуле ведения проектов.

Рейтинг статьи:
По оценкам 48 пользователей

Другие материалы